Natural language lexical analysis method, device and analyzer training method
A lexical analyzer and natural language technology, applied in the field of natural language lexical analyzer training, natural language lexical analysis method, and device field, which can solve the problems of unrecognized, blindly recognized unknown words, and inability to obtain new words composed of words. , to avoid interfering information and improve accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
no. 1 approach
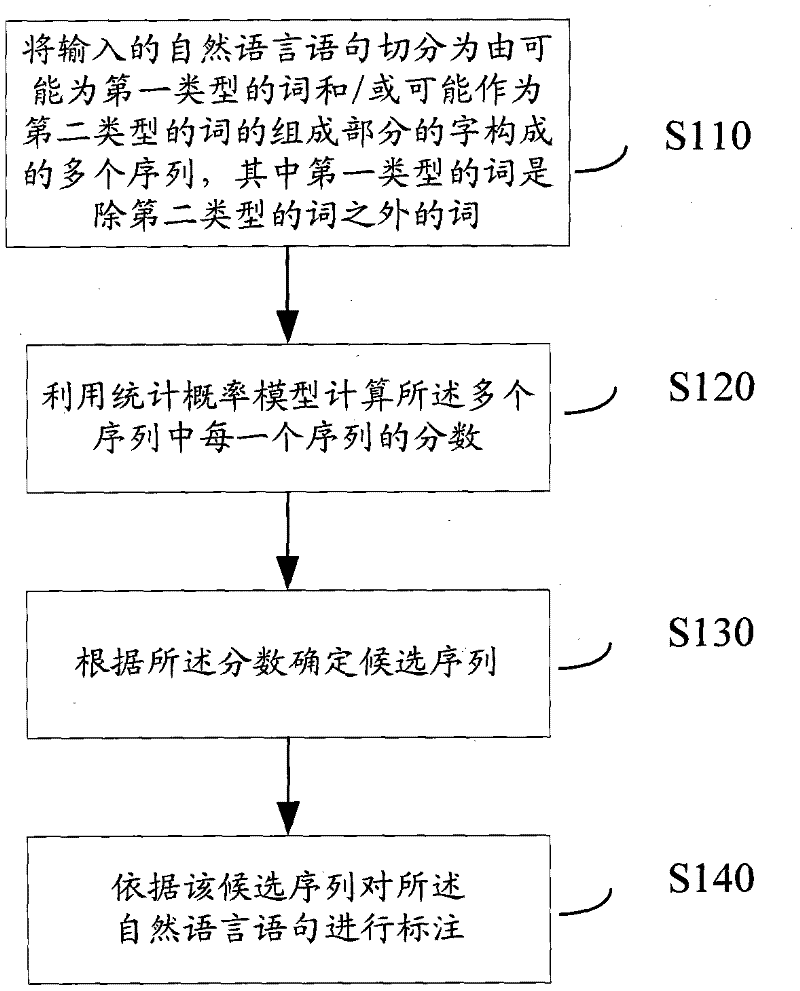
[0025] According to the first embodiment of the present invention, a natural language lexical analysis method is proposed. figure 1 A schematic flowchart of the method is shown.
[0026] Such as figure 1As shown, in step S110, the input natural language sentence is segmented into a plurality of sequences composed of words that may be words of the first type and / or words that may be components of words of the second type. Here, Chinese is taken as an example for description. It should be noted that the embodiments of the present invention only use Chinese as an illustrative example, but the present invention is not limited thereto. Those skilled in the art can also apply to natural languages such as Japanese and Korean.
[0027] The reason why we say "possibly the first type of word" means to temporarily treat it as "the first type of word", but in the final word segmentation result, it may not be a legal word, or it may not be the first type word. "A character that may ...
no. 2 approach
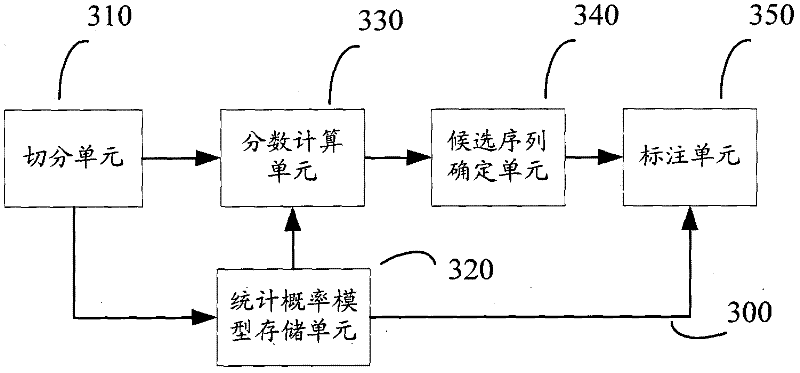
[0050] According to one aspect of the present invention, a natural language lexical analysis device is provided. image 3 A schematic structural diagram of a natural language lexical analysis device 300 according to an embodiment of the present invention is shown. Such as image 3 As shown, the natural language lexical analysis device 300 may include: a segmentation unit 310 , a statistical probability model storage unit 320 , a score calculation unit 330 , a candidate sequence determination unit 340 and a labeling unit 350 .
