A loudspeaker-based personalized sound image reproduction method and device
A loudspeaker and dual-speaker technology, applied in the direction of speaker distribution signal, frequency/direction characteristic device, neural learning method, etc., can solve the problem of poor spatial perception effect of the listener, achieve improved spatial perception effect, and reduce computational complexity Effect of harmonic reconstruction error
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
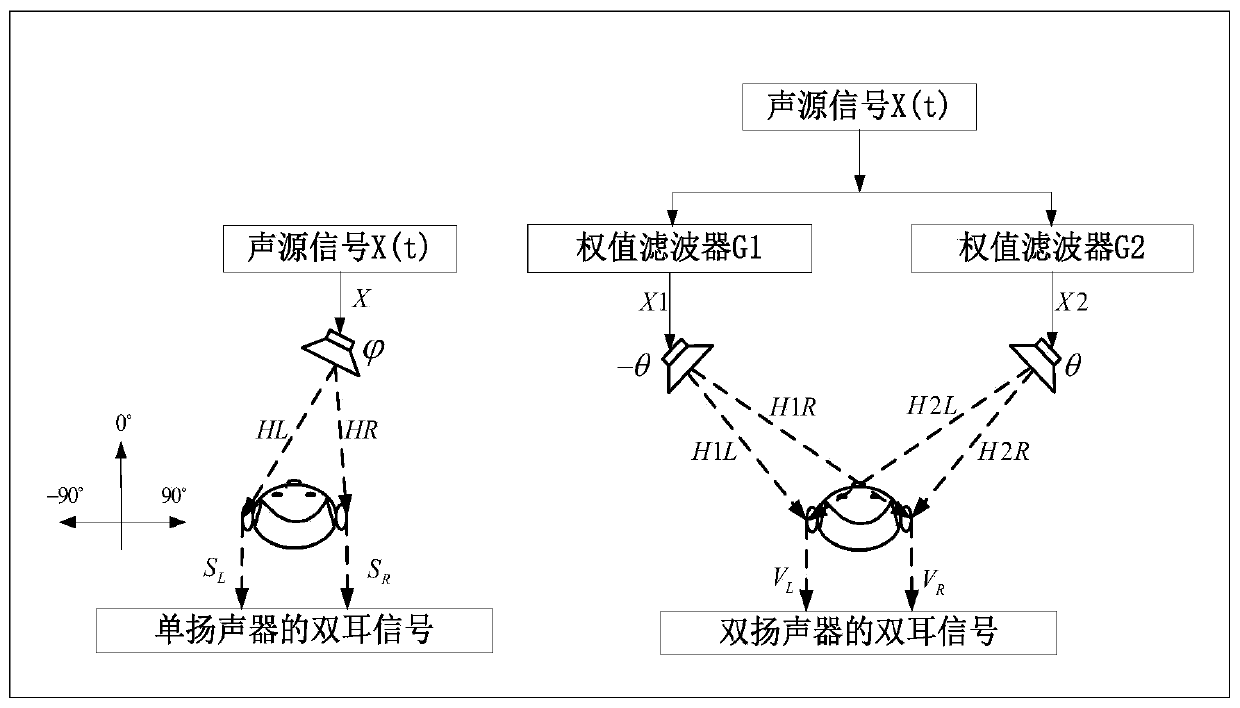
[0056] This embodiment provides a loudspeaker-based method for personalized sound image reproduction, please refer to figure 1 , the method includes:
[0057] Step S1: Determine the orientation of the speakers and the target orientation, wherein the number of speakers is at least two, and the target orientation is an ideal reconstructed sound image orientation.
[0058] Specifically, the target azimuth is the azimuth of a sound image that is expected to be synthesized by the two speakers. For example, the azimuth where the two speakers are expected to be synthesized is A, and A is the target azimuth. The number of speakers can be set according to the actual situation, such as 2, 3, 4, etc. By setting multiple speakers, a small range of personalized sound image reproduction can be achieved, and a better azimuth rendering effect can be obtained.
[0059] In the specific implementation process, taking two loudspeakers as an example, an appropriate coordinate system can be establ...
