


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Dask cluster-oriented dynamic data partitioning method based on local weighted linear regression
A locally weighted, linear regression technology, applied in electrical digital data processing, special data processing applications, digital data information retrieval, etc., can solve the problems of time-consuming, labor-intensive, difficult to adapt to data set parallel applications and cluster environments, and avoid Offline training, avoiding high dependence, and improving efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
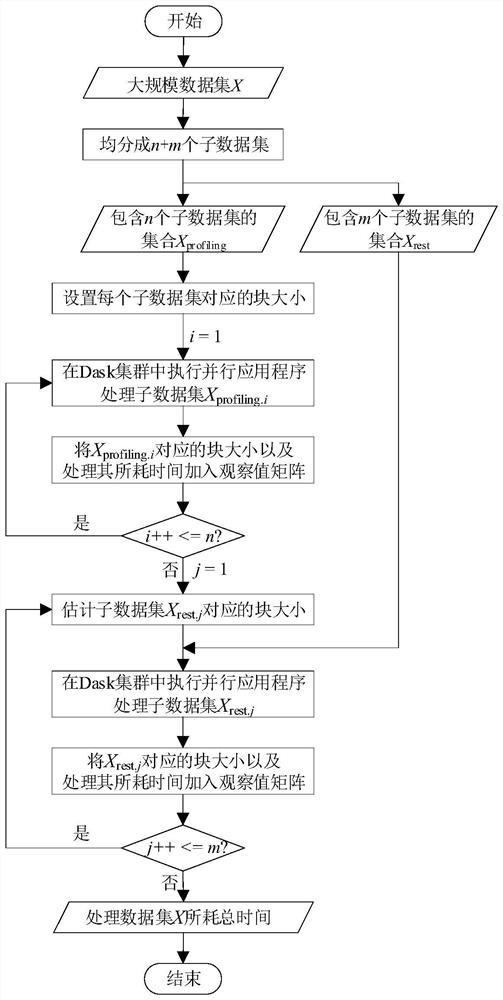
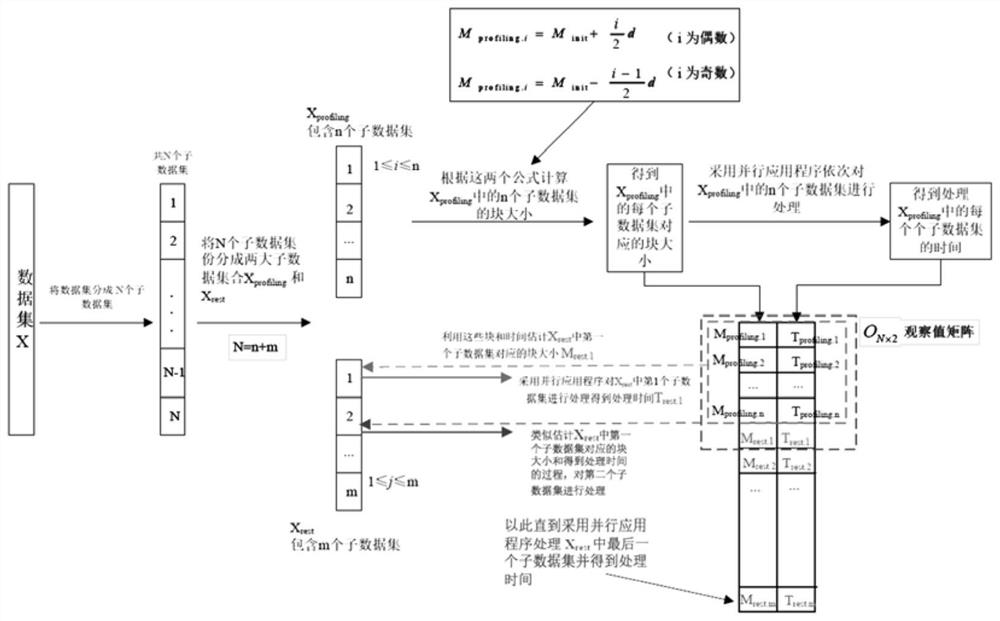
[0049] In the dynamic data block method based on locally weighted linear regression for Dask clusters, the large-scale data set is defined as X, and the set of sub-data sets used for block size optimization is X profiling , the remaining set of sub-datasets to be processed is X rest , the number of sub-datasets in X is N, and X profiling The number of neutron datasets is n, X rest The number of neutron datasets is m, X profiling The i-th sub-dataset is X profiling.i , X rest The jth sub-dataset is X rest.j , the initial block size is M init , X profiling The block size M corresponding to the i-th sub-dataset in profiling.i , X rest The block size M corresponding to the jth sub-dataset in rest.j , processing X profiling The time taken for the i-th sub-dataset in is T profiling.i , processing X rest The time spent on the jth sub-dataset in is T rest.i , the total time spent processing X is T total .
