


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Short text-oriented optimization classification method
A classification method and short text technology, applied in special data processing applications, instruments, electronic digital data processing, etc., can solve problems such as difficulty in extracting semantic information, a large amount of external corpus, and limited improvement of classification accuracy, and achieve enhanced semantic representation. ability, reduce the amount of calculation, and improve the effect of precision
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
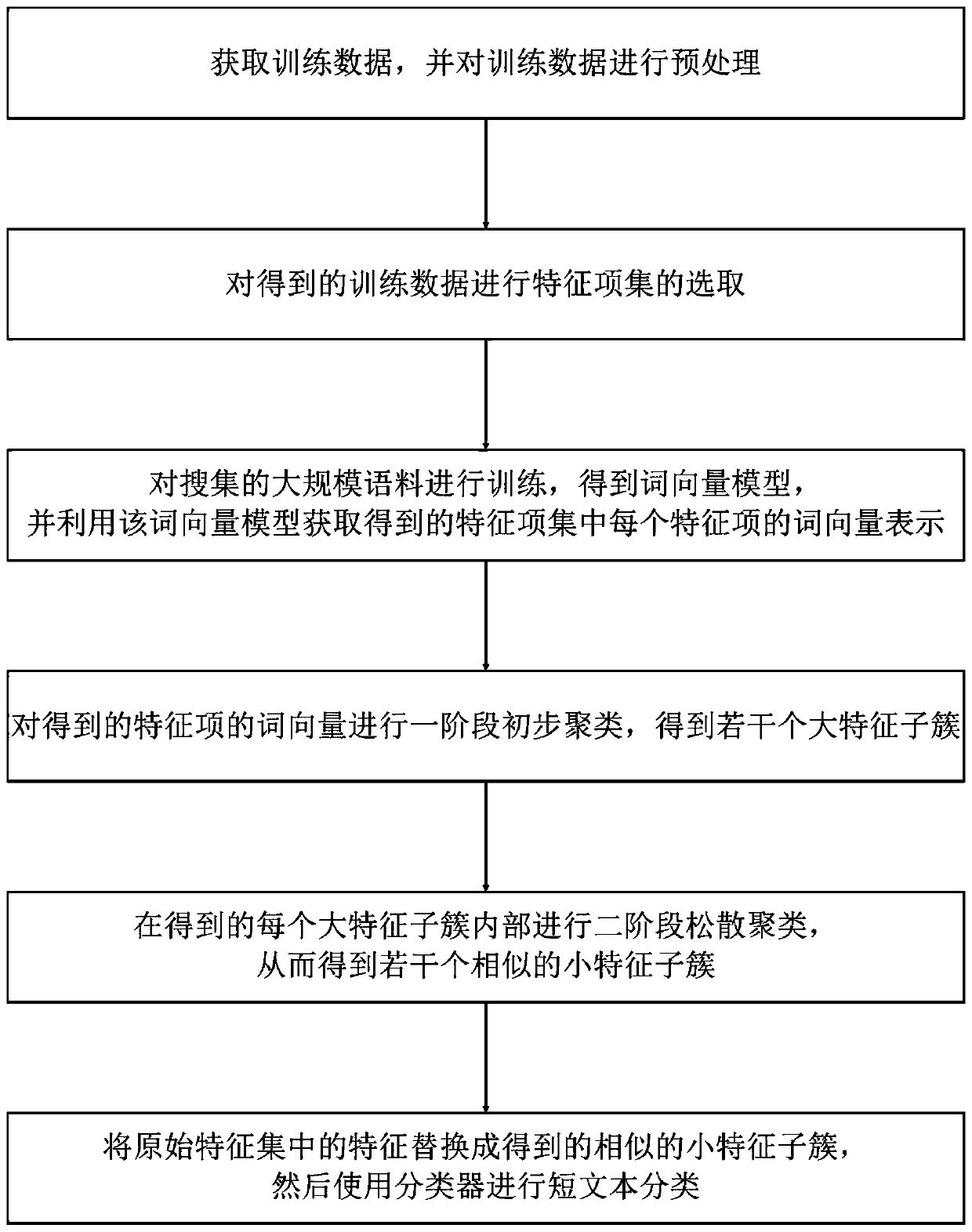
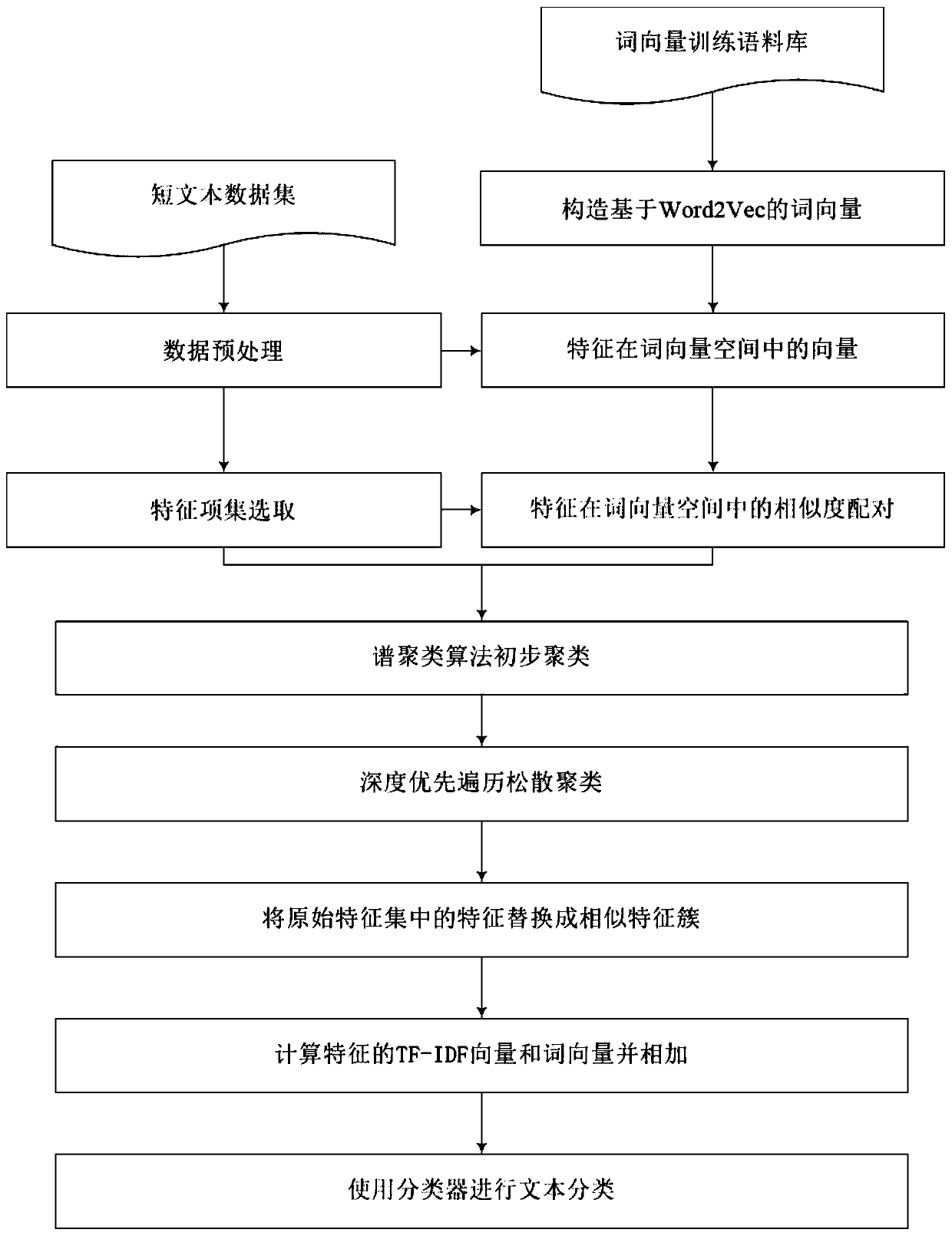
[0054] This embodiment is a specific embodiment of a method for optimal classification of short texts based on feature clustering. The present invention is mainly divided into six steps:
[0055] Step 1. Obtain training data, and preprocess the training data using the following steps:
[0056] A. The training data comes from the open source news corpus released by Fudan and Sogou Labs, with more than 200,000 pieces of data, including six categories: sports, Internet, economy, politics, art, and military;
[0057] B. Add the collected and organized online content word dictionary to improve the accuracy of subsequent word segmentation;
[0058] C. Remove stop words;
[0059] D. Segment the training data and complete the preprocessing.
[0060] Step 2. For the training data obtained in step 1, traverse each feature word in the data set after word segmentation, and select feature words whose word frequency is greater than the set threshold and have no repetition to construct a ...
Embodiment 2
[0086] This embodiment is a specific embodiment of a method for optimal classification of short texts based on feature clustering. The present invention is mainly divided into six steps:
[0087] Step 1. Obtain training data, and preprocess the training data using the following steps:
[0088] A. The training data comes from the China Mobile SMS data set, including normal, marketing, advertising, credit card, and others, a total of 5 categories, with a total data of about 100,000;
[0089] B. Remove stop words;
[0090] C. Segment the training data and complete the preprocessing.
[0091] Step 2. For the training data obtained in step 1, traverse each feature word in the data set after word segmentation, and select word frequency greater than the set threshold (set to 2 here) and no repeated feature words to construct feature item sets;
[0092] Step 3. To train the large-scale corpus collected, the specific steps are:
[0093] A. Collect open source Chinese corpus from Wi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com