Embodiment 2
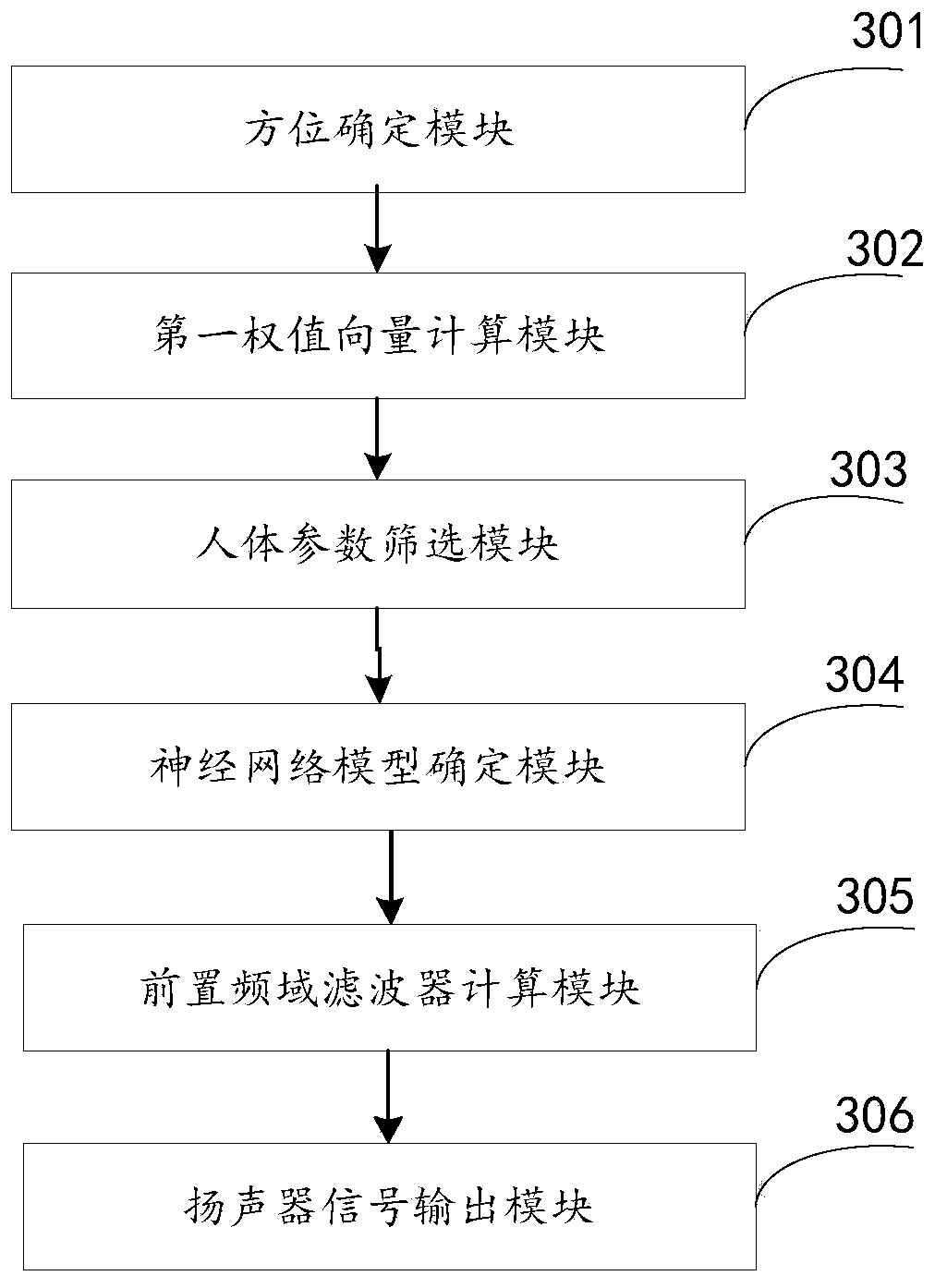
[0109] This embodiment provides a loudspeaker-based personalized audio image reproduction device, please refer to image 3 , the device consists of:
[0110] The orientation determining module 301 is configured to determine the orientation of the speaker and the target orientation, wherein the number of the speakers is at least two, and the target orientation is the orientation of the ideal reconstructed sound image;
[0111] The first weight vector calculation module 302 is used to determine the corresponding HRTF according to the orientation of each loudspeaker and the target orientation, wherein the HRTF is stored in the HRTF database, and the HRTF and the corresponding complete human body parameters are recorded in the database, and based on the HRTF database, establishing the equation of the binaural signal of the virtual sound image and the binaural signal of the target sound image, and calculating the first weight vector corresponding to each loudspeaker;
[0112] The ...
Embodiment 3
[0128] Based on the same inventive concept, the present application also provides a computer-readable storage medium 400, please refer to Figure 4 , on which a computer program 411 is stored, and the method in Embodiment 1 is implemented when the program is executed.
[0129] Since the computer-readable storage medium introduced in the third embodiment of the present invention is the computer-readable storage medium used to implement the speaker-based personalized audio-image reproduction method in the first embodiment of the present invention, it is based on the first embodiment of the present invention With the method introduced, those skilled in the art can understand the specific structure and deformation of the computer-readable storage medium, so details are not repeated here. All computer-readable storage media used in the method of Embodiment 1 of the present invention belong to the scope of protection of the present invention.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com