Systems and methods for training document analysis system for automatically extracting data from documents
a document analysis and document data technology, applied in the field of systems and methods for training document analysis systems for automatically extracting data from documents, can solve the problems of cumbersome software and bloated standards, too expensive, and the application of xml, xbrl and other computer-readable document files is quite limited
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
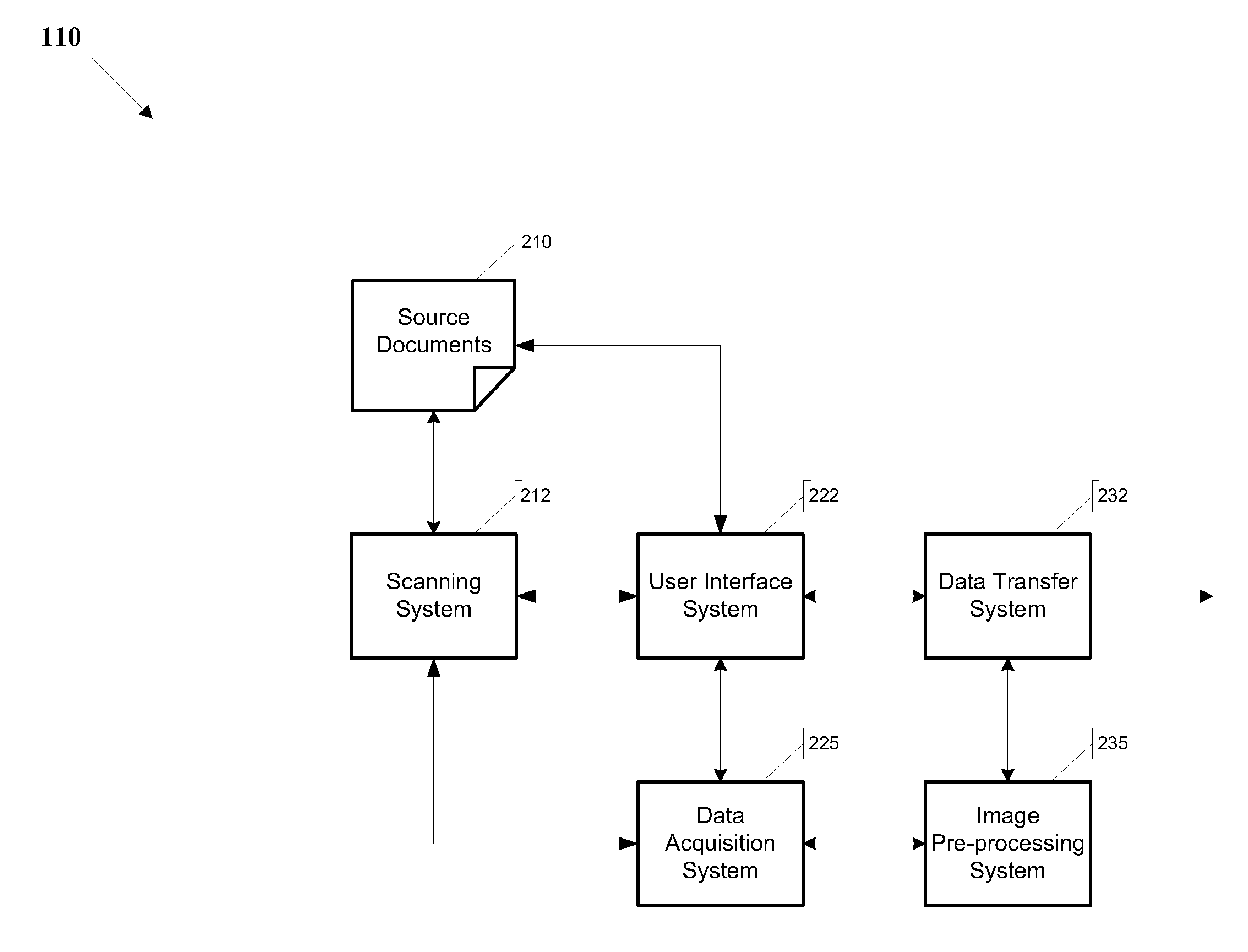
