Data space multi-dimension indexing method based on load balance and query log
A load balancing and data space technology, applied in electrical digital data processing, special data processing applications, instruments, etc., can solve the problem of high cost of hard disk I/O overhead, inability to efficiently support large-scale data query processing, and inability to load indexes in memory Problems such as graphs to achieve the effect of minimizing communication overhead
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach 1
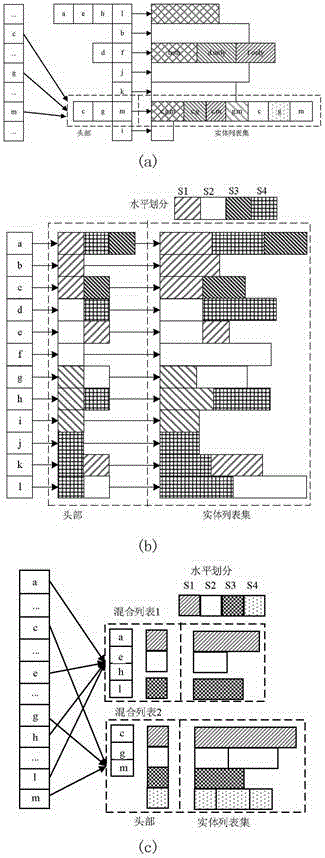
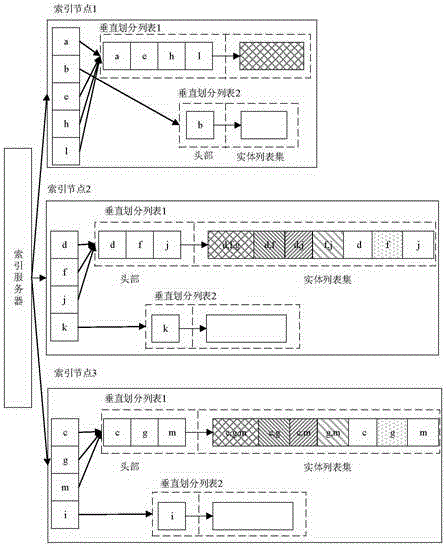
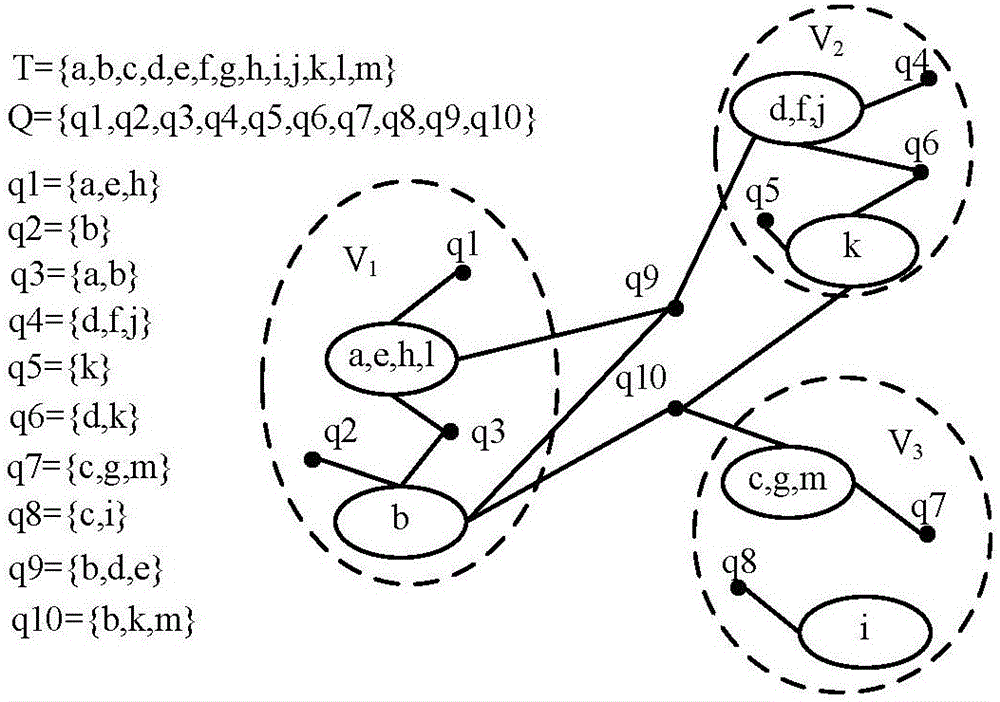
[0068] Specific implementation mode one: as figure 1 As shown, the implementation of the load balancing and query log-based data space multidimensional indexing method is described in detail in this embodiment as follows:
[0069] 1. In order to successfully extend the inverted index into the data space, the attribute labels and attribute values are aggregated and coded into token words:
[0070] Define Token. For an attribute-value pair (a, v), its corresponding token is defined as t=v / / a.
[0071] Essentially, an entity is often composed of a set of attribute-value pairs (note that the content can be regarded as an attribute-value pair). In other words, an entity is actually a vector of tokens (t 1 ,t 2 ,...,t |D| ), where D represents all the different token identifiers in the data space.
[0072] Define entity vector, an entity vector is defined as o=(w 1 ,w 2 ,...,w |D| ), where w i Indicates the token word t i the weight of.
[0073] The partition-based data...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com