An xml big data clustering integration method for parallel AP propagation
An integrated method and big data technology, applied in the direction of electrical digital data processing, special data processing applications, semi-structured data query, etc., can solve the problems of data noise, many isolated points, fast generation speed, and huge volume, etc., to eliminate Effects on ambiguity puzzles, widening differences, and improving performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


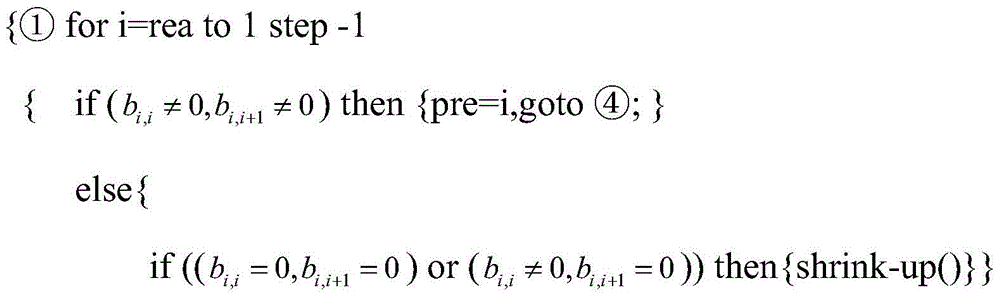
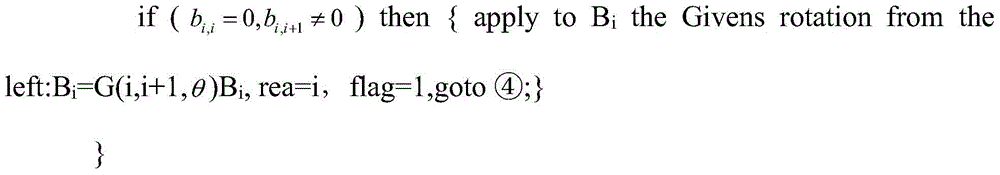
Examples
Embodiment 1
[0035] Step 1: Perform preprocessing such as cleaning, dividing and extracting for each XML big data, that is, after cleaning each XML big data, extract all nodes and their nodes from the big data through the division method combining scale and content Subset, calculate the frequency of the subset of nodes in its data, divide the nodes and their descendants belonging to the same subject content into the same subset as much as possible according to the frequency of nodes, and divide the nodes of different subject content into different sub-sets. and extract n subtrees from the divided subset according to the frequency of keywords, find all the paths from the root node to the leaf nodes of each extracted subtree, and use the path as the input source for disambiguation to resolve ambiguity Words are disambiguated, and the semantic relevance and context semantic similarity of each keyword are obtained;
[0036] Its similarity is obtained as follows: Assume that n subtree sets D'=(...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com