


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Multi-modal emotion recognition method and device, electronic equipment and storage medium
An emotion recognition, multimodal technology, applied in the field of speech recognition and image processing, can solve the problems of text noise, inaccurate emotion recognition, loss of irony, etc., to achieve high accuracy, reduce noise interference, improve accuracy and robustness. awesome effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
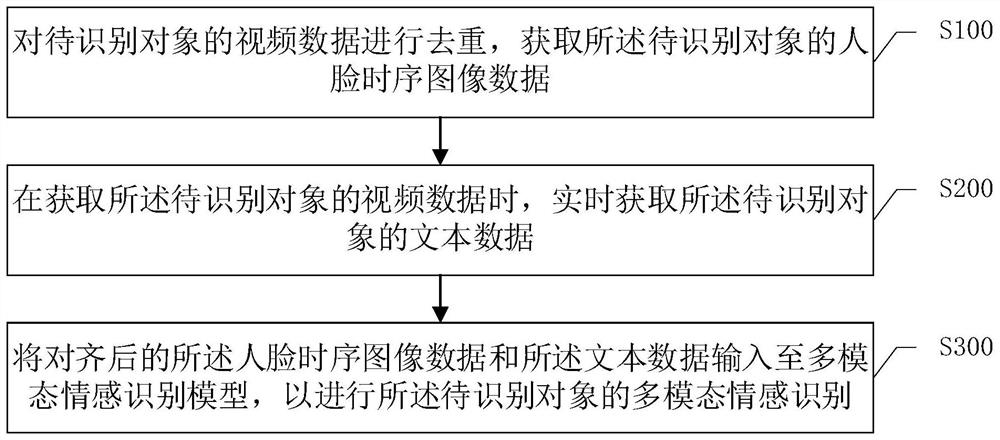
[0083] An embodiment of the present invention, such as figure 1 As shown, a multi-modal emotion recognition method, including:
[0084] S100 Deduplicate the video data of the object to be identified, and acquire time-series image data of the face of the object to be identified.
[0085] Specifically, the data input layer in the training phase: the data input includes video data and text dialogue data collected in real time during the chat process. The video data captures the chat object in real time through the virtual human camera, and then recognizes the timing diagram of the face through the algorithm.
[0086] The video data of the object to be identified is deduplicated, and the time-series image data of the face of the object to be identified is obtained, which specifically includes the steps of:
[0087] Use the Vibe algorithm to model the background, extract the binary gray-scale contour map of the relatively static background, and perform the corresponding morpholog...
Embodiment 2
[0101] Based on the above-mentioned embodiment, the parts that are the same as those in the above-mentioned embodiment in this embodiment will not be described one by one, such as figure 2 As shown, this implementation provides a multimodal emotion recognition method, specifically including:
[0102] S100 Deduplicate the video data of the object to be identified, and acquire time-series image data of the face of the object to be identified.
[0103] S201 Acquire voice data input by the object to be recognized in each round of dialogue.
[0104] S202 Translate the voice data into text data in real time through a voice recognition interface.
[0105] Exemplary, the text data input layer of the multimodal emotion recognition model:
[0106] 1. During the chat process, obtain every sentence entered by the user, and wait for the user to finish a round of dialogue in order to obtain a complete single-round dialogue, because a single-round dialogue may contain multiple sentences. ...
Embodiment 3
[0112] Based on the above embodiment, in this embodiment, the aligned face time-series image data and the text data are input to a multimodal emotion recognition model to perform multimodal emotion recognition of the object to be recognized , including steps:
[0113]Using the multi-modal emotion recognition model to extract the first dual-modal feature with image as the core and the second dual-modal feature with text as the core, the first dual-modal feature and the second dual-modal feature State features are combined to obtain target features, and the target features are input to the softmax classifier of the multi-modal emotion recognition for classification and loss calculation, so as to obtain the multi-modal emotions of the object to be recognized.
[0114] Preferably, said using said multi-modal emotion recognition model to extract the first dual-modal features with image as the core, specifically includes the steps of:
[0115] The image semantic sequence vector in ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com