Data quality detection method and device of duplicated data
A technology of data quality and detection method, applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., can solve problems such as rapid detection, achieve the effects of saving time, simple formulas, and improving detection efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
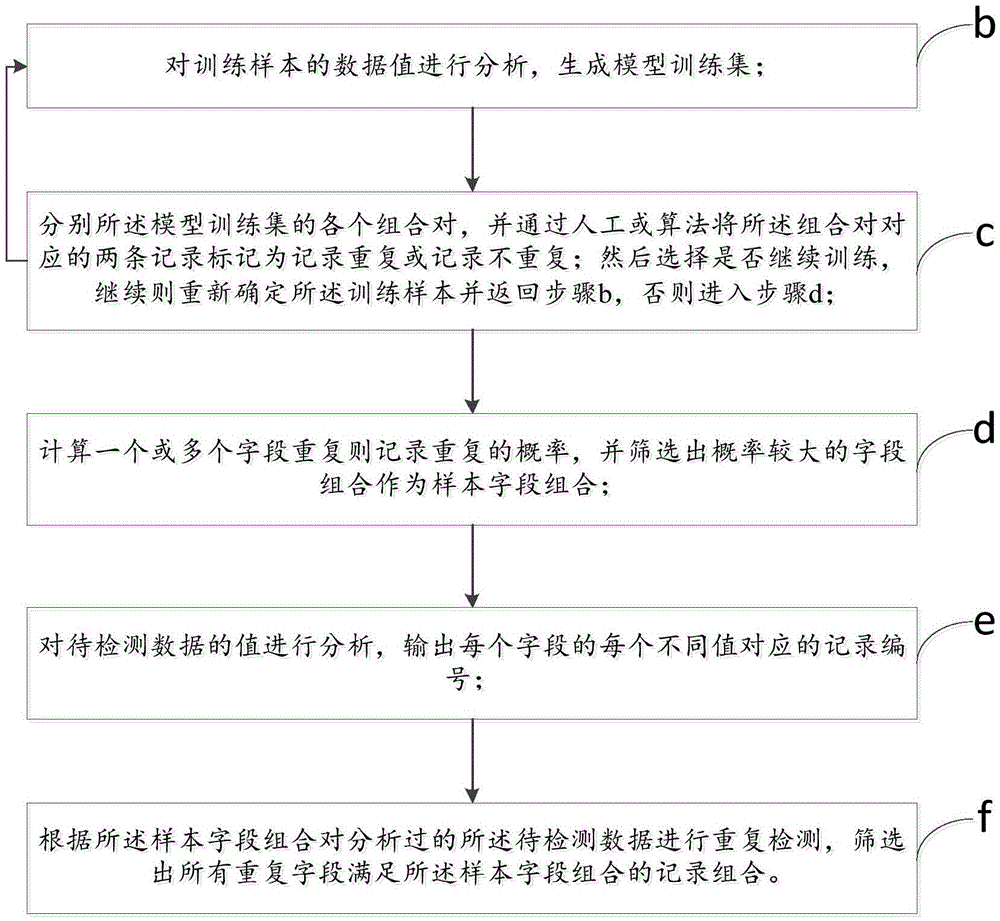
[0153] The data quality detection method for repeated data as described above, the difference of this embodiment is that, as Figure 9 As shown in the flow chart of Embodiment 1 of the data quality detection method of repeated data in the present invention; the data quality detection method also includes:
[0154] Step g, outputting the reserved record combination and the probability of repetition of the record combination, the step g is after the step f.
[0155] The output in this step can be in different forms, can be displayed in a visual form, and can also output detection results to facilitate the merging of records; it can output all of the retained record combinations and the probability of repeating the record combination, and can also output the retained Part of the record combination and the probability that the record combination repeats.
