Method and system for judging text similarity
A text similarity, text similarity technology, applied in special data processing applications, instruments, electrical digital data processing and other directions, can solve the problem of high recognition rate, and achieve the effect of accurate judgment results
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
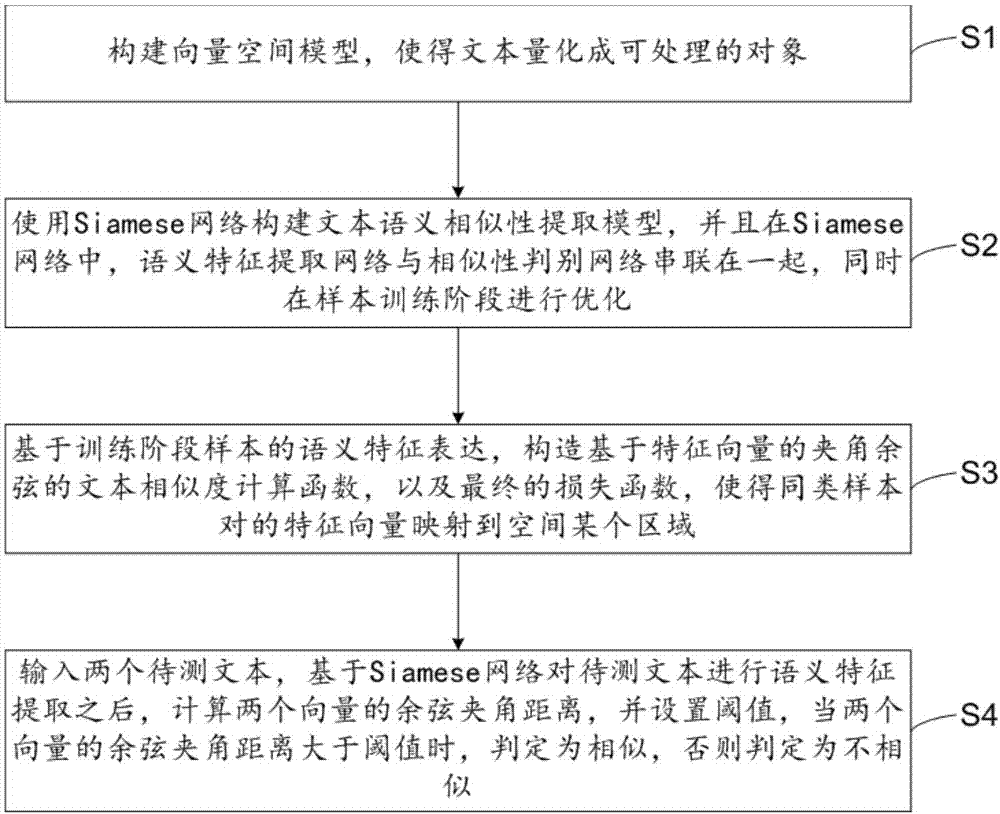
[0041] Such as figure 1 As shown, the present embodiment provides a method for judging text similarity, which is a text similarity judging method based on the Siamese network; first, a VSM model needs to be established for text data, and the process includes preprocessing, word segmentation, and removal of disabled Words, quantify the text into a processable feature vector; then construct a Siamese network (also called a twin network) to extract the semantic similarity features of a sample pair based on a feature vector; finally construct a tripletloss (also called a triplet Loss) The loss function is used to judge the relevance of text pairs. The method specifically includes:
[0042] S1. Construct a vector space model to quantify text into processable objects;
[0043] In text processing, firstly text needs to be quantized into processable objects, preferably, the method of constructing a vector space model (VSM for short) in text processing is adopted, including: 1, text ...
