GPU-based distributed big data parallel computing method
A parallel computing and big data technology, applied in computing, electrical digital data processing, resource allocation, etc., can solve problems such as complex management, high cost of working nodes, insufficient number of working nodes, etc., and achieve the effect of improving efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
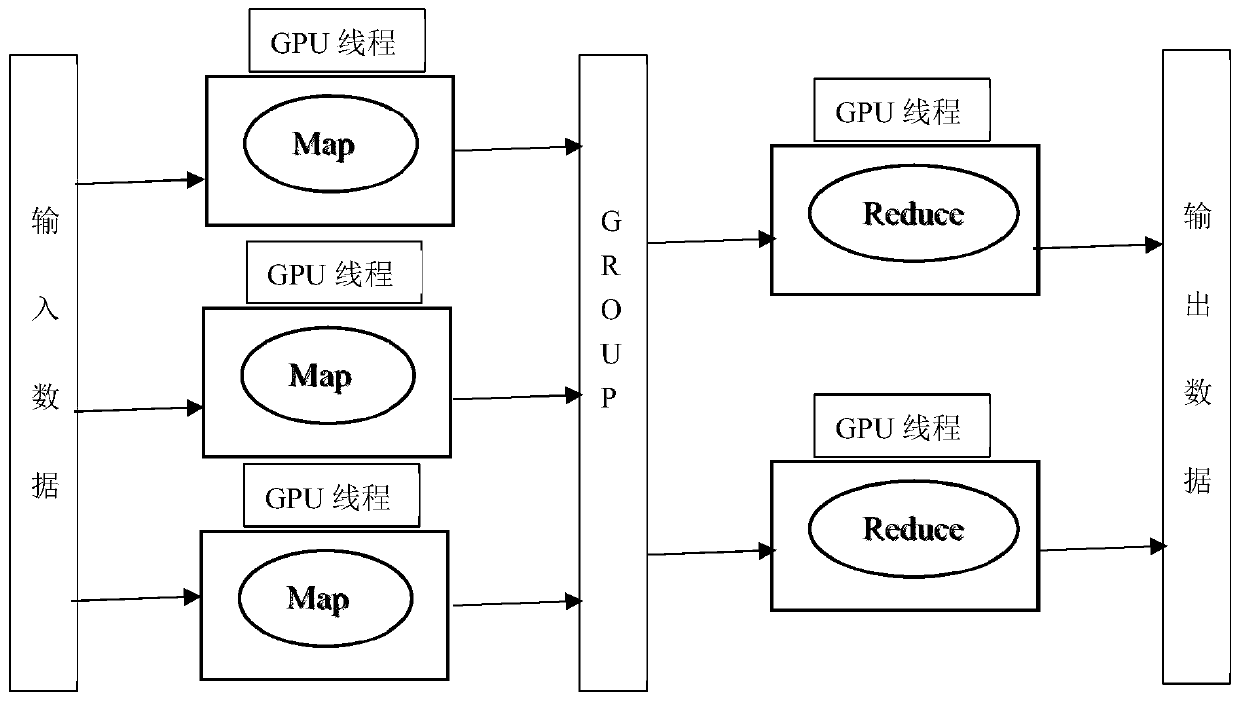
[0035] Embodiment 1 specifically realizes a kind of GPU-based distributed big data parallel computing method proposed by the present invention, and its data flow diagram is as follows figure 1 shown.
[0036] This embodiment is based on the design idea of google MapReduce. To improve the efficiency of the Map and Reduce phases, the most direct way is to increase the number of working nodes and further subdivide the parallel granularity. However, if you increase the number of CPUs in the network or increase the number of CPU physical cores to increase the number of work nodes, the cost is high, the management is complicated, and the number of work nodes is far from enough to achieve or even approach the level of key-value pair parallelism.