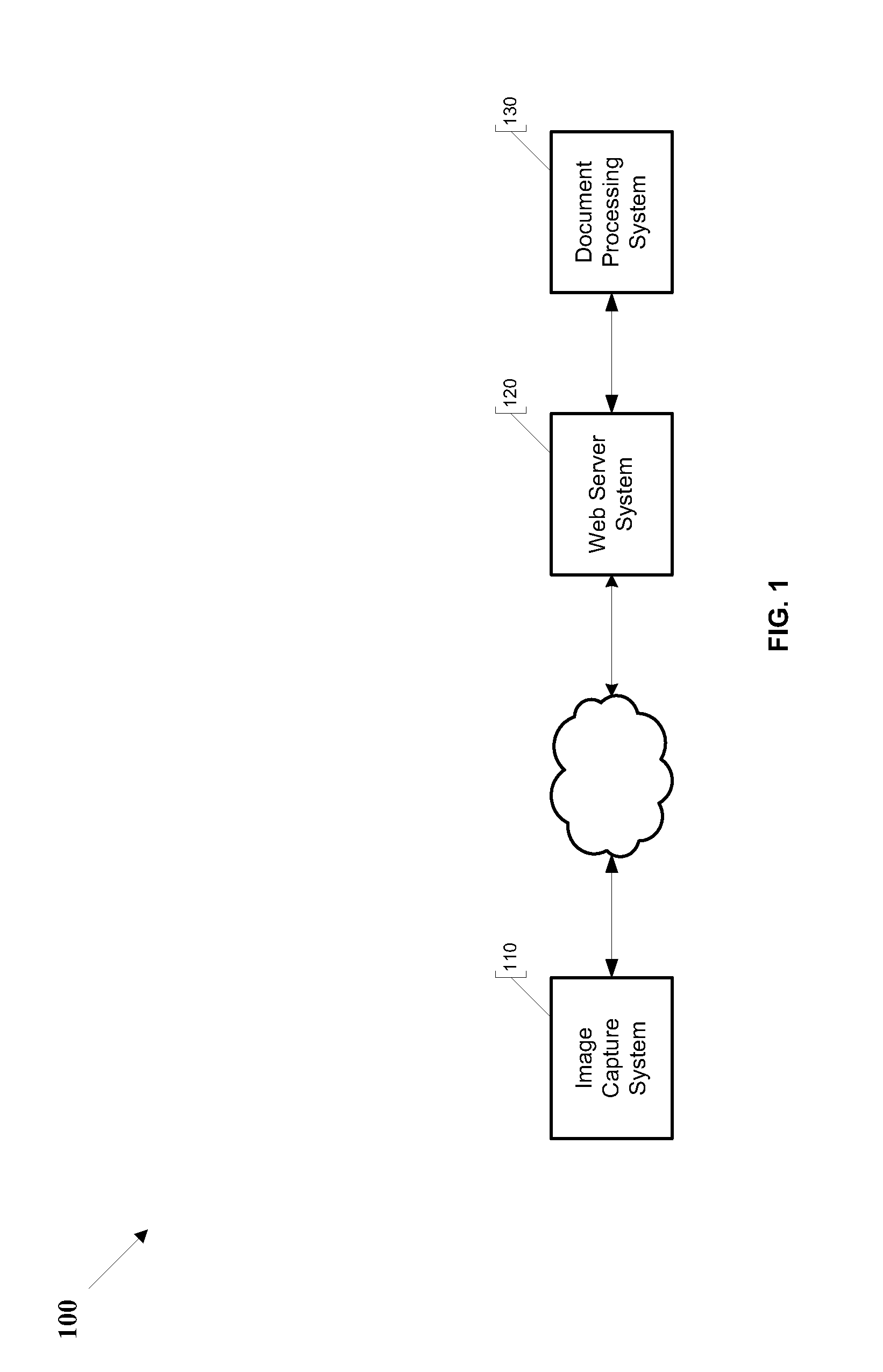
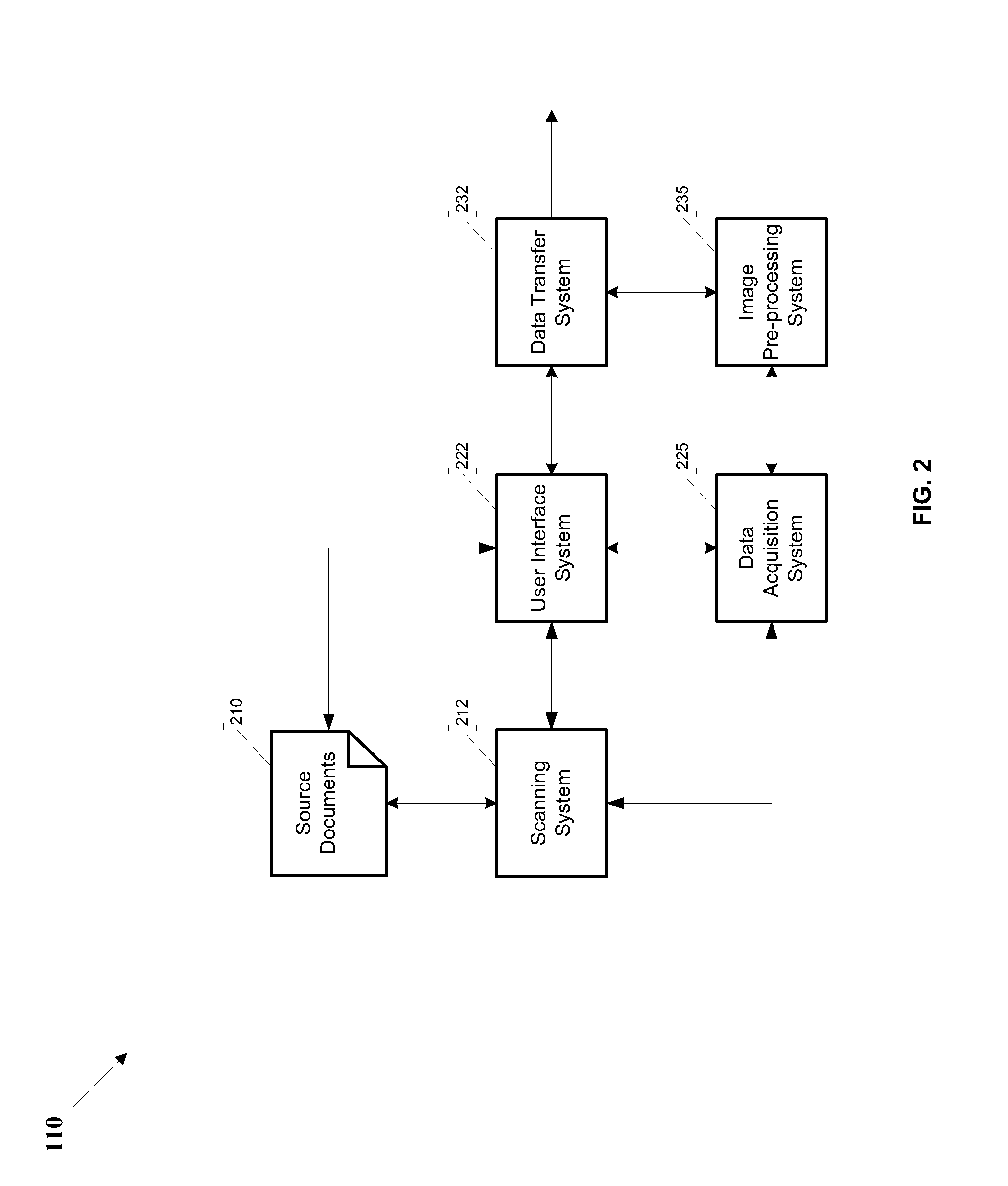
[0092]While the prior art attempts to reduce the cost of data extraction through the use of low cost labor and partial automation, none of the above methods of data extraction (1) eliminates the human labor and its accompanying requirements of education, domain expertise, training, software knowledge and / or cultural understanding, (2) minimizes the time spent entering and quality checking the data, (3) minimizes errors, (4) protects the privacy of the owners of the data without being dependent on the security systems of data extraction organizations and (5) eliminates the cost for significant up-front engineering efforts. What is needed, therefore, is a method of performing data extraction that overcomes the above-mentioned limitations and that includes the features enumerated above.
[0093]Preferred embodiments of the present invention provides a method and system for extracting data from paper and digital documents into a format that is searchable, editable and manageable.
[0094]FIG....
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com