Method for labeling audio by using deep learning model
A deep learning and speech annotation technology, applied in audio data retrieval, metadata audio data retrieval, speech analysis, etc., can solve problems such as poor results, save labor and time costs, and ensure effectiveness.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
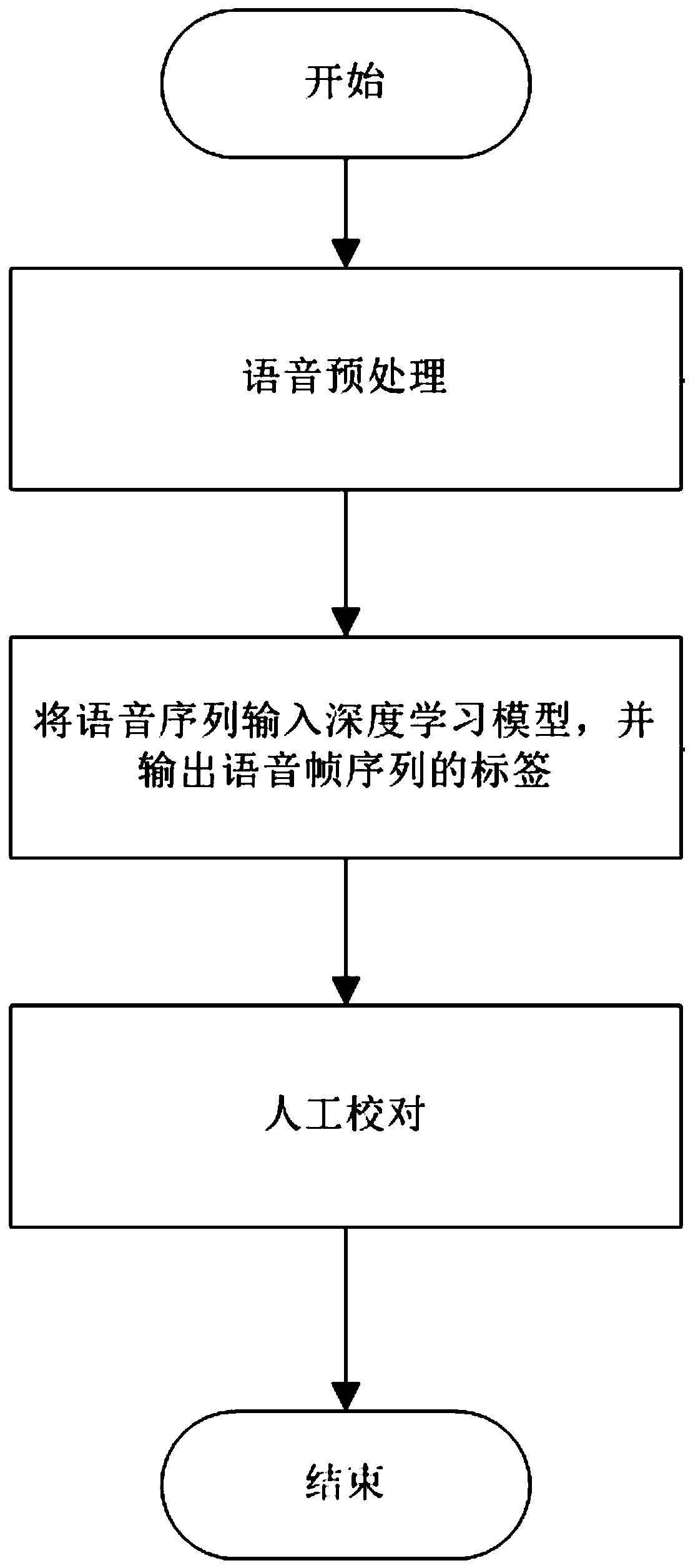
[0031] A method for labeling audio using a deep learning model. The general workflow of the method for labeling audio using a deep learning model of the present invention is: first obtain the audio, and perform corresponding preprocessing on the audio, and then preprocess the audio The audio data is input into the deep learning model. First, the deep neural network with self-learning function in the deep learning model performs preliminary recognition and learning of speech and non-speech. The deep neural network continuously updates the judgment standard according to the learning results. Refer to the learning and judgment results of the deep learning model to actually judge the input audio data, whether the output is voice, if it is voice, it will further judge the specific voice content and mark it accordingly, and label the audio according to the voice annotation, and finally manually In the above process, as long as the deep learning model is trained well, manual processin...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com