Embodiment 2
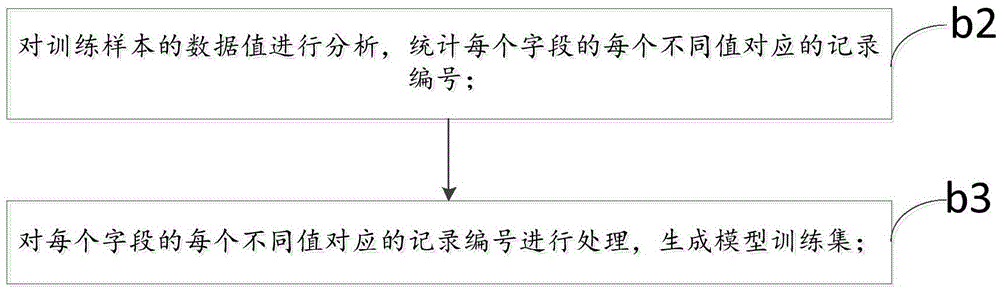
[0157] The data quality detection method for repeated data as described above, the difference of this embodiment is that, as Figure 10 As shown in the flow chart of Embodiment 2 of the data quality detection method for repeated data of the present invention; the step b also includes:
[0158] In step b1, the similarity is calculated for the values in the same field of the training samples, and the similar values whose similarity reaches or exceeds the threshold are taken as the same value, and the step b1 is before the step b2.
[0159] Here, an algorithm is used to calculate the similarity for some very similar values in each field, and the data quality analyst defines a threshold to determine the level of similarity and treat these values as the same value.
[0160] The algorithm for calculating the similarity is the Levenshtein algorithm, the longest common subsequence algorithm and other algorithms, and the specific algorithm can be selected according to actual ne...
Embodiment 3
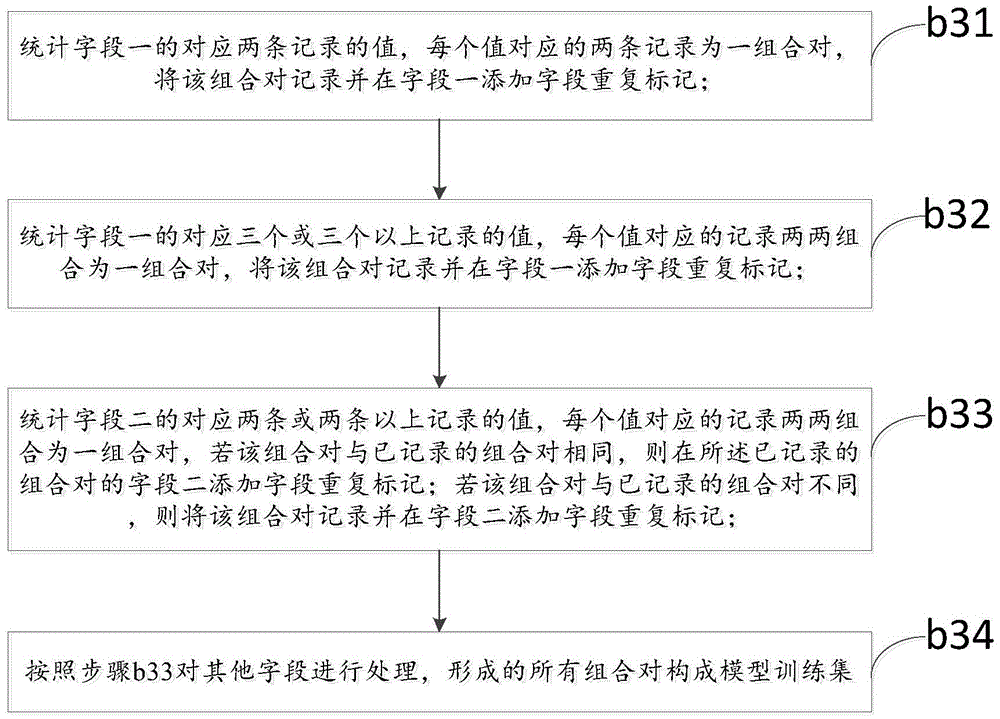
[0163] The data quality detection method for repeated data as described above, the difference of this embodiment is that, as Figure 11 As shown in the flow chart of Embodiment 3 of the data quality detection method for repeated data of the present invention; the data quality detection method also includes:
[0164] Step a, extracting training samples from the data source to be detected; said step a is before said step b;
[0165] There are multiple records in the data source with detection, and each record has a corresponding number, which is the record number; the record numbers are arranged in sequence and incremented in turn; each record is divided into multiple fields: field 1, field 2, field 3 , field 4, ..., so that the same field has a value in each record, how many records there are, and how many values each field has (the values here are the same or different), and the value of the field The number of corresponds to the number of the record; here, the first valu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com