


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Cache value-based Spark cache elimination method and system
A cache and value technology, applied in the field of big data computing, can solve problems such as ignoring future reuse times, inaccurate calculation costs, and weakened computing power, so as to improve computing speed, optimize memory resource utilization, and reduce running time.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0040] The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
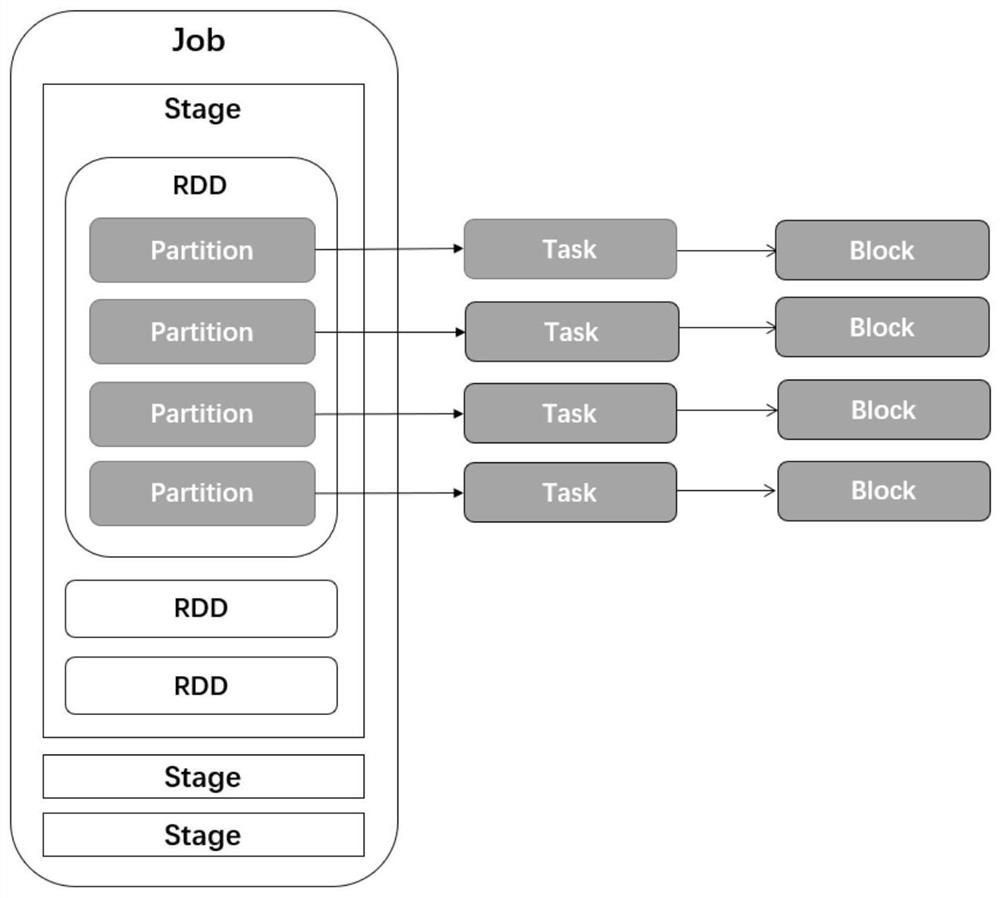
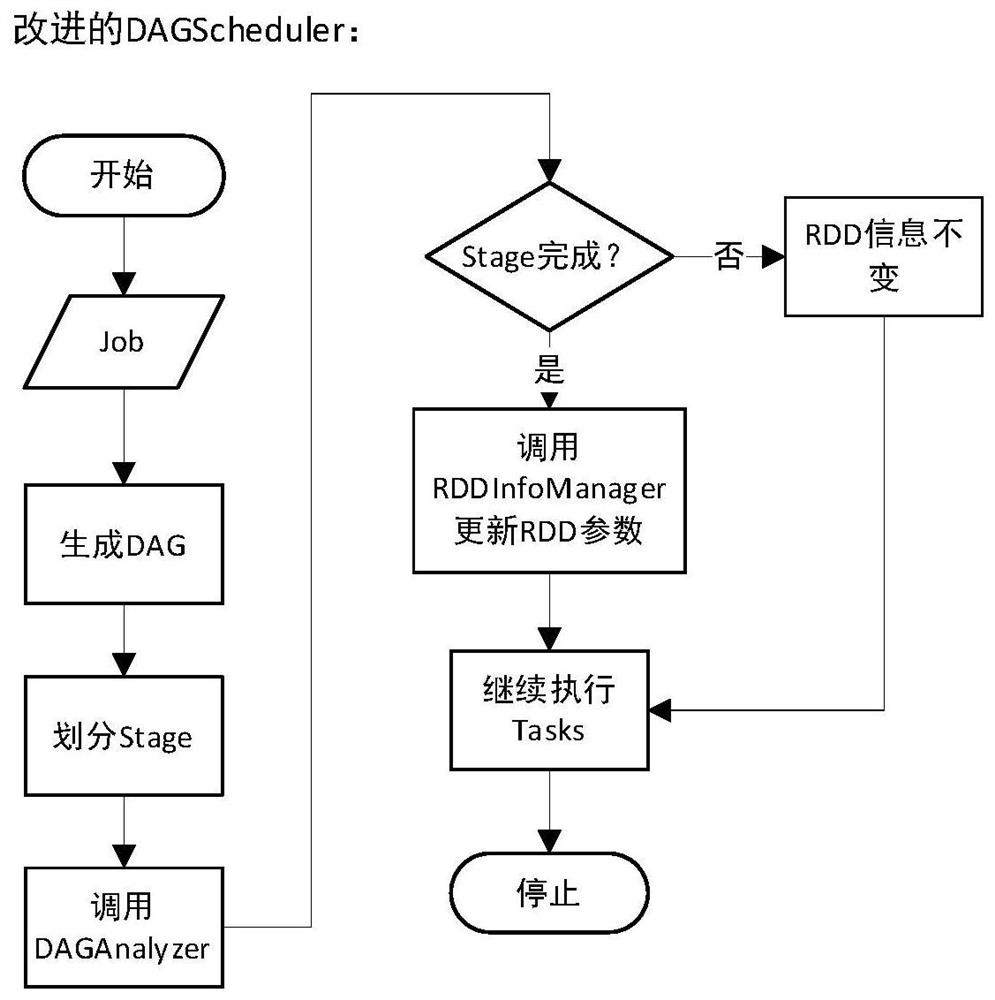