[0051] The segmentation unit 310 may be configured to segment the input natural language sentence into a plurality of sequences composed of words that may be words of the first type and / or words that may be components of words of the second type, wherein the first type The words of are words other than words of the second type.
[0052] In this embodiment, for convenience of description, Chinese sentences are still used for description. It should be ...
no. 3 approach
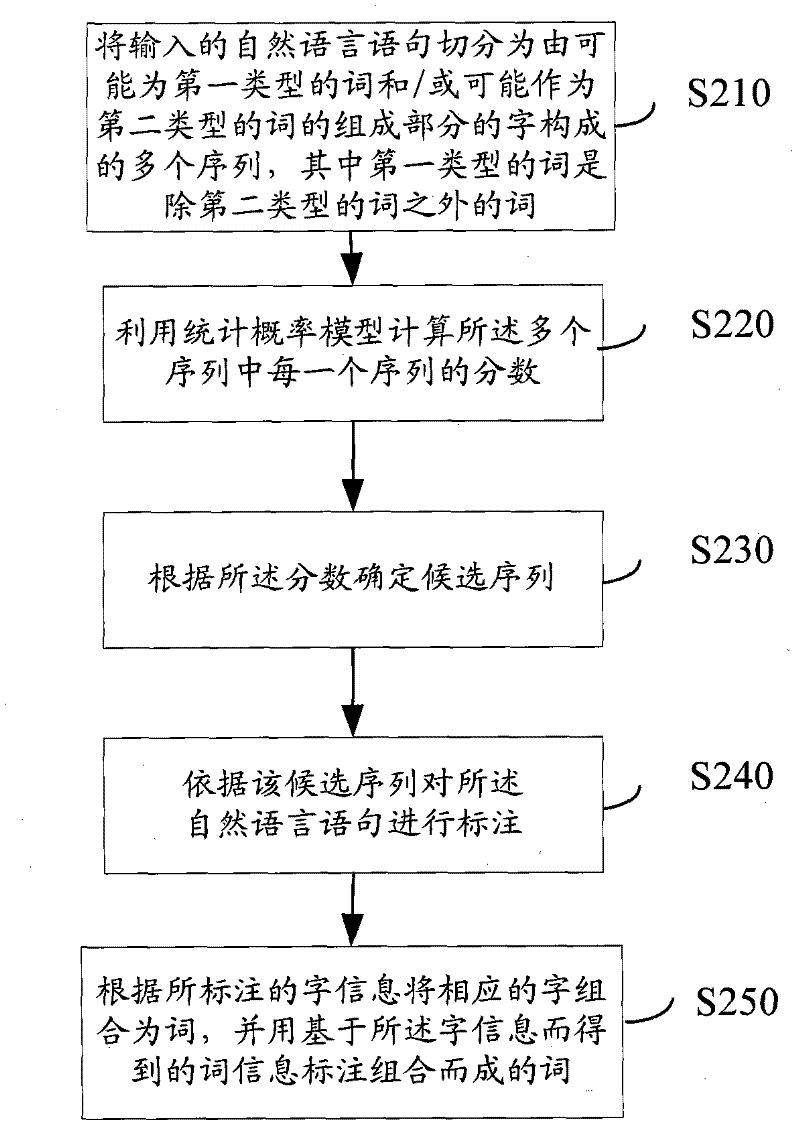
[0066] According to another aspect of the present invention, a method for training a natural language lexical analyzer is provided. Figure 5 A flowchart showing a method for training a natural language lexical analyzer according to another embodiment of the present invention.
[0067] Such as Figure 5 As shown, the natural language lexical analyzer training method may include: labeling natural language sequences as training corpus, wherein only word information is used to mark the words of the first type, and the words of the second type are marked with word information to form the first Words of words of two types, wherein the words of the first type are words other than the words of the second type (step S510).
[0068] Still taking Chinese as an example, for the Chinese sentence "Xiao Ming is going to school tomorrow", the sequence is provided to the analyzer as a training corpus. For example, "tomorrow", "go" and "go to school" can be classified as the first type of wo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com