Embodiment 2
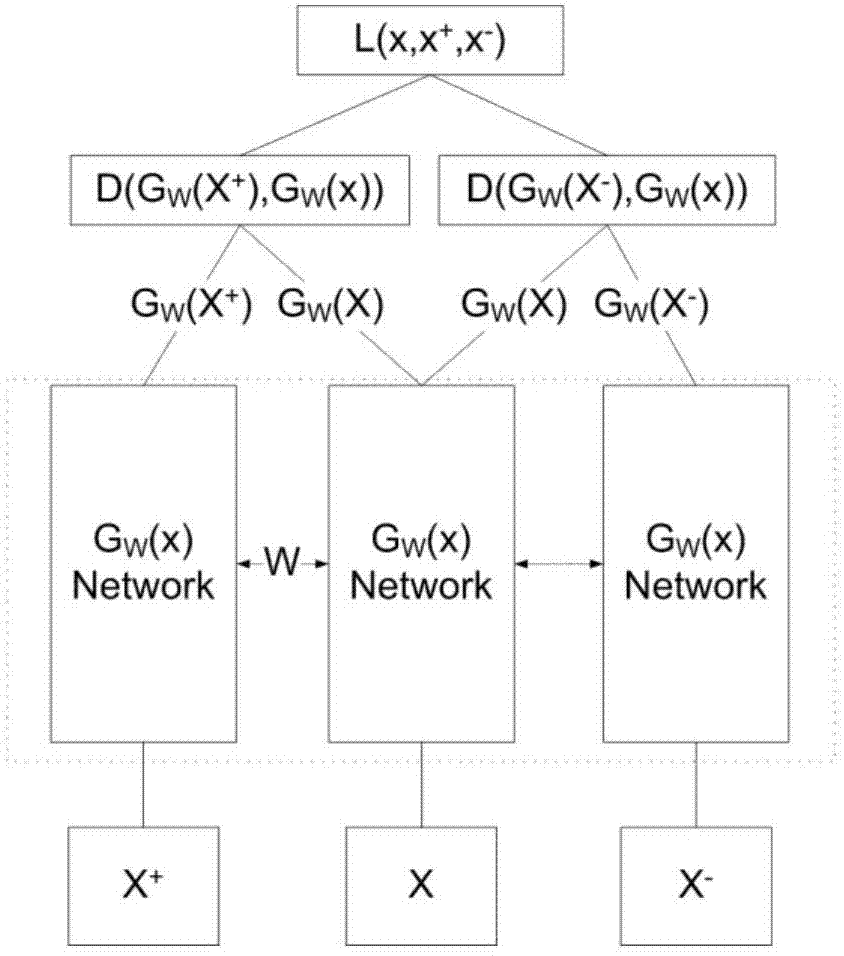
[0074] In this embodiment, on the basis of Embodiment 1, in order to make the training model more flexible, the weights in the three branches of the Siamese network can be different, and the number of layers is different, that is, the three functions are not related to each other; only in the final distance Calculate and associate them together; other content that is not described repeatedly is the same as that in Embodiment 1. Specifically, such as Image 6 Shown, this embodiment preferably, in figure 1 The calculation of the cosine of the corresponding angle in S3 and S4 adopts the ternary metric function, and the triplet samples (x', x, x') have different network parameters W after feature extraction, and the semantic feature expression of the three samples is obtained , respectively denoted as
[0075] G w1 (x'), G w2 (x), G w3 (x');
[0076] When D(G w1 (x'),G w2 (x))-D(G w3 (x'),G w2 (x)) > α, it is judged as similar, otherwise it is judged as dissimilar; where...
Embodiment 3
[0079] As technical documents for software development, especially those used in the field of nuclear power, the documents should be compiled in accordance with the standard specifications, and the titles should be highly generalized and similar. Processing will greatly lose the important information brought by the title to the classification. Therefore, the contribution of paragraph titles to the text similarity measure should be properly considered during training and testing. Such as Figure 7 As shown, in this embodiment, preferably, a pair of text is selected as an input in step S2 corresponding to embodiment 1 or embodiment 2, denoted as (x i ,x j ); Divide the paragraph title and text of the text into two parts, and at the same time, merge the text and title of the two texts as input.
[0080] Specifically, first select a pair of texts as input, denoted as, can be similar or dissimilar, divide the paragraph title and text of the text into two parts, and at the same t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com