


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Method, device and electronic equipment for generating a speech recognition model
A speech recognition model and speech frame technology, applied in speech recognition, speech analysis, instruments, etc., can solve problems such as parallel computing difficulties, error accumulation, and large computing resource consumption, so as to improve accuracy and recognition effect, and alleviate error accumulation Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
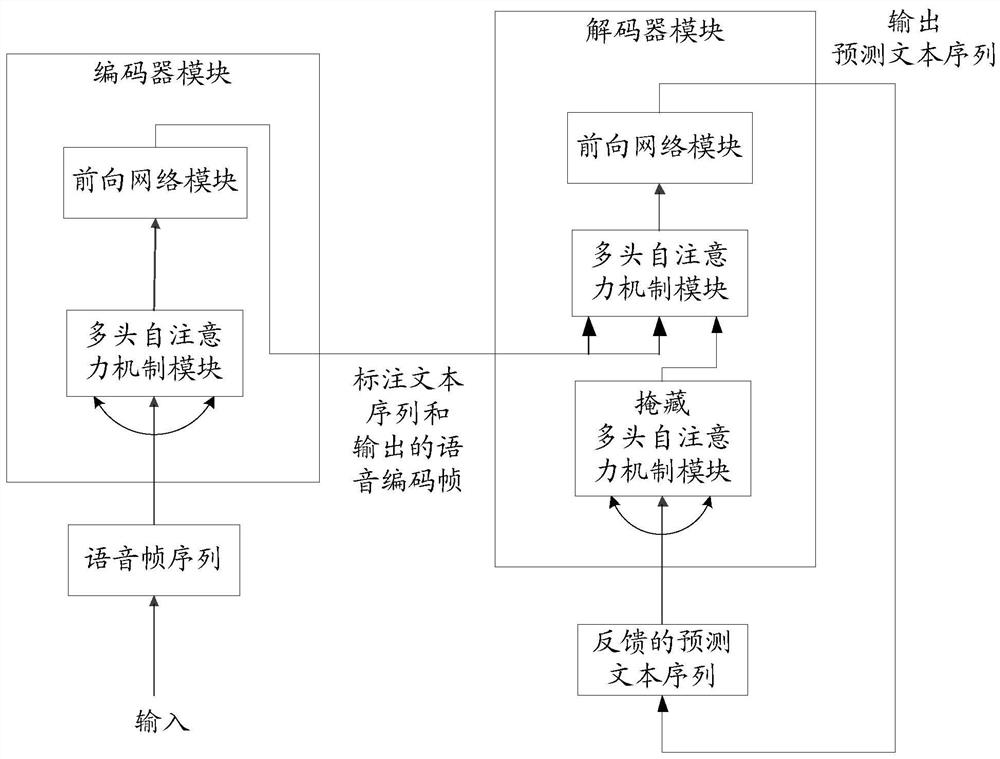
[0057] At present, when the end-to-end framework based on the codec attention mechanism is used for speech recognition, there are still the following defects:
[0058] On the one hand, the encoding and decoding functions in the current speech recognition neural network model are all realized based on the recurrent neural network structure, and the recurrent neural network has problems such as large consumption of computing resources and difficulty in parallel computing;
[0059] On the other hand, when the current speech recognition neural network model is training the model, the labeled text data corresponding to the input speech frame can ensure that the output at the previous moment must be correct, so the model training process does not consider When the output at the previous moment is wrong, how to train the model can still get the correct output result. As a result, when using the trained model for speech recognition, there will be an output error at the previous moment,...
Embodiment 2
[0101] Based on the same inventive concept, the embodiment of the present disclosure also provides a device for generating a speech recognition model, since the device is the device in the method in the embodiment of the present disclosure, and the problem-solving principle of the device is similar to the method, Therefore, the implementation of the device can refer to the implementation of the method, and the repetition will not be repeated.
