Multilayer neural network language model training method and device based on knowledge distillation
A multi-layer neural network and language model technology, applied in biological neural network models, neural learning methods, knowledge expression, etc., can solve problems such as large and complex network structures, slow training speed, etc., to achieve fast training speed and good coding ability. , the effect of improving the accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
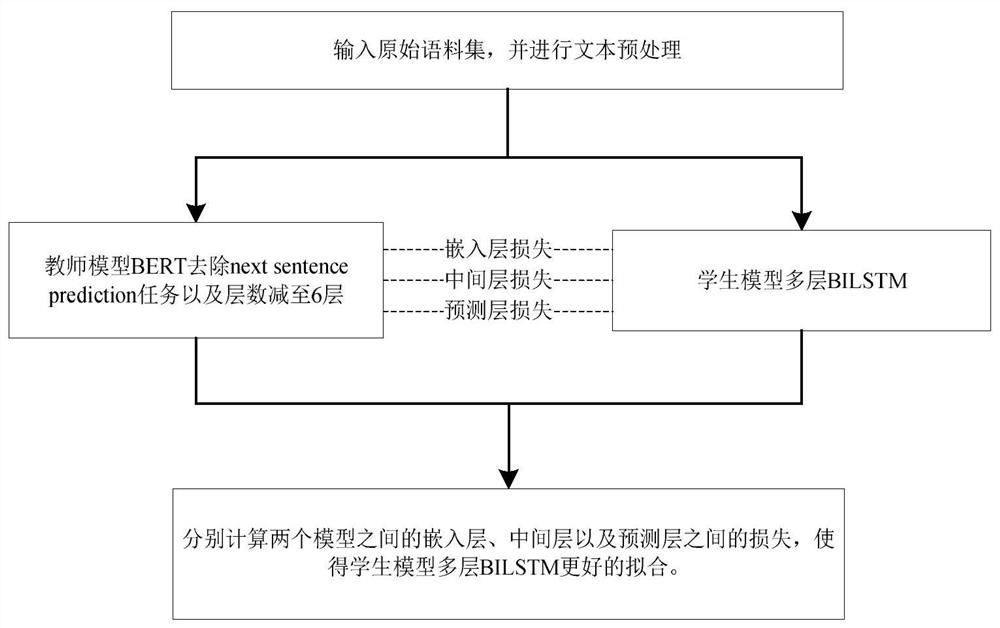
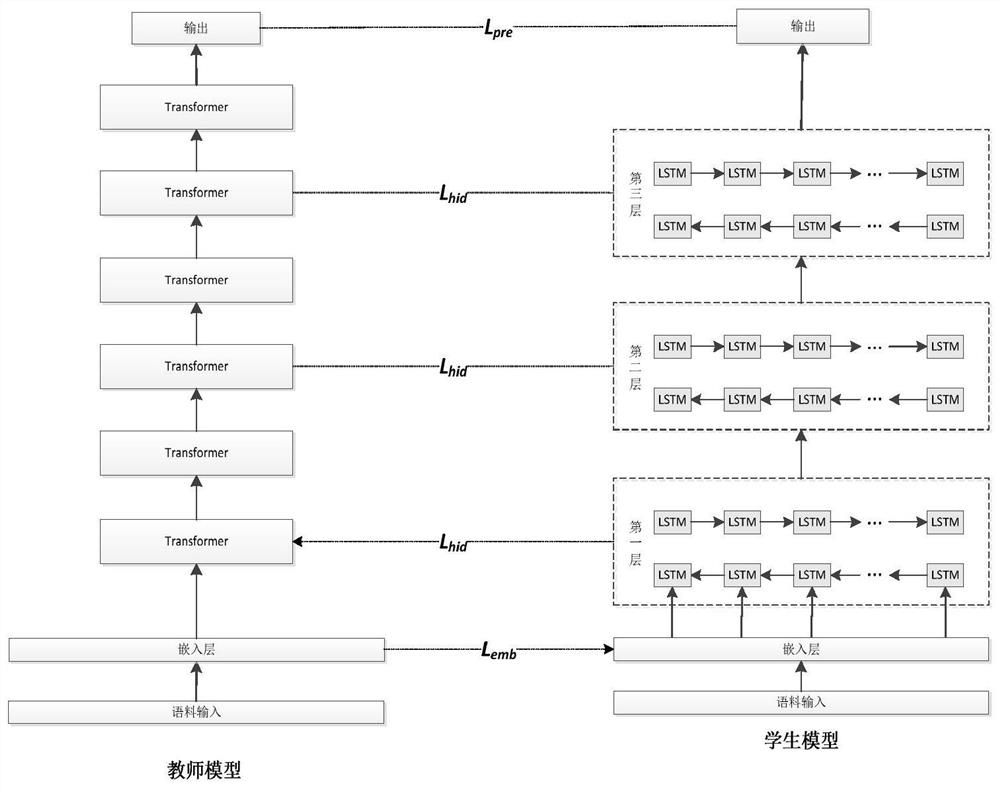
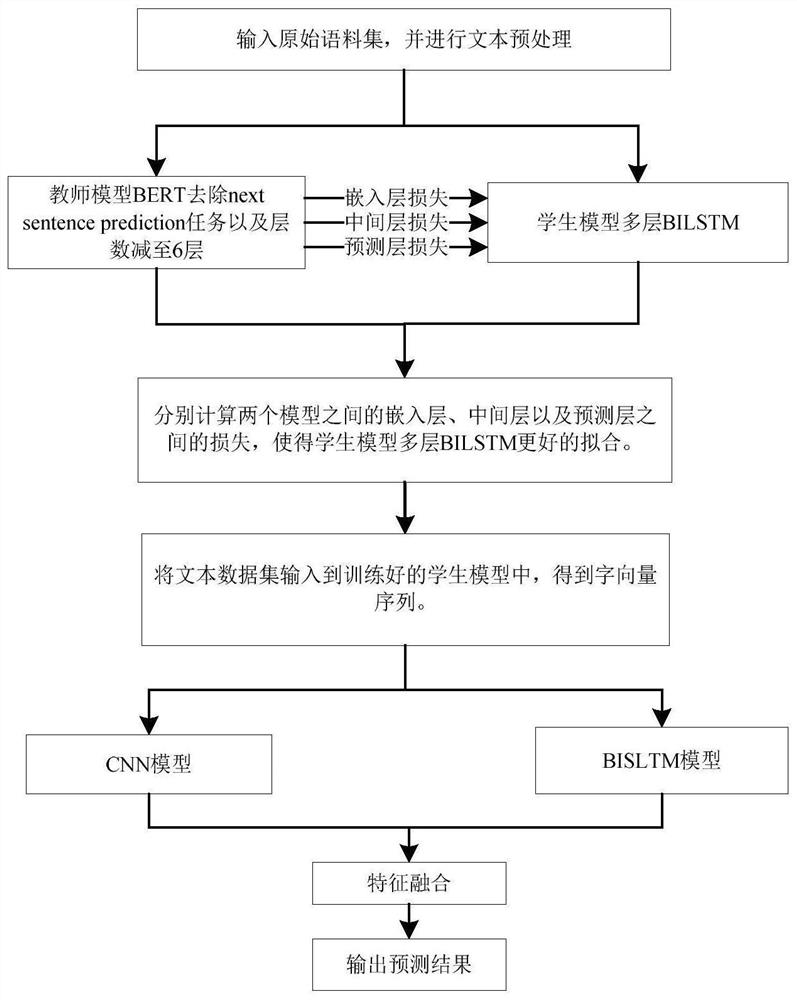
[0026] In order to clearly illustrate the technical solution of the present invention, the related technologies involved in the present invention will firstly be briefly described below.
[0027] BERT (Bidirectional Encoder Representation from Transformers, Transformer's bidirectional encoding representation) language model: BERT uses the masked model to realize the bidirectionality of the language model, which proves the importance of bidirectionality for language representation pre-training. The BERT model is a two-way language model in the true sense, and each word can use the context information of the word at the same time. BERT is the first fine-tuning model to achieