Document information extraction method and system based on text classification and reading comprehension
A reading comprehension and text classification technology, applied in the field of information content processing, can solve problems such as shortening training and prediction time, difficulty in model training, and low extraction accuracy, improving prediction accuracy, solving entity nesting, and having strong versatility. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
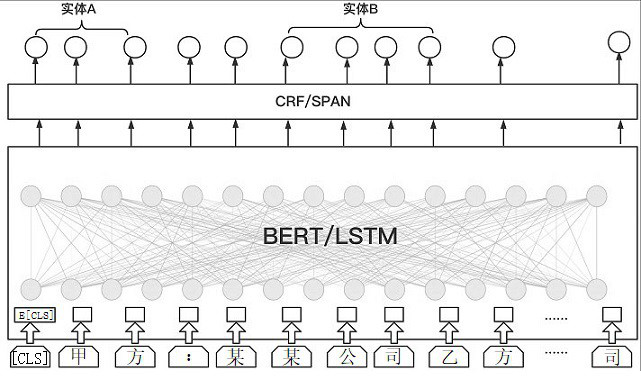
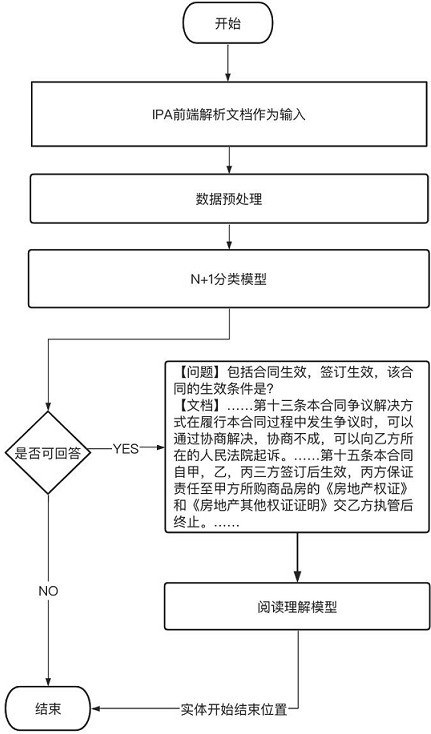
[0075] like figure 2 As shown, the present invention provides a document information extraction method based on text classification and reading comprehension, comprising the following steps;
[0076] S1, input a document, parse and identify the document, and convert the document into a plain text format;
[0077] S2, preprocess the text content in the document to obtain input data;
[0078] S3, according to the input data in step S2, generate the corresponding word vector, word vector and context vector, and splicing the word vector, word vector and context vector to obtain a spliced vector;
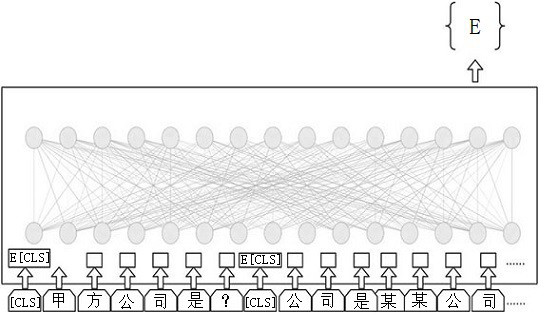
[0079] S4, if the spliced vector is an answerable type, the entity text question corresponding to the spliced vector is used as the input of the next step;
[0080] S5, using the reading comprehension model, obtain the position of the most matching long label data corresponding to the entity text question by calculation;
[0081] S6, obtain long label data according to the posi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com