


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Sliding window sampling-based distributed machine learning training method and system thereof
A machine learning and sliding window technology, applied in machine learning, instruments, computing models, etc., can solve the problem of poor stability and convergence effect of distributed asynchronous training, inability to perceive the context information of the expired degree of the learner gradient, and expired gradient processing Too simple and other problems to achieve the effect of alleviating poor training convergence, reducing training fluctuations, and improving robustness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
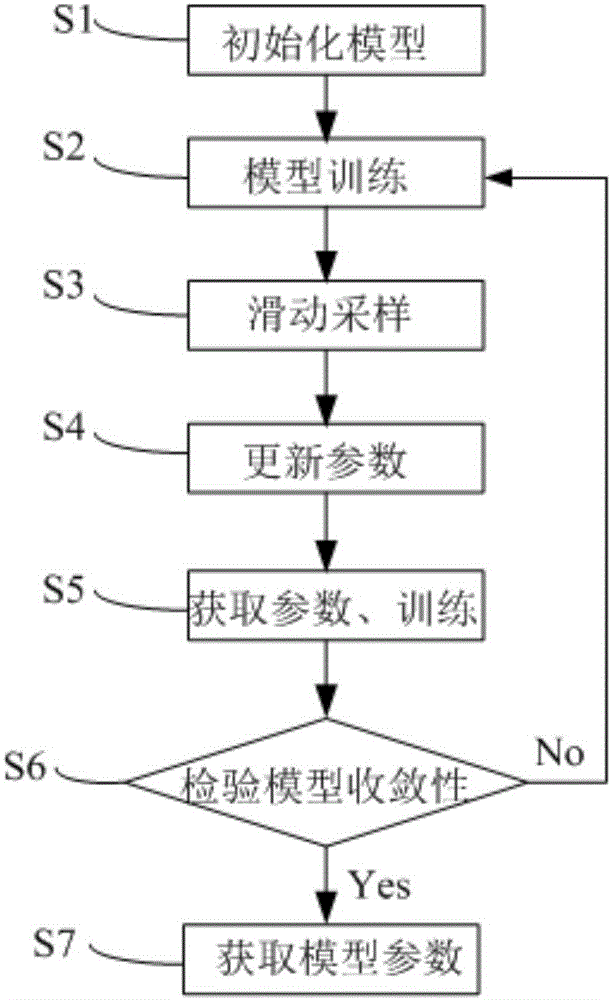
[0026] see figure 1 , is a flow chart of a distributed machine learning training method based on sliding window sampling in an embodiment of the present invention. Method of the present invention comprises the following steps:
[0027] S1, machine learning model parameter initialization;
[0028] S2, obtain a data slice of all data, and perform model training independently;
[0029] S3, collect several rounds of gradient expiration degree samples in the history, sample samples by sliding, and calculate the gradient expiration degree context value, adjust the learning rate and initiate a gradient update request;
[0030] S4, asynchronously collect multiple gradient expiration degree samples, use the adjusted learning rate to update the global model parameters and push the updated parameters;
[0031] S5, asynchronously obtain the pushed global parameter update, and continue the next training;
[0032] S6, check model convergence, if not convergent, enter the step 2) loop; i...
Embodiment 2
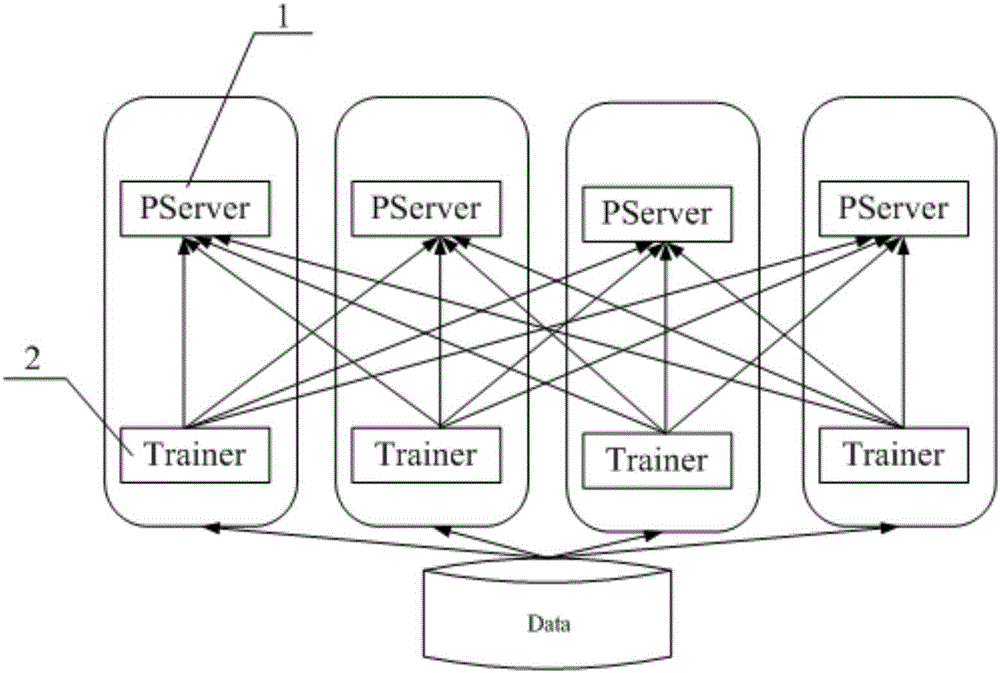
[0041] In addition, the present invention also provides a distributed machine learning training system based on sliding window sampling using the above method, please refer to figure 2 , the system includes: a server node 1, the server node 1 collects several gradient update requests asynchronously, updates and saves the global model parameters, and passively pushes updated parameters to the client; a learner node 2, each of the learning The server node 2 obtains a data slice of all the data, and performs model training independently. After each round of training, it uses the adjusted learning rate to initiate a gradient update to the server node 1, and asynchronously obtains the update pushed by the server node 1. Parameters, initiate the next round of training; sliding sampling module (not shown), the sliding sampling module is attached to the learner node 2, used to complete the sampling of the previous rounds of gradient expiration degree samples, and calculate the gradien...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com