Speech training data processing method, device and storage medium
A technology of speech training and processing method, which is applied in the field of data processing, can solve the problems of expensive speech materials, achieve extremely low cost and solve expensive effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
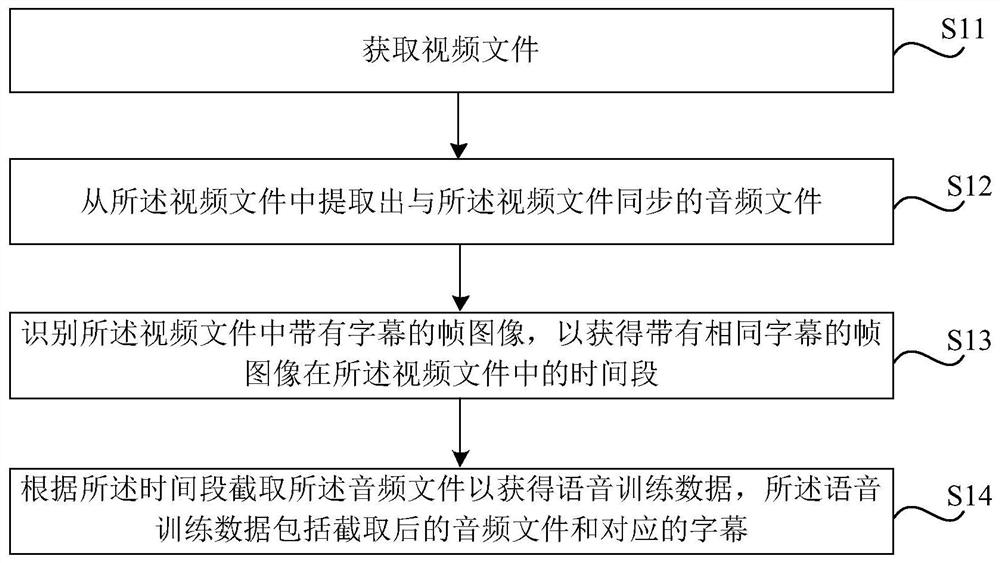
[0045] figure 1 It is a flow chart of a method for processing voice training data shown in an exemplary embodiment of the present disclosure to solve the technical problem in the related art that the voice material used for training a voice recognition model is expensive. Such as figure 1 Shown, the processing method of this speech training data comprises:
[0046] S11, acquiring a video file.
[0047] S12. Extract an audio file synchronized with the video file from the video file.
[0048] S13. Identify the frame images with subtitles in the video file, so as to obtain the time period of the frame images with the same subtitles in the video file.
[0049] S14. Intercept the audio file according to the time period to obtain speech training data, where the speech training data includes the intercepted audio file and corresponding subtitles.
[0050] In step S11, the video file can be obtained from the stored video database, or a preset video download website can be provided...
Embodiment 2
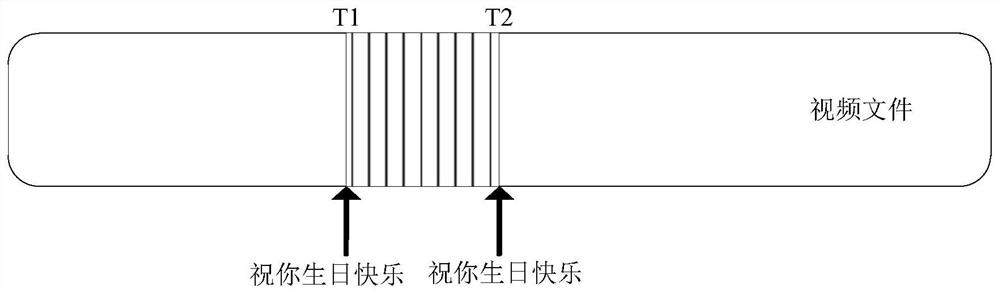
[0061] figure 2 It is a schematic diagram of identifying the same subtitle for a video file according to an exemplary embodiment of the present disclosure. In order to solve the technical problem of expensive speech materials used in training speech recognition models in the related art, the figure 2 As an example, the processing method of the speech training data disclosed in the present disclosure is described:
[0062] First, input a video file; then, strip out the entire audio file corresponding to the video file as a backup, since the technology of extracting synchronous audio from the video file is a known technology, it will not be described in detail in this embodiment; then, Use image recognition technology to identify each frame of the video file, such as figure 2 As shown, the words "Happy Birthday to you" are recognized, and the frequency frame with "Happy Birthday to you" is recognized for the first time at this time as A, and the time point corresponding to ...
Embodiment 3
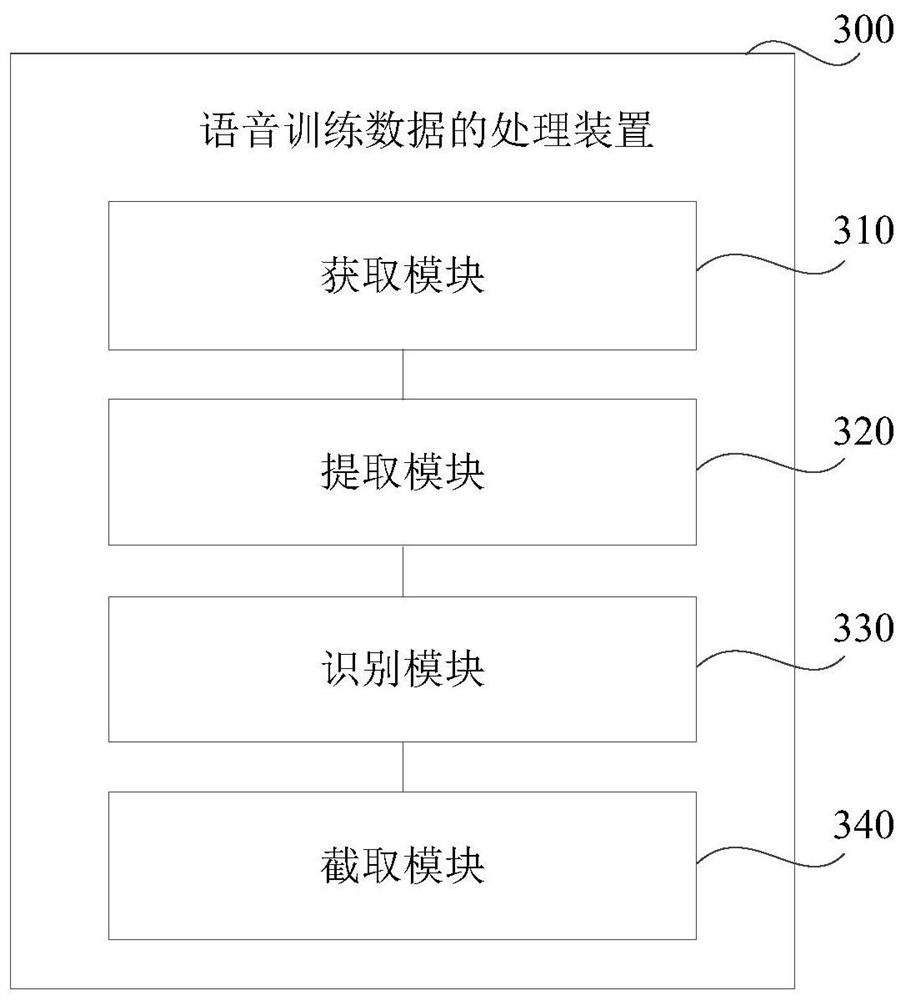
[0065] image 3 It is a speech training data processing device shown in an exemplary embodiment of the present disclosure to solve the technical problem in the related art that speech materials used for training a speech recognition model are expensive. Such as image 3 As shown, the processing device 300 of the voice training data includes:
[0066] Obtaining module 310, configured to obtain video files;
[0067] An extraction module 320 configured to extract an audio file synchronized with the video file from the video file;
[0068] The identification module 330 is configured to identify the frame images with subtitles in the video file, so as to obtain the time period of the frame images with the same subtitles in the video file;
[0069] The intercepting module 340 is configured to intercept the audio file according to the time period to obtain speech training data, and the speech training data includes the intercepted audio file and corresponding subtitles.
[0070] ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com