


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
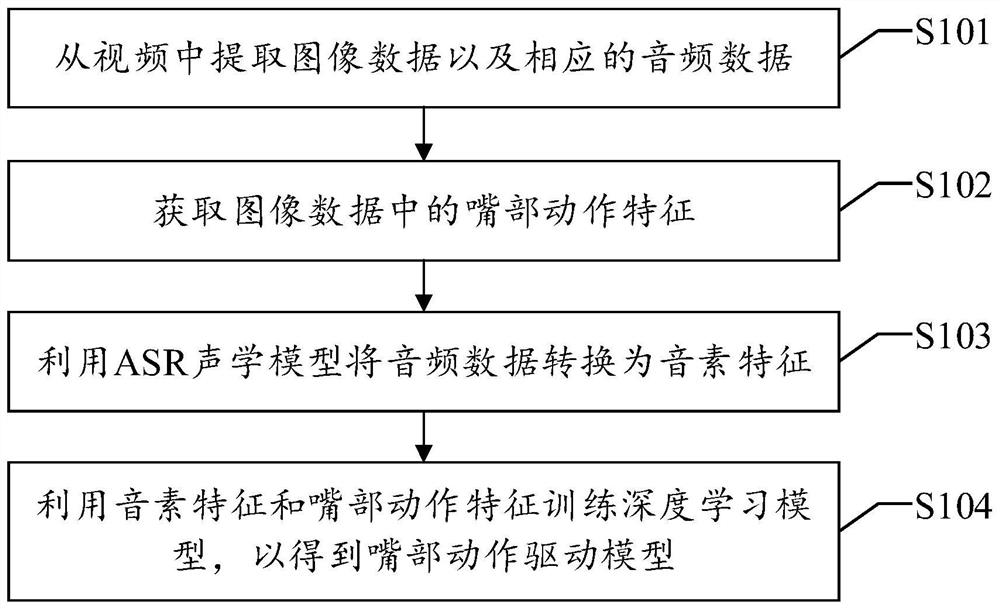
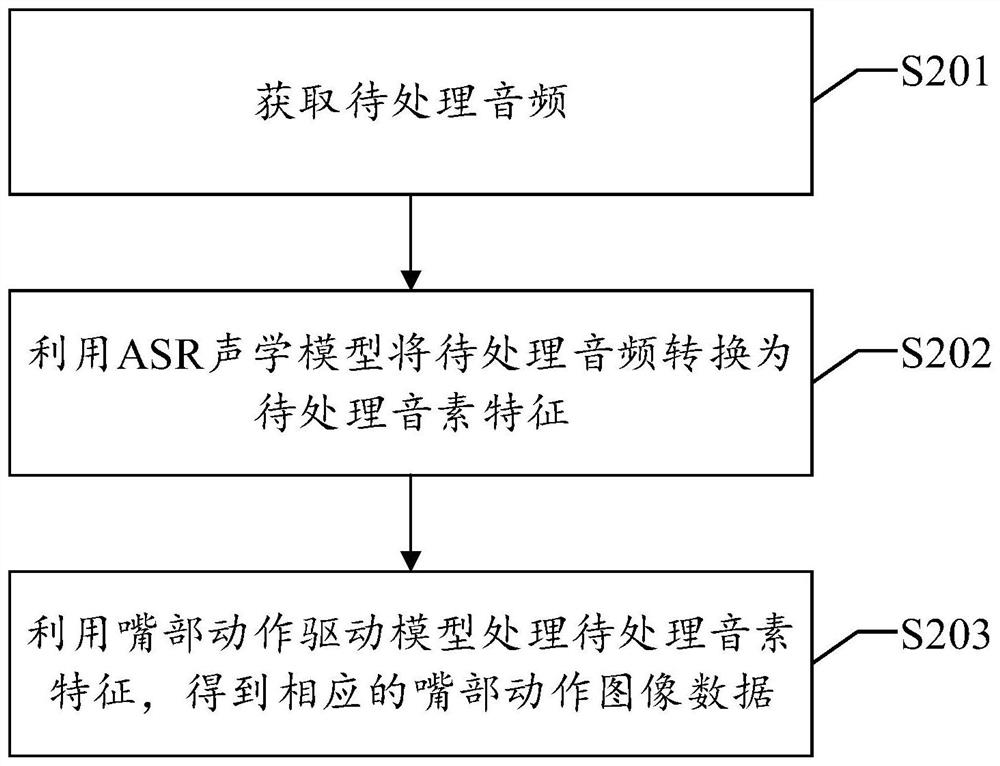
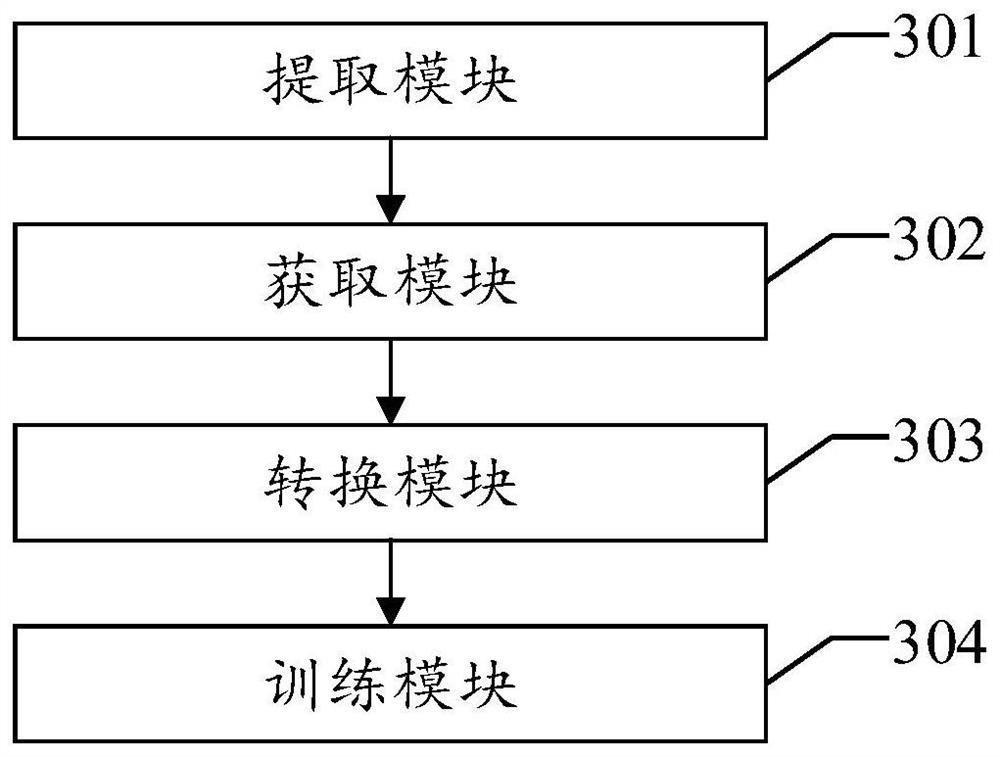
Mouth action driving model training method and assembly based on ASR acoustic model
An acoustic model, action-driven technology, applied in the computer field, can solve the problems of high cost, large training tasks, and the model cannot cover various sounds and scenes, and achieves the effect of improving quality, reducing complexity and training cost.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0072] The following will clearly and completely describe the technical solutions in the embodiments of the application with reference to the drawings in the embodiments of the application. Apparently, the described embodiments are only some of the embodiments of the application, not all of them. Based on the embodiments in this application, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the scope of protection of this application.
[0073] At present, the deep learning method directly uses audio to train the model. Because the audio itself carries noise, different audio and timbre differences, the model cannot cover various timbres and scenes. If the model is trained with multiple timbres and scenes, the training task will be large and the cost will be high. To this end, this application provides a mouth movement-driven model training scheme based on the ASR acoustic model, which can reduce the complexity of tr...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com