Voice recognition method and system
A sound recognition and sound signal technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problem of low recognition accuracy, and achieve the effect of improving the accuracy and maintaining the amount of calculation.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0031] According to the embodiment of the present application, an embodiment of a voice recognition method is also provided. It should be noted that the steps shown in the flow chart of the accompanying drawings can be executed in a computer system such as a set of computer-executable instructions, and, Although a logical order is shown in the flowcharts, in some cases the steps shown or described may be performed in an order different from that shown or described herein.
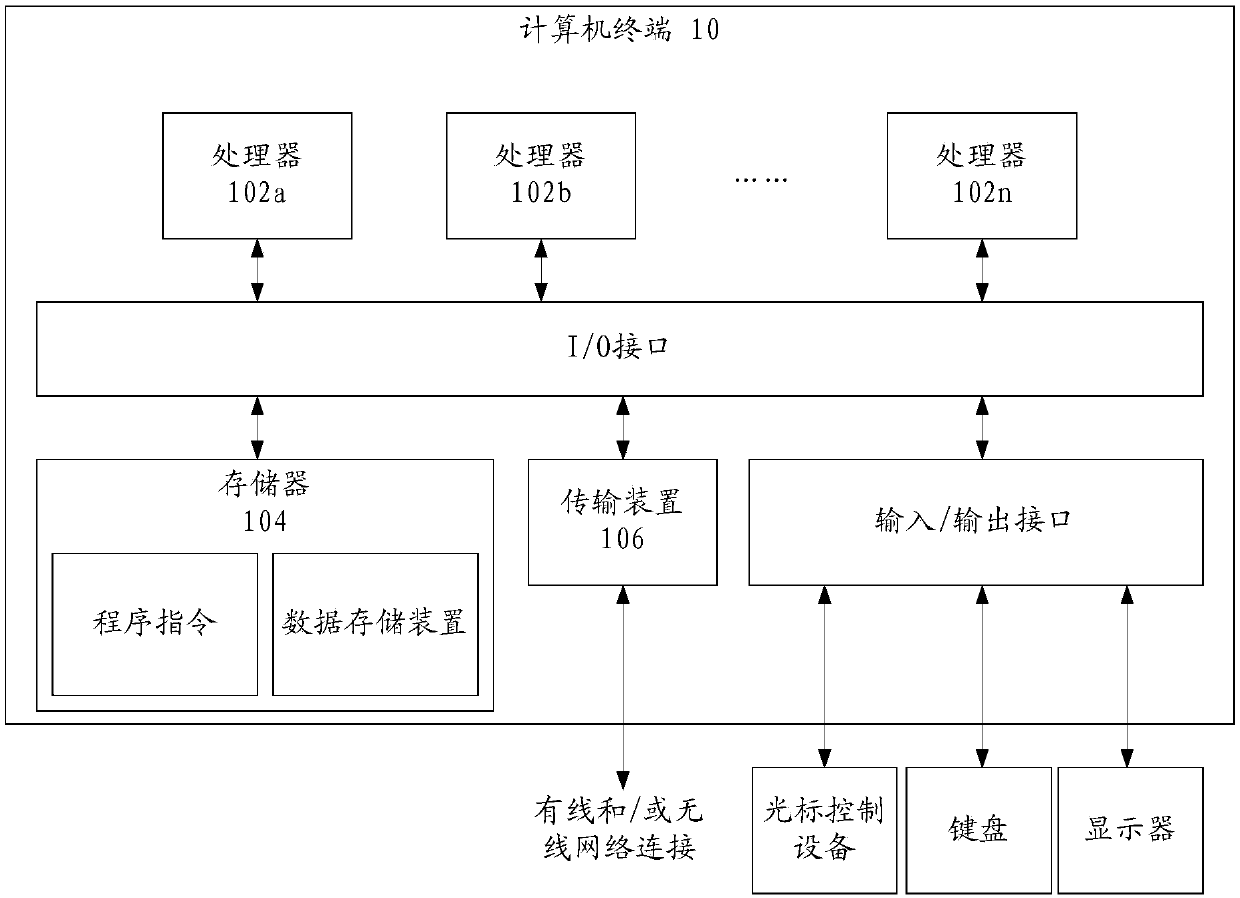
[0032] The method embodiment provided in Embodiment 1 of the present application may be executed in a mobile terminal, a computer terminal, or a similar computing device. figure 1A block diagram of a hardware structure of a computer terminal (or mobile device) for realizing the voice recognition method is shown. Such as figure 1 As shown, the computer terminal 10 (or mobile device 10) may include one or more (shown by 102a, 102b, ..., 102n in the figure) processor 102 (the processor 102 may include but not...
Embodiment 2
[0082] According to an embodiment of the present application, a voice recognition device for implementing the above voice recognition method is also provided, such as Figure 8 As shown, the apparatus 800 includes: an acquisition module 802 , an extraction module 804 and an identification module 806 .
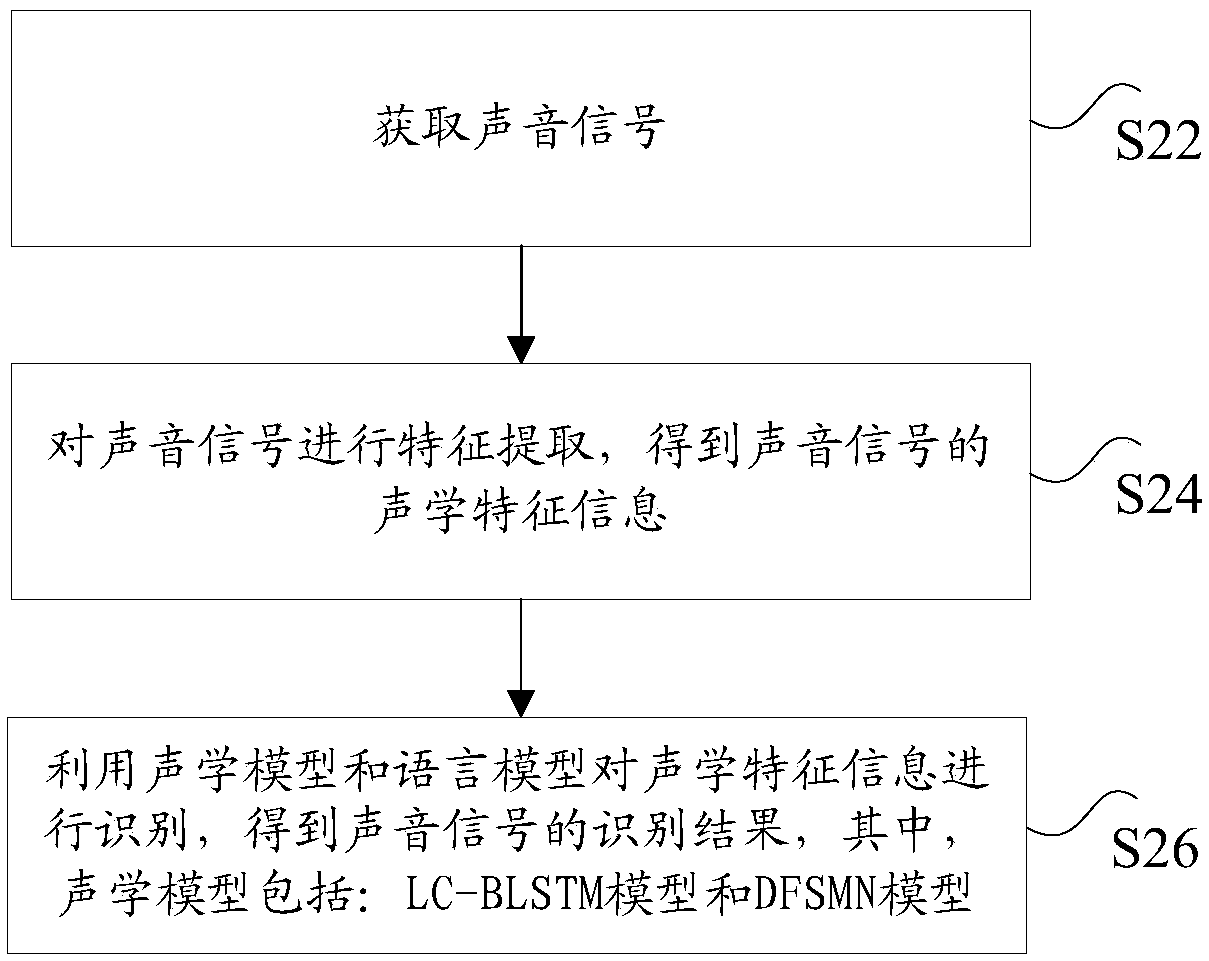
[0083] Among them, the acquisition module 802 is used to obtain the sound signal; the extraction module 804 is used to extract the feature of the sound signal to obtain the acoustic feature information of the sound signal; the recognition module 806 is used to identify the acoustic feature information by using the acoustic model and the language model to obtain The recognition result of the sound signal, wherein the acoustic model includes: LC-BLSTM model and DFSMN model.
[0084] Specifically, the above-mentioned sound signal may be a voice uttered by the user, and the voice uttered by the user may be collected by a voice collection device such as a microphone. Since the soun...
