Text recommendation method and device based on contents and user behaviors
A recommendation method and text technology, applied in special data processing applications, instruments, electrical and digital data processing, etc., can solve the problems of not meeting the individual needs of users, unable to solve information overload, and unable to obtain different results.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
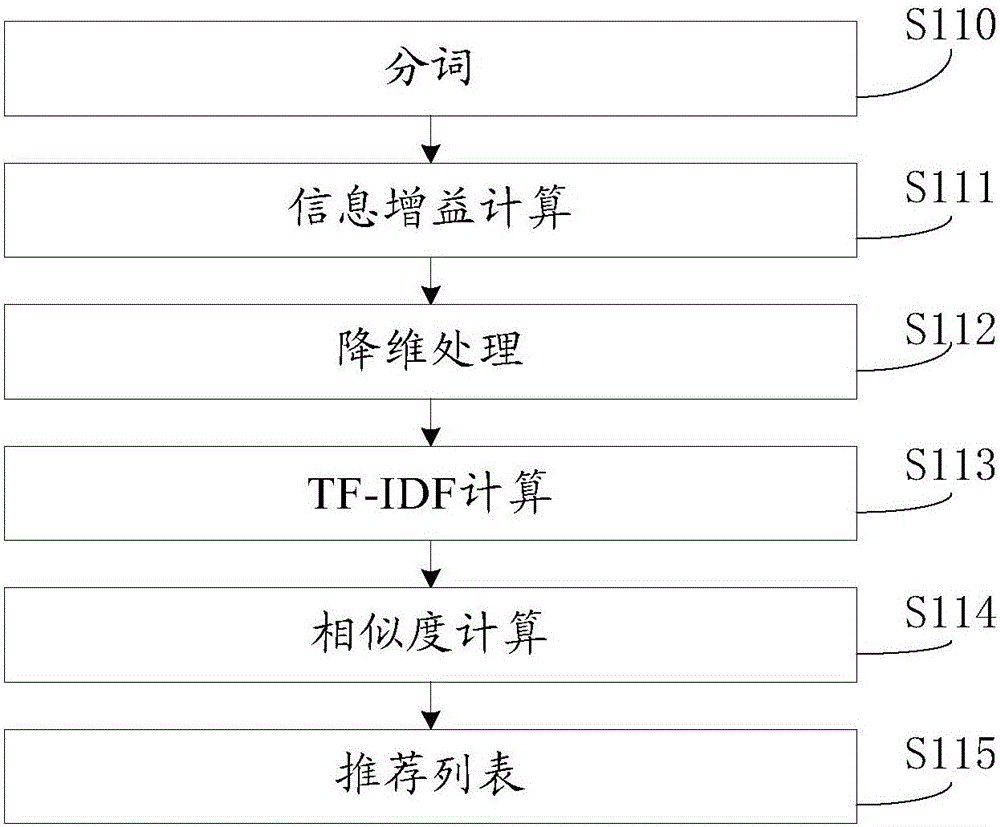
[0052] see figure 1 As shown, the method provided by Embodiment 1 of the present invention includes steps:
[0053] In step S110, the document collection to be analyzed is obtained, and Chinese word segmentation is performed on the documents in the document collection to obtain multiple terms.
[0054] Step S111, perform information gain calculation on the terms in the document collection, sort and filter multiple terms according to the size of the information gain as the reference vector.
[0055] Step S112, according to the reference vector, convert the text in the document collection into a multi-dimensional space vector model.
[0056] Step S113, perform TF-IDF calculation on the space vector model to obtain a text vector matrix.
[0057] Step S114, calculating the similarity between different text vector matrices to form a document relationship matrix.
[0058] Step S115, analyzing the user behavior data, combining with the document relationship matrix, forming a recom...
Embodiment 2
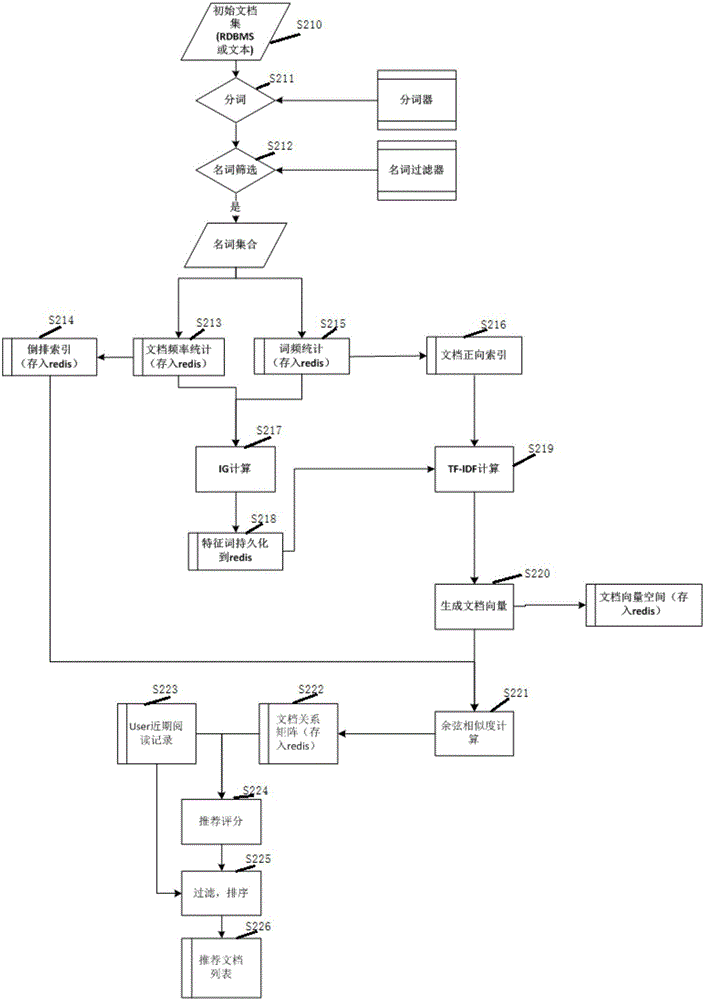
[0088] For the flow of the method for text recommendation based on content and user behavior provided in Embodiment 2 of the present invention, please refer to figure 2 shown, including:
[0089] Step S210, obtain the initial document set, which is RDBMS or text.
[0090] Step S211, using a tokenizer to perform Chinese word segmentation on the initial document set.
[0091] Step S212, using a noun filter to filter nouns to obtain a noun set.
[0092] In step S213, the document frequency statistics are performed and stored in redis, and then steps S214 and S217 are entered.
[0093] Step S214, perform an inverted index and store the index result in redis, and go to step S221.
[0094] In step S215, word frequency statistics are performed and stored in redis, and then steps S216 and S217 are entered.
[0095] Step S216, perform forward indexing of the document, and then proceed to step S219.
[0096] Step S217, perform IG calculation.
[0097] In step S218, the feature wo...
Embodiment 3
[0108] An embodiment of the present invention further provides an apparatus for text-based recommendation based on content and user behavior, see Image 6 shown, including:
[0109] A word segmentation module, used to obtain the document set to be analyzed, and perform Chinese word segmentation on the documents in the document set to obtain a plurality of terms;
[0110] The IG calculation module is used to perform information gain calculation on the terms in the document set, and sort and filter multiple terms as reference vectors according to the size of the information gain;
[0111] A dimensionality reduction module for converting the text in the document collection into a multi-dimensional space vector model according to the reference vector;
[0112] The TF-IDF calculation module is used to perform TF-IDF calculation on the space vector model to obtain a text vector matrix;
[0113] The similarity calculation module is used to calculate the similarity between different t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com