Tag clustering method and system
A clustering method and labeling technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve problems such as inaccurate calculation of label similarity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
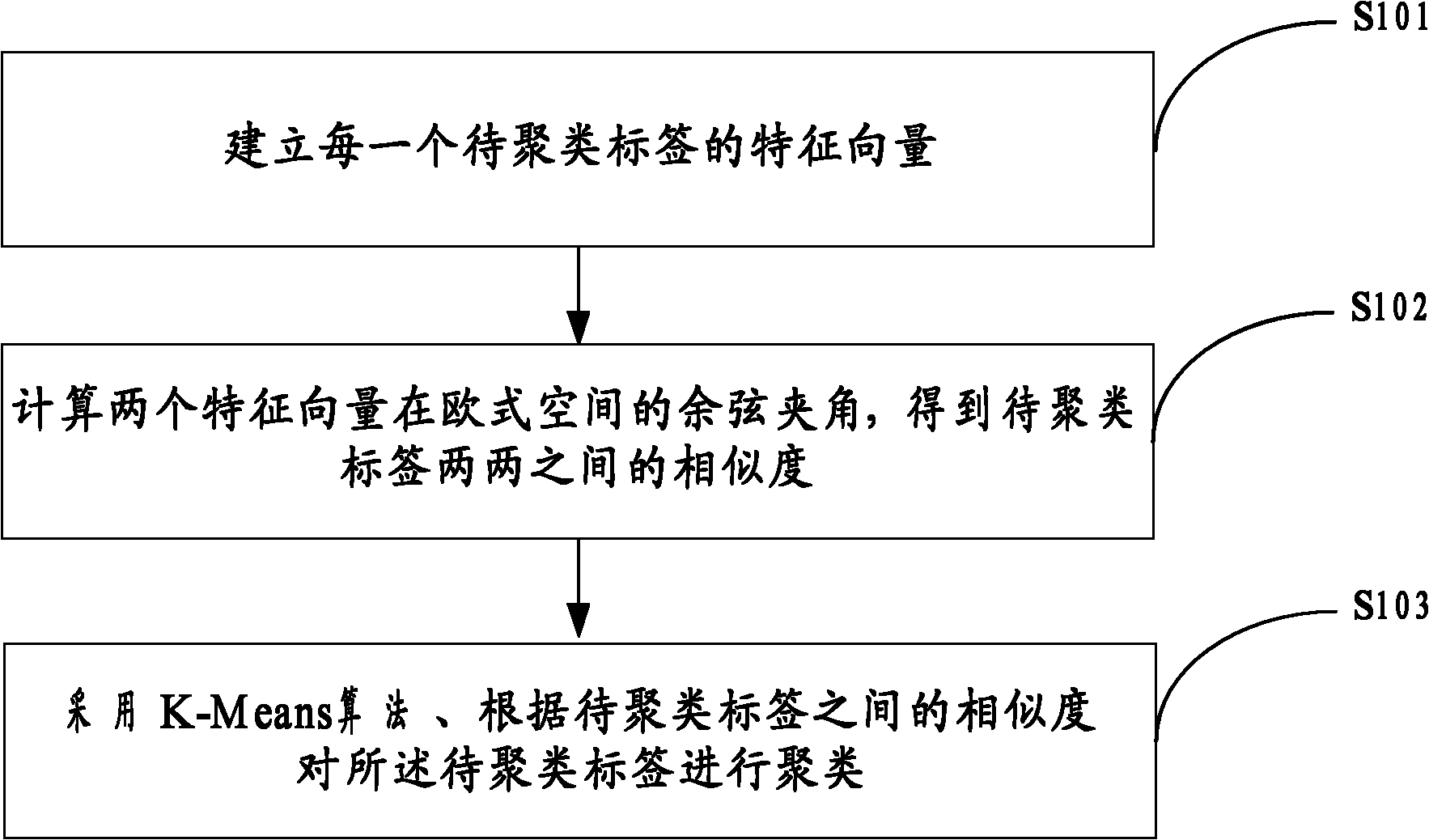
[0072] In order to improve the accuracy of the label clustering result, an embodiment of the present invention provides a label clustering method, see figure 1 As shown in the schematic flow chart, the method may specifically include the following steps:
[0073] Step S101: Establish a feature vector of each tag to be clustered.
[0074] In this step, each label to be clustered is modeled and represented by a multi-dimensional feature vector.
[0075] This embodiment specifically provides the following three methods for establishing feature vectors for the tags to be clustered:
[0076] Method 1: Resource-based feature vector representation (item-based-vector, IBV).
[0077] A resource is usually marked by several tags, and each tag has a certain relationship with the resource. Using the above relationship, it can be seen that a tag can also be represented by multiple resources related to it.
[0078] Based on the above idea, the present invention can use the feature vector composed of t...
Embodiment 2
[0122] Corresponding to the tag clustering method provided in the first embodiment, this embodiment provides a tag clustering system to improve the accuracy of tag clustering. See Figure 7 Shown is a schematic diagram of the structure of the system, which specifically includes:
[0123] The feature vector establishment module 701 is used to establish the feature vector of each tag to be clustered;
[0124] The similarity calculation module 702 is used to calculate the cosine included angle of the two feature vectors in the Euclidean space to obtain the similarity between the labels to be clustered;
[0125] The clustering module 703 is configured to use the K-Means algorithm to cluster the tags to be clustered according to the similarity between the tags to be clustered.
[0126] Based on the three methods for establishing feature vectors for the tags to be clustered provided in the first embodiment, the feature vector establishing module 701 may include any one or more of the follo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com