Embodiment 3
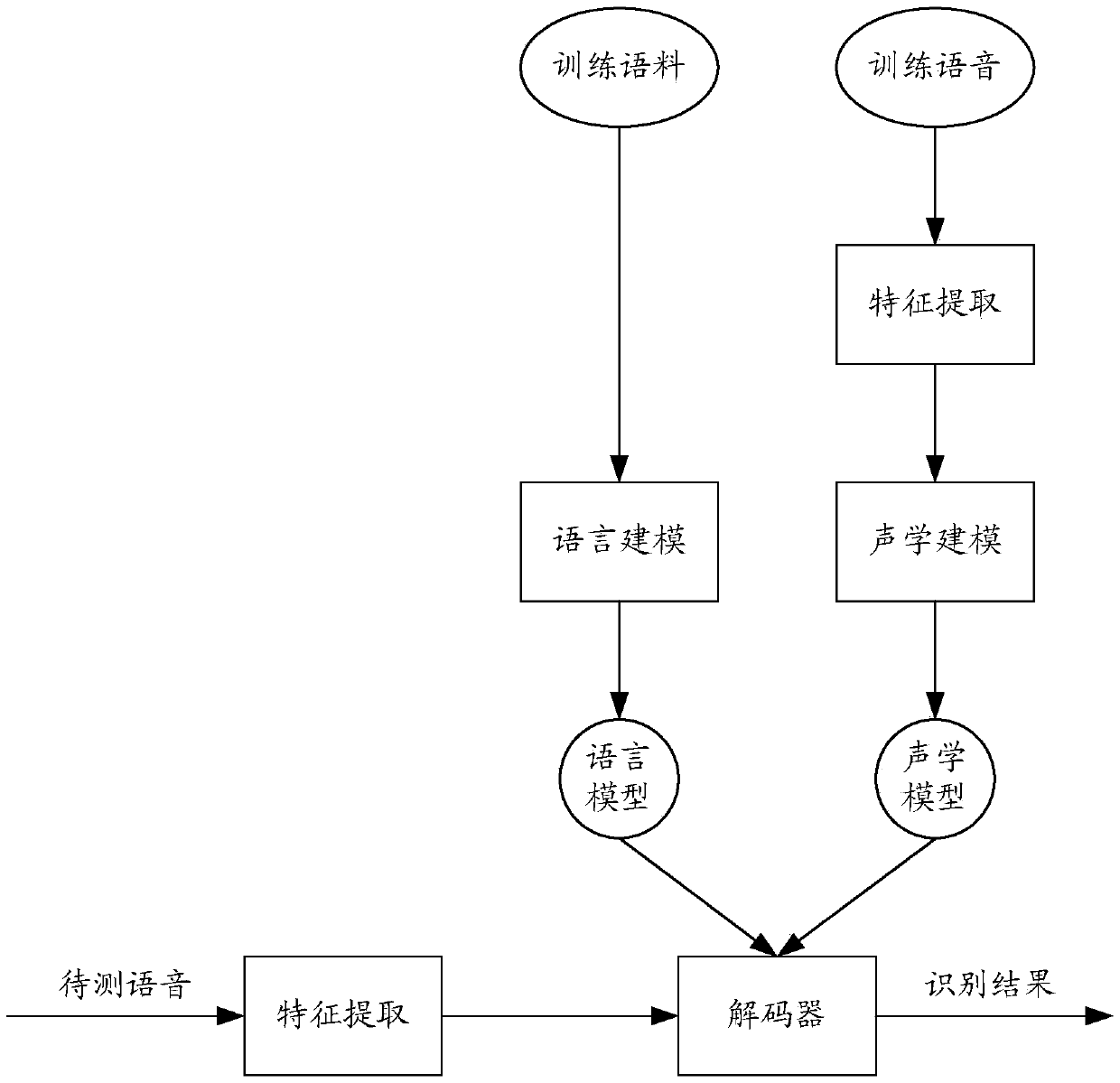
[0107] According to an embodiment of the present application, a voice recognition system is also provided, such as Figure 9 As shown, the system includes:
[0108] The acoustic feature extraction module 92 is configured to perform feature extraction on the acquired sound signal to obtain acoustic feature information of the sound signal.
[0109] Specifically, the above-mentioned sound signal may be a voice uttered by the user, and the voice uttered by the user may be collected by a voice collection device such as a microphone. Since the sound signal collected by the speech collection device is an analog signal, it can first be converted into a digital signal through a recorder, so that the feature extraction of the digital signal can be performed.
[0110] In order to ensure the accuracy of recognition, the above-mentioned acoustic feature information can better distinguish the modeling units of the acoustic model. Under the premise of text information in the signal, interf...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com