Voice synthesis method based on voice radar and video
A speech synthesis and speech technology, applied in the field of radar, can solve the problem of speech synthesis of radar signals and image information, etc., and achieve the effects of natural pronunciation, strong anti-noise, and wide application scenarios.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
preparation example Construction
[0016] In conjunction with accompanying drawing, a kind of speech synthesis method based on speech radar and video of the present invention comprises the following steps:
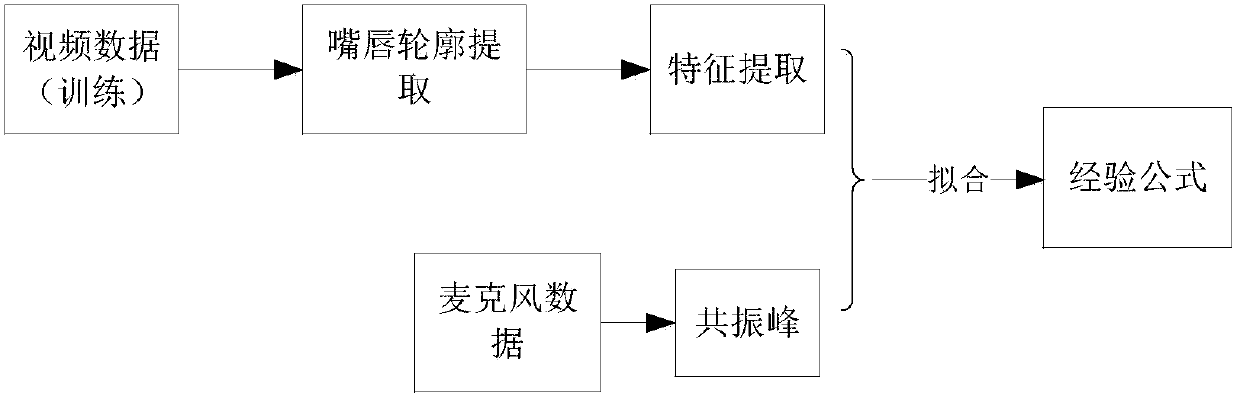
[0017] Step 1. Use the radar echo signal to obtain the fundamental frequency information of the voice, specifically: the non-contact voice radar sends a continuous sine wave to the speaker, the receiving antenna receives the echo signal, and then preprocesses the received echo signal, Fundamental frequency and higher harmonic mode decomposition, time-frequency signal processing, so as to obtain the frequency of the time-varying vocal cord vibration, that is, the fundamental frequency of the speech signal;
[0018] The radar echo signal is the vocal cord vibration signal of the speaker collected by the radar echo; the speaker's pronunciation is the sound of a certain character.
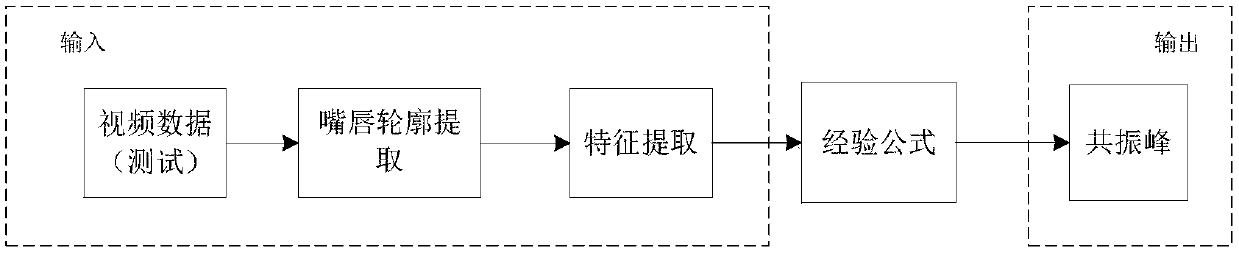
[0019] Step 2. Fitting the time-varying motion feature extracted from the lip video information when the speaker is pronounced and...
Embodiment
[0040] In this embodiment, an adult man sends the English character "A", the speaker obtains the fundamental frequency information of the voice from the radar echo signal when he sends "A", and the non-contact voice radar sends the continuous sine wave to the speaker, and receives the The antenna receives, preprocesses the echo, decomposes the fundamental frequency and higher harmonic modes, and processes the time-frequency signal, so as to obtain the frequency of the time-varying vocal cord vibration, that is, the fundamental frequency of the speech signal.
[0041] The motion features extracted from the lip video information when other speakers pronounce "A" and the formants extracted from the speech signals obtained by the microphone synchronously are fitted to obtain the lip motion features and the empirical formula of the mapping relationship of the three groups of formants; by the empirical formula, Taking the video information of the speaker's lips to be synthesized as i...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com