Method, system, medium and device for multi-emotion recognition combining voice and text
A speech emotion recognition and emotion recognition technology, applied in the field of human-computer interaction, can solve the problems of inability to handle multi-emotion recognition tasks, difficult to apply, afraid and not afraid, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
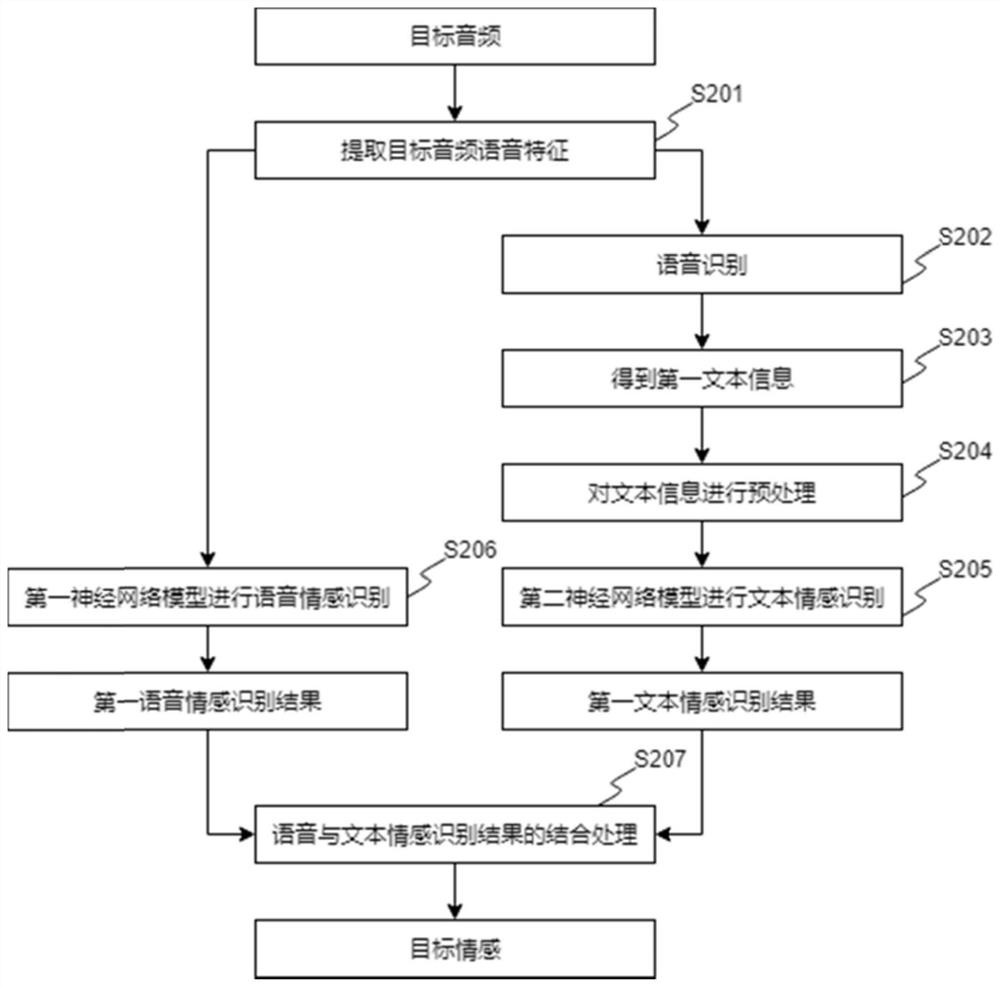
[0049] Such as figure 1 As shown, the multi-emotion recognition method of combining speech and text in the present embodiment 1 comprises the following steps:
[0050] Step S201, acquiring target audio;
[0051] When acquiring the target audio, it can be acquired actively by the terminal or passively through user operation instructions, or audio sent from other sources, or a collected audio corpus. The function of obtaining the target audio is to identify the emotional information in it, and to obtain the text information in it for text emotion recognition. The above text information includes but not limited to a sentence, a paragraph or a chapter.
[0052] Emotional information refers to the personal emotions that the speaker wants to express during oral expression, such as emotions, anger, sorrow, and joy.
[0053] Step S202, extracting the speech features of the target audio;
[0054] The purpose of acquiring the speech features is to generate the input of the first neu...
Embodiment 2
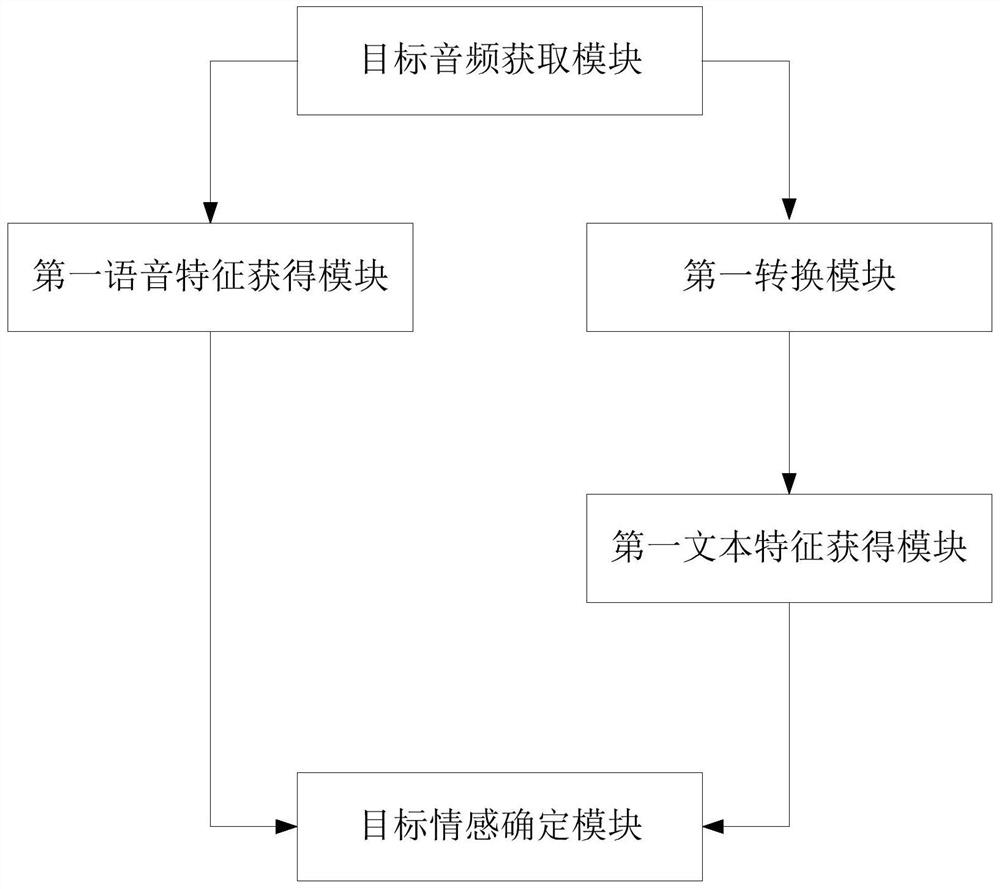
[0088] Such as image 3 As shown, the present embodiment provides a multi-emotion recognition system combining voice and text, the system includes a target audio acquisition module, a first conversion module, a first speech feature acquisition module, a first text feature acquisition module, and a target situation Determine the module, and the specific functions of each module are as follows:
[0089] The target audio acquisition module is used to acquire target audio, the target audio is composed of a plurality of audio segments, and the target audio includes the first voice feature;
[0090] The first conversion module is configured to convert first text information from the target audio, and the first text information includes first text features;
[0091] The first speech feature obtaining module is used to obtain first speech emotion recognition information based on the first speech feature;
[0092] The first text feature obtaining module is used to obtain first text e...
Embodiment 3
[0097] This embodiment provides a storage medium, the storage medium stores one or more programs, and when the programs are executed by the processor, the multi-emotion recognition method combining voice and text in the above-mentioned embodiment 1 is realized, as follows:
[0098] Obtain target audio, the target audio is made up of a plurality of audio segments, and the target audio contains the first speech feature;
[0099] Converting first text information from the target audio, the first text information includes a first text feature;
[0100] Obtaining first speech emotion recognition information based on the first speech feature;
[0101] Obtaining first text emotion recognition information based on the first text features;
[0102] Determine the target emotion of the target audio based on the first speech emotion recognition information and the first text emotion recognition information.
[0103] The storage medium described in this embodiment may be ROM, RAM, magnet...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com