Audio frequency rapid classification method based on content
A rapid classification and audio technology, applied in the field of information processing, can solve the problems of complex classification, impossibility, and small number of classifications, and achieve high efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment approach 1
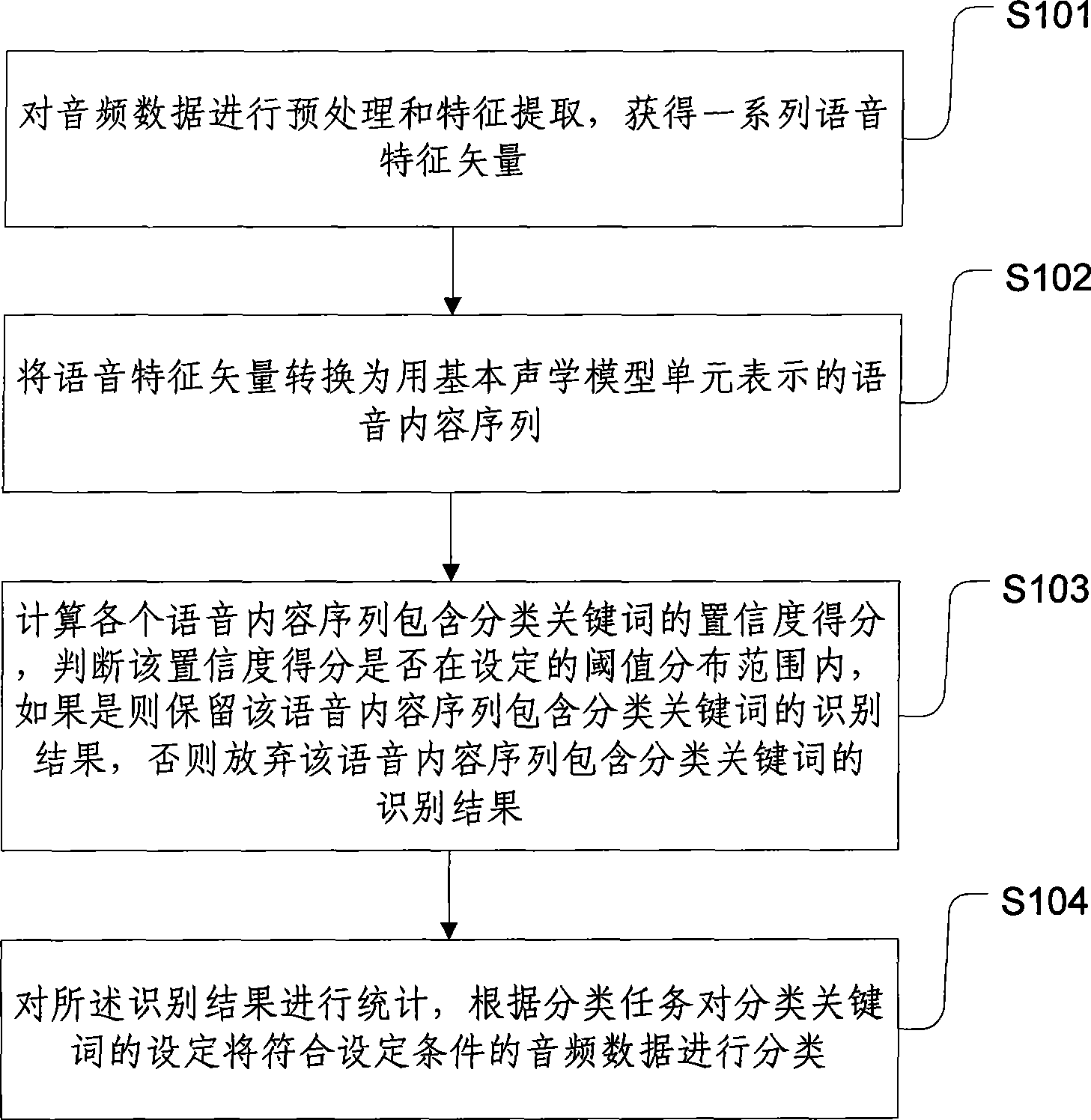
[0077] Embodiment 1: Convert the speech feature vector of the speech vector segment into a speech content sequence represented by basic acoustic model units (AU) according to the acoustic model, language model and dictionary.
[0078] Speech recognition of speech vector segments requires the use of acoustic models, language models, and dictionaries.
[0079] (1) Acoustic model (AM): The acoustic model includes several basic acoustic model units (AU). AU is the representation of the speech feature vector corresponding to the pronunciation unit (phonetic symbol) of each basic speech, which is complete and distinguishable.
[0080] Completeness: All possible pronunciation units (phonetic symbols) in speech have their corresponding speech feature vector representations.
[0081] Distinction: Different pronunciation units (phonetic symbols) should not be exactly the same.
[0082] Wherein, each pronunciation unit (phonetic symbol) AU corresponds to a segment of hundreds of voice f...
Embodiment approach 2
[0087] Embodiment 2: Convert the speech feature vector of the speech vector segment into a speech content sequence represented by basic acoustic model units (AU) according to the acoustic model and the dictionary.
[0088] Speech recognition of speech vector segments requires the use of acoustic models and dictionaries.
[0089] (1) Acoustic model (AM): The acoustic model includes several basic acoustic model units (AU). AU is the representation of the speech feature vector corresponding to the pronunciation unit (phonetic symbol) of each basic speech, which is complete and distinguishable.
[0090] Completeness: All possible pronunciation units (phonetic symbols) in speech have their corresponding speech feature vector representations.
[0091] Distinction: Different pronunciation units (phonetic symbols) should not be exactly the same.
[0092] Wherein, each pronunciation unit (phonetic symbol) AU corresponds to a segment of hundreds of voice feature vector sequences in the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com