Multi-angle and multi-mode fused image description generation method and system
An image description and multi-modal technology, applied in the field of image processing, can solve the problems of single angle of image description content, lack of content, and inability to fully describe image content, etc., to achieve the effect of eliminating redundancy and improving learning ability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0030] Such as figure 1 As shown, someone will see an adult wearing a blue shirt and a blue baseball cap, someone will see a child holding a doll, someone will see a red car next to an adult, someone will see a white car next to a red car, The scenes that people see are all the pictures shown on the image, but the viewing angles are different. figure 1 (a)-(d) are different objects identified from the figure respectively, for figure 1 A corresponding descriptive statement may include:
[0031] 1.a man in a blue shirt playing frisbee with a little boy in the park.
[0032] 2.a red car beside the man dressing a blue shirt in the park.
[0033] 3.a little boy holding a toy in the park.
[0034] 4.a white beside the tree in the park.
[0035] The purpose of this embodiment is to learn a complete image description from multiple perspectives by combining image and text modalities, so as to fully express the content contained in the image. Based on this, this embodiment disclos...
Embodiment 2
[0080] The purpose of this embodiment is to provide an image description generation system that integrates multiple angles and multiple modalities.
[0081] In order to achieve the above purpose, this embodiment provides a multi-angle and multi-modal image description generation system, including:
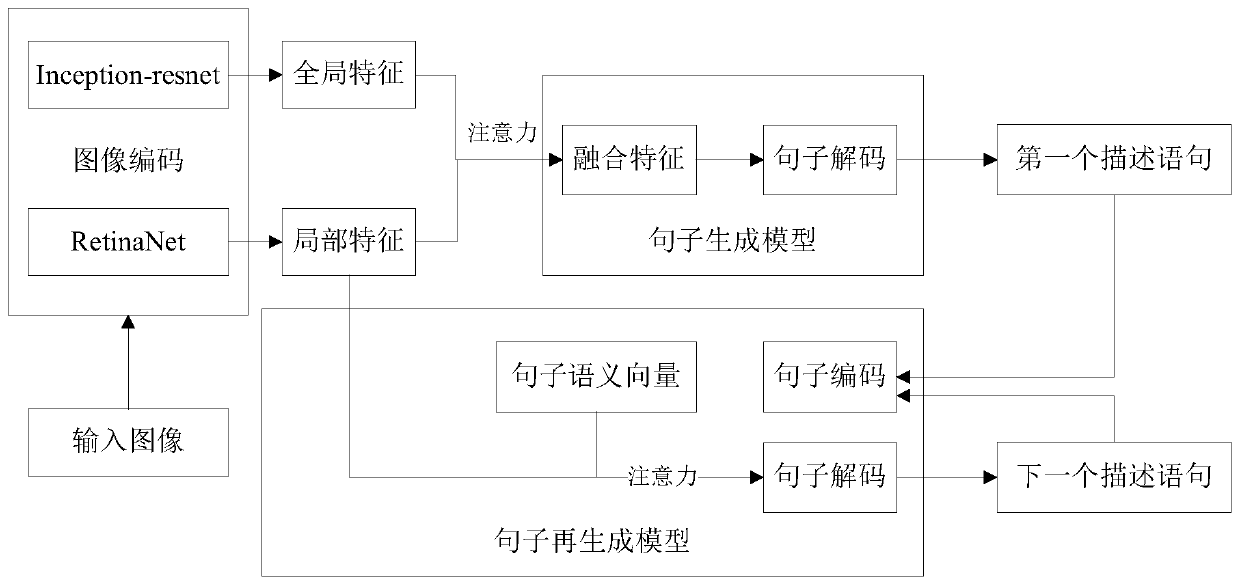
[0082] The visual feature extraction module receives the image to be described, extracts the global visual features and local visual features of the image and fuses them to obtain the fused visual features;
[0083] The sentence generation module adopts a single-layer long-short-term memory network, and takes the fusion visual features as input to obtain the first sentence image description;
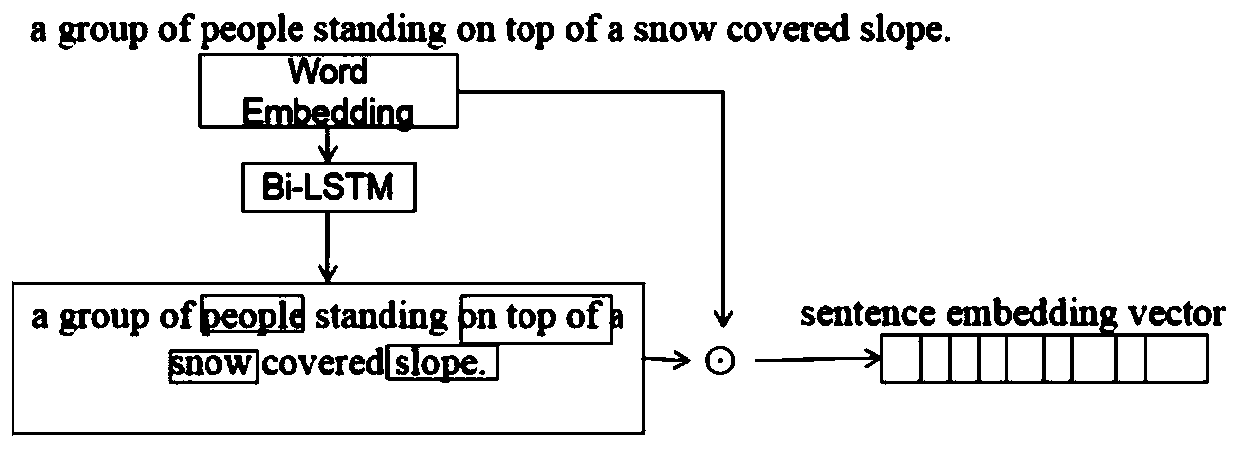
[0084] The sentence regeneration module generates the first sentence semantic vector according to the first sentence image description; adopts the attention-based long-short-term memory network language generation model, and uses the local visual features and the first sentence semantic vecto...
Embodiment 3
[0086] The purpose of this embodiment is to provide an electronic device.
[0087] An electronic device, comprising a memory, a processor, and a computer program stored on the memory and operable on the processor, when the processor executes the program, the following steps are implemented, including:
[0088] receiving the image to be described, extracting the global visual features and local visual features of the image and fusing them to obtain the fused visual features;
[0089] Using a single-layer long-short-term memory network, the fusion of visual features is used as input to obtain the first image description;
[0090] Generate the first sentence semantic vector according to the first sentence image description;
[0091] An attention-based long-short-term memory network language generation model is adopted, and the local visual features and the first sentence semantic vector are used as input to generate the next image description sentence, thereby obtaining a comple...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com