Noc arbitration method based on global node information in gpgpu
An arbitration method and global node technology, applied in the field of NoC arbitration based on global node information, can solve the problems of ignoring the role of the arbitration mechanism to improve system performance, replying to high network load, mutual interference, etc., to speed up the task processing process and reduce the system Pause time, the effect of improving overall performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0036] The present invention will be further described below in conjunction with the accompanying drawings and specific preferred embodiments, but the protection scope of the present invention is not limited thereby.
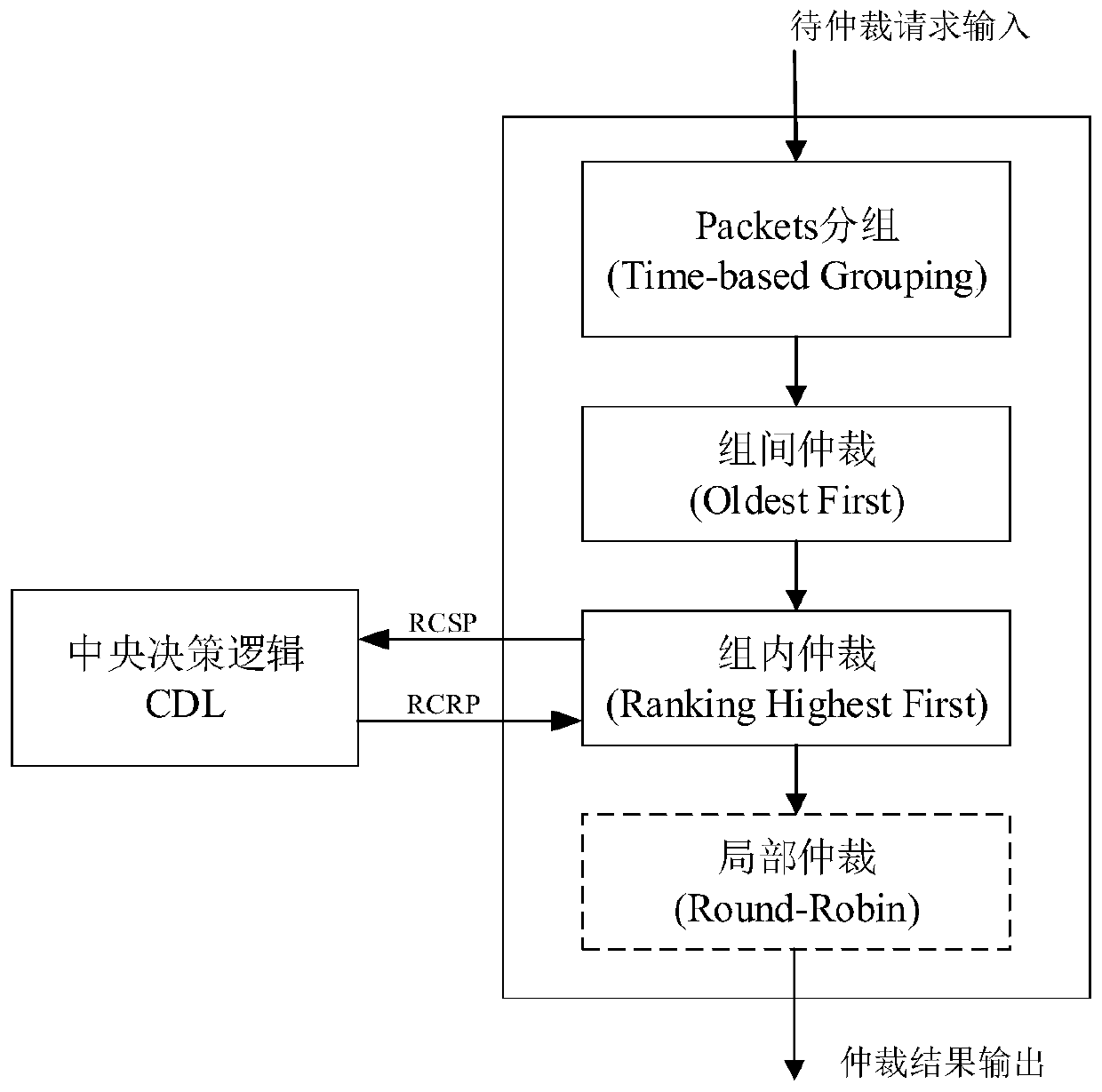
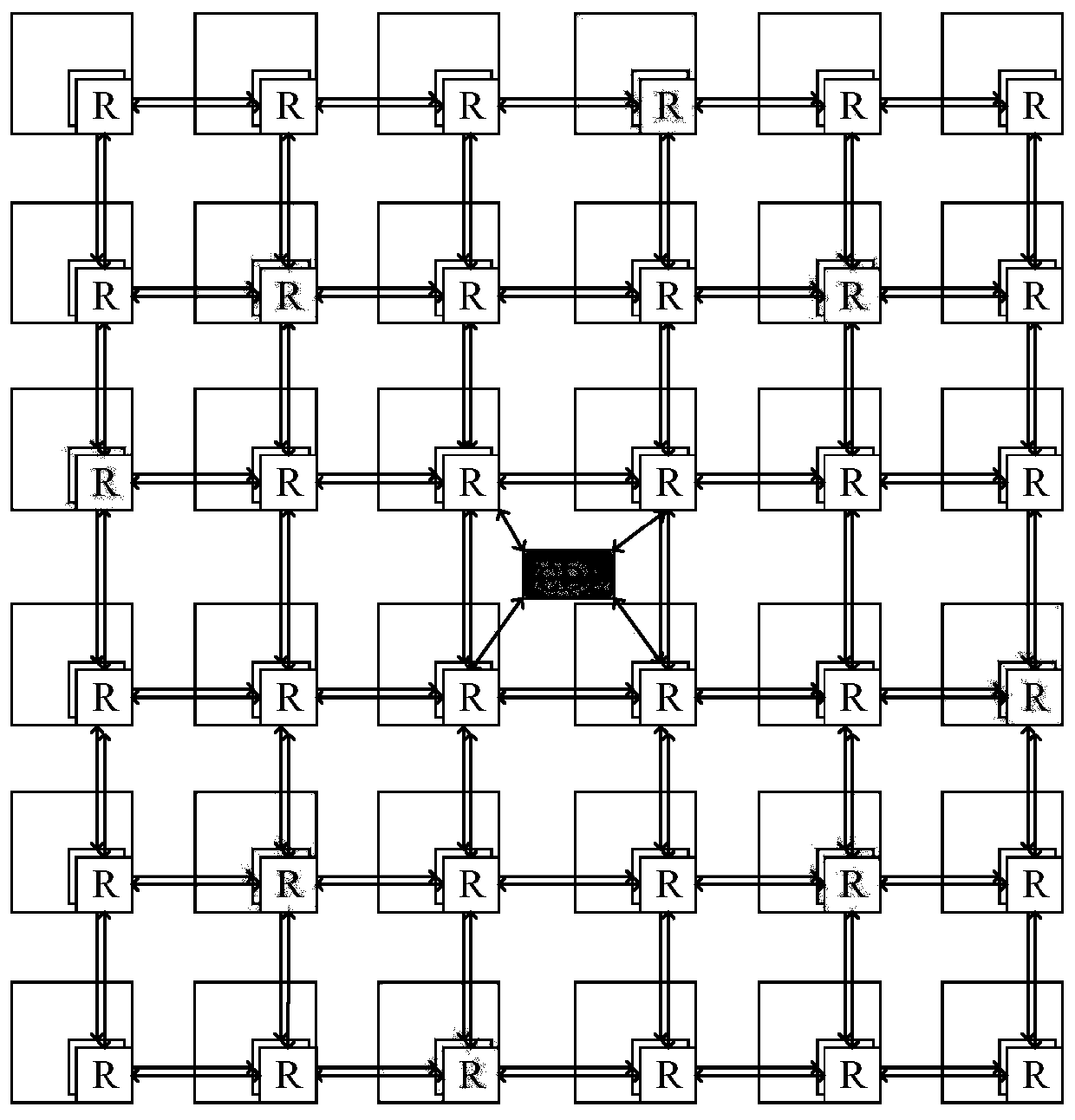
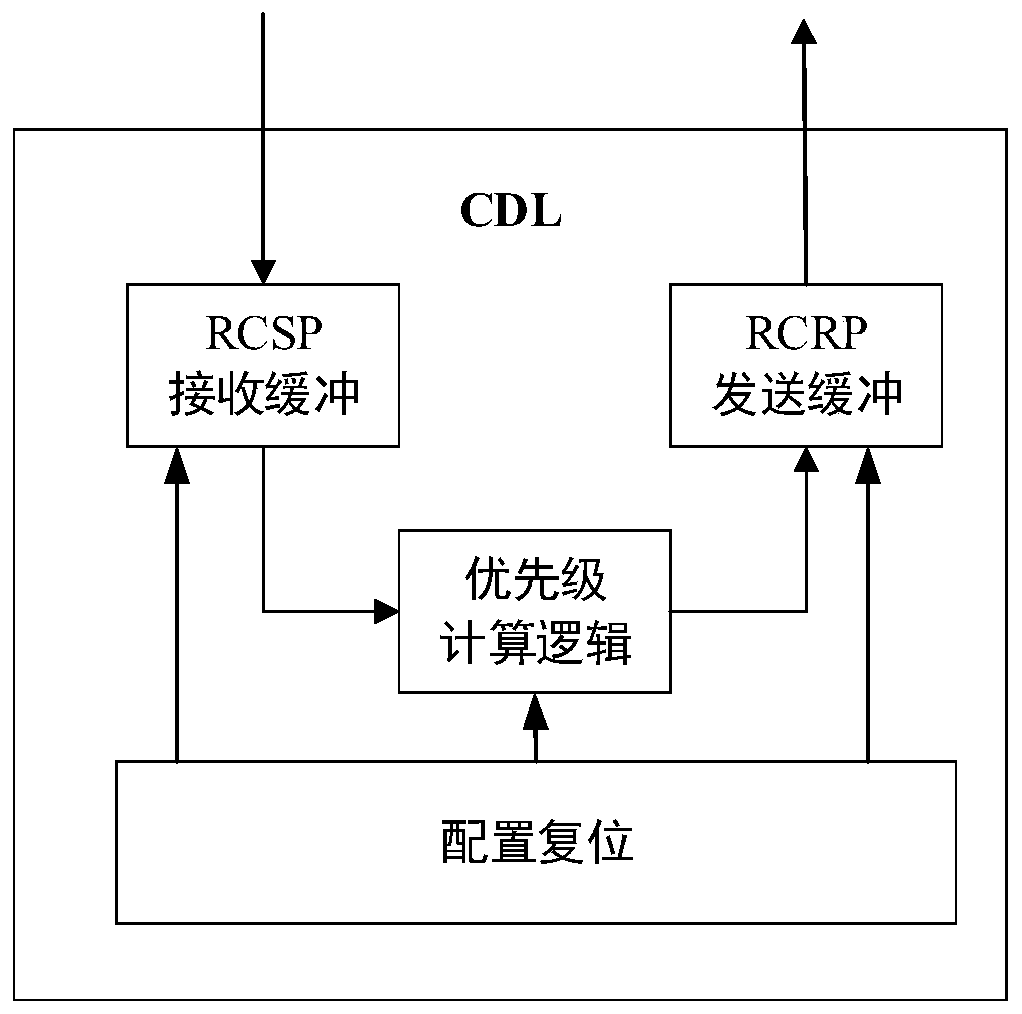
[0037] Such as figure 1 As shown, the NoC arbitration method based on global node information in the GPGPU of this embodiment, the steps include:
[0038] S1. Collect the performance information of each computing node in the network, and set the priority of each computing node according to the performance information, which is also the priority of the data packet (packet) sent by the computing node, and broadcast to all computing nodes for global Synchronization Update;
[0039] S2. When the computing node sends a memory access request, group the data packets that need to be injected into the network in each computing node, and obtain the grouping information of the data packet; According to the priority of the computing node, the winning group in the inter-gr...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com