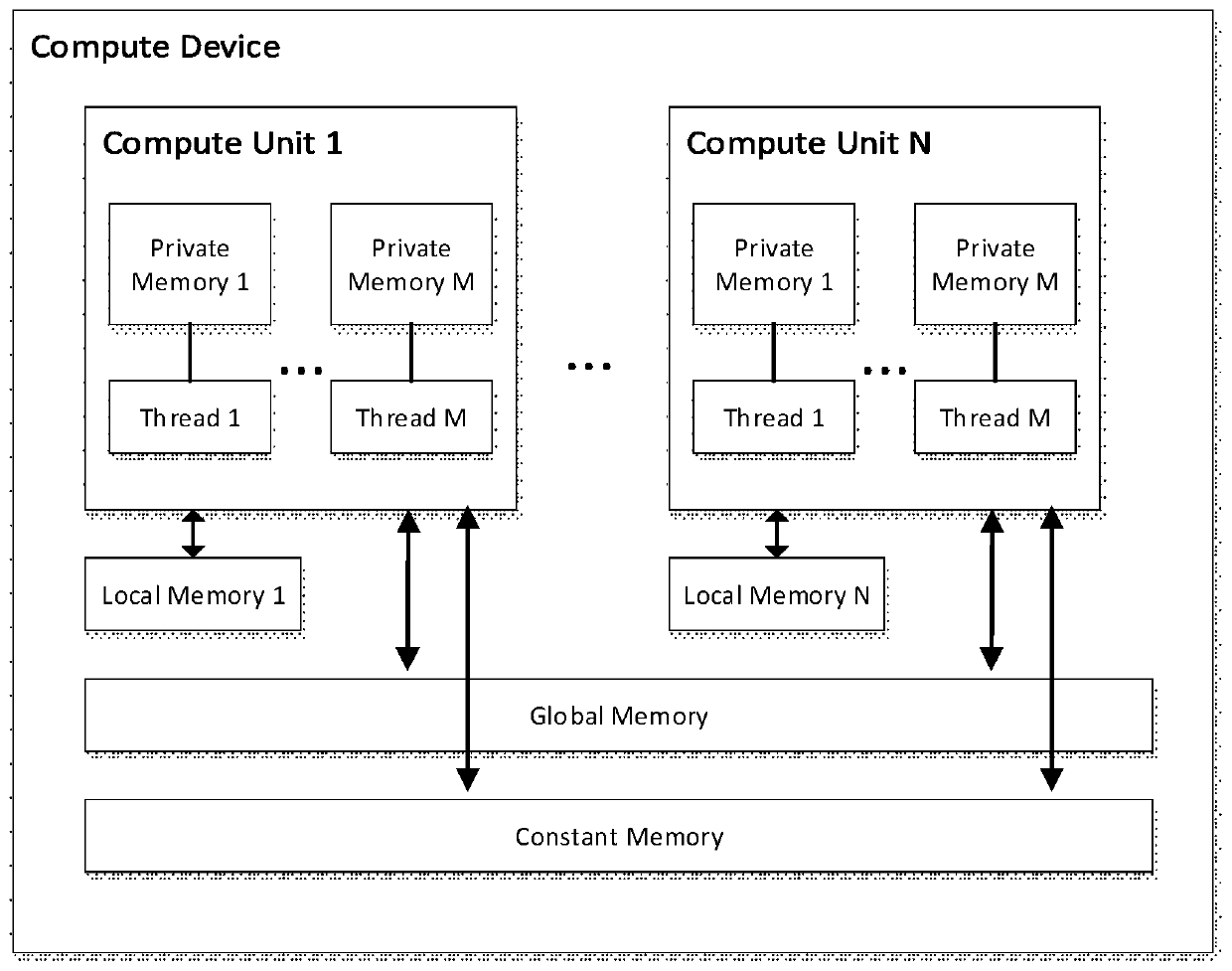
[0037] GPU is a massively parallel computing hardware whose thread architecture and storage structure can be abstracted as figure 2structure shown. Each computing device (Compute Device) has several computing units (Compute Unit), and...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com