[0050] Include the following steps:
[0051] S1. Divide the la...
Embodiment 2
[0063] This embodiment provides its specific algorithm according to the method described in Embodiment 1, and the specific steps include:
[0064]
[0065]
[0066] Wherein, the "←" is the way of writing in the algorithm, which is equivalent to "=".
Embodiment 3
[0068] According to the algorithm described in Embodiment 2, this implementation performs static and dynamic calculations on a data set, wherein the hardware environment used is:
[0069]
[0070] The software environment is:
[0071]
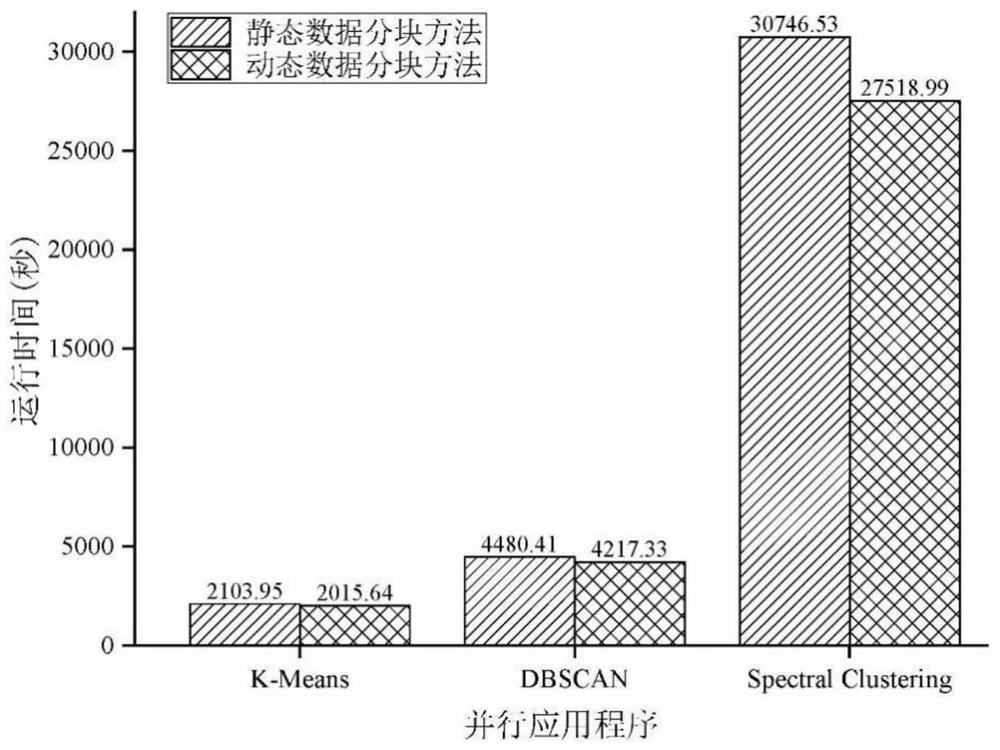
[0072] (1) Static calculation
[0073] Divide a data set of size 8.7GB into n blocks, and then process n blocks at the same time with a parallel application.
[0074] (2) Dynamic calculation
[0075] Divide a data set with a size of 8.7GB into m sub-datasets, and divide the m sub-datasets into X according to the ratio of 2:8 profiling and x rest , for X profiling Each sub-dataset in the block is divided into blocks, and the initial block size M init , block size variation d, Gaussian kernel parameter σ, residual X rest The number of blocks in the neutron data set depends on the dynamic selection of the program, and then the m sub-data sets are processed sequentially with a parallel application program.
[0076] The parameters of th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com