Audio classification method and apparatus thereof
A classification method and audio technology, applied in speech analysis, speech recognition, instruments, etc., can solve the problem of low audio classification accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
[0025] refer to figure 1 , which shows a flow chart of the steps of Embodiment 1 of an audio classification method of the present invention, which may specifically include:
[0026] Step 101. According to the collected training data, an audio classification model is obtained based on deep neural network training;
[0027] Step 102, extracting audio features to audio data;
[0028] Step 103: Input the audio feature into the audio classification model, and output the classification result of the audio data; the classification result includes: recording audio, voice search song audio and humming audio.
[0029] The embodiment of the present invention can be used to classify audio data through a smart terminal. Specifically, firstly, an audio classification model based on a deep neural network can be trained on the smart terminal according to the collected training data, then the audio features are extracted from the audio data to be classified, and finally the extracted audio f...
Embodiment 2
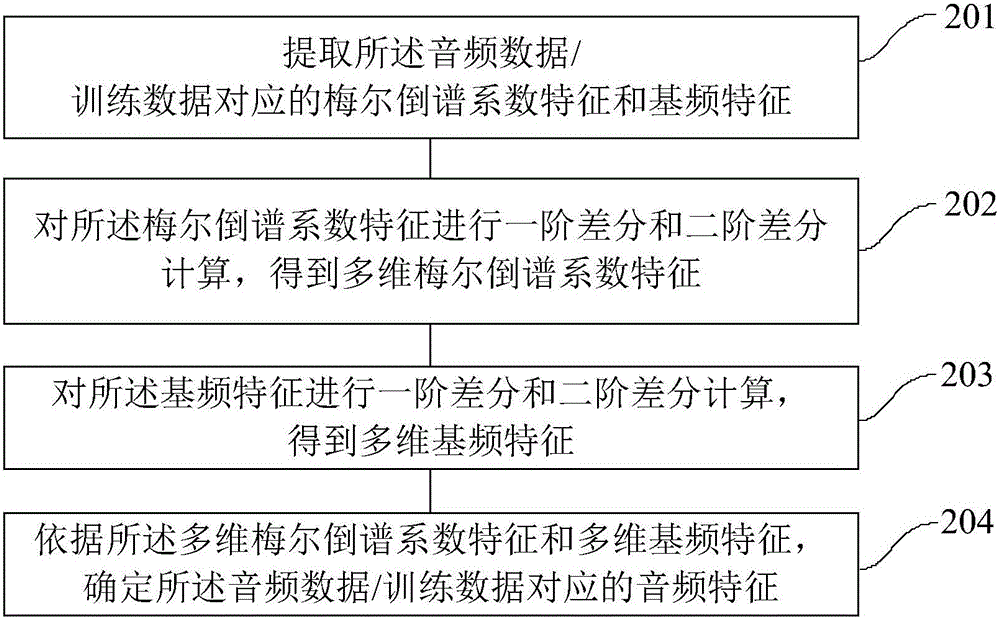
[0038] On the basis of the first embodiment above, this embodiment describes the specific process of extracting the audio features corresponding to the audio data; For the fundamental frequency features of humming audio and voice search audio with smaller frames, this embodiment further dynamically expands the extracted audio features by calculating the first-order and second-order difference operations, so that the audio features are more prominent, and finally combined into 42 Dimensional audio features.
[0039] refer to figure 2 , which shows a flow chart of the steps of an embodiment of a method for extracting audio features from audio data according to the present invention, which may specifically include:
[0040] Step 201, extracting the Mel cepstral coefficient feature and fundamental frequency feature corresponding to the audio data / training data;
[0041] In order to solve the problem of low accuracy in classifying voice search song audio and humming audio in the p...
Embodiment 3
[0068] This embodiment describes the training process of the audio classification model on the basis of the first embodiment above. refer to image 3 , which shows a flow chart of the steps of an embodiment of a training method for an audio classification model of the present invention, which may specifically include:
[0069] Step 301, collecting training data; the training data may specifically include: recording audio, voice search song audio and humming audio;
[0070] In the embodiment of the present invention, the collected training data may specifically include recording audio, voice search song audio, and humming audio, so as to meet common audio classification requirements. In order to enable the trained classification model to better avoid the interference caused by noise and silence, the embodiment of the present invention can also collect noise audio and mute audio as training data, and further, can also split the humming audio For singing audio and humming audio...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com