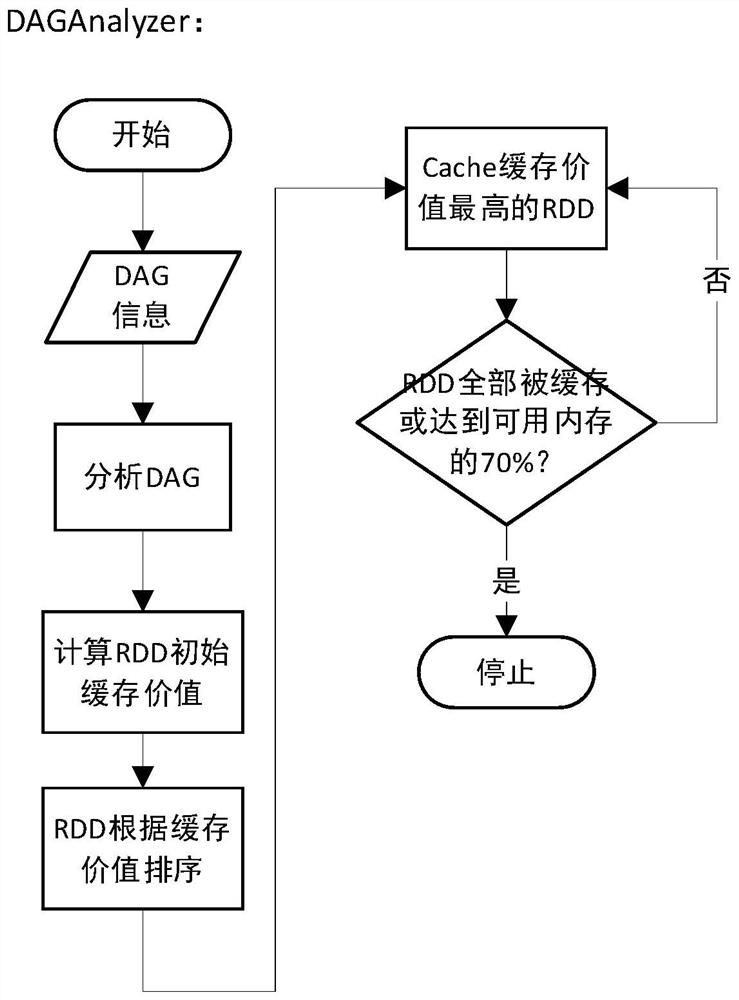
[0041] The present invention provides a Spark cache elimination method and system based on cache value. According to the DAG graph of Spark Job, the usage of RDD and Block in Job is obtained, and the cache value of RDD and Block is defined. The cache value referred to in this specification is high Including: the RDD or Block that is most frequently used and the closest calculation has a high cache value; if the cache value of a Block is zero, it means that the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com