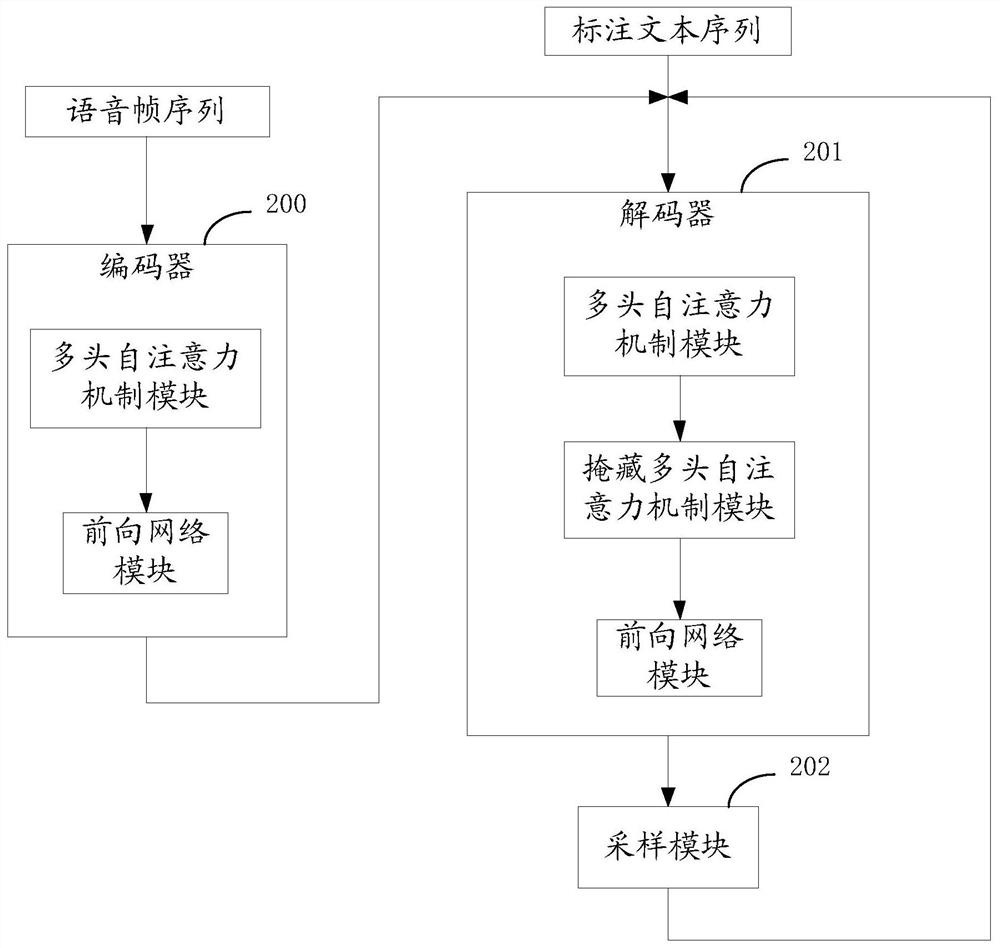
[0102] Such as Figure 4 As shown, the speech recognition model includes an encoder and a decoder, and the device includes: an acquisition sample unit 400, an encoder training unit 401, and a decoder training unit 402, wherein:
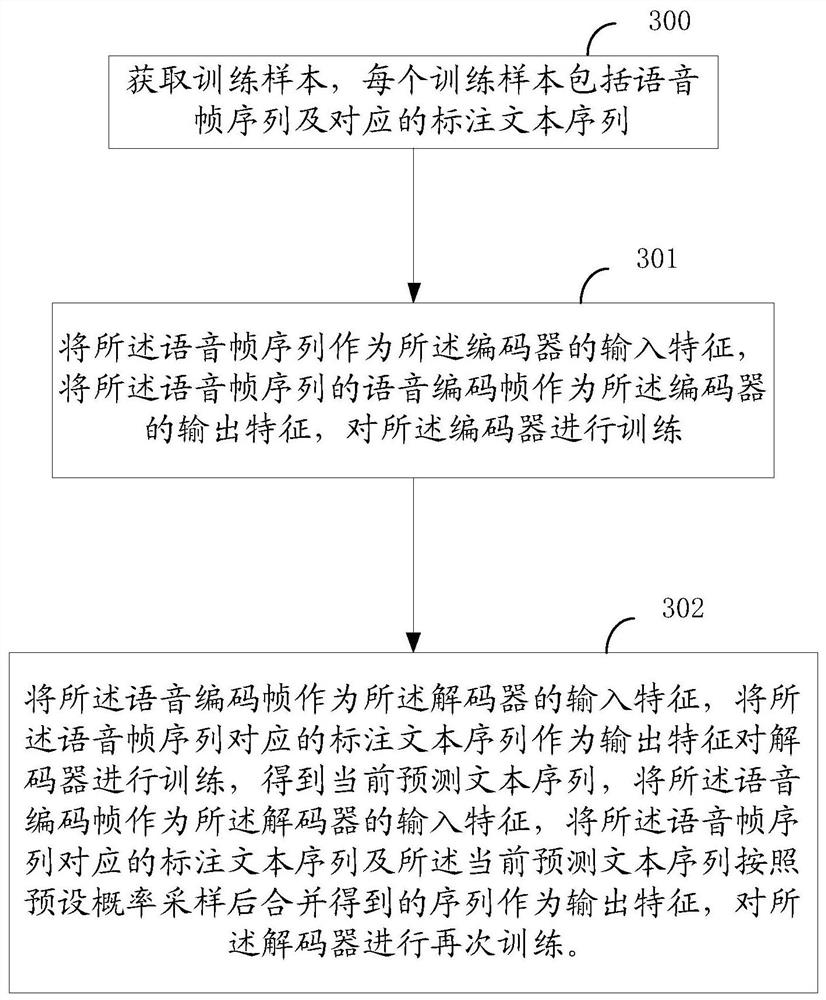
[0103] The obtaining sample unit 400 is configured to perform obtaining training samples, each training sample includes a speech frame sequence and a corresponding labeled text sequence;
[0104] The encoder training unit 401 is configured to use the speech frame sequence as the input feature of the encoder, a...
Embodiment 3
[0116] Based on the same inventive concept, an embodiment of the present disclosure also provides an electronic device, since the electronic device is the electronic device in the method in the embodiment of the present disclosure, and the problem-solving principle of the electronic device is similar to the method, so For the implementation of the electronic device, reference may be made to the implementation of the method, and repeated descriptions will not be repeated.
[0117] Such as Figure 5 As shown, the electronic equipment includes:
[0118] Processor 500;
[0119] A memory 501 for storing instructions executable by the processor 500;
[0120] Wherein, the processor 500 is configured to execute the instructions to implement the following steps:
[0121] Obtain training samples, each training sample includes a speech frame sequence and a corresponding labeled text sequence;
[0122] Using the speech frame sequence as the input feature of the encoder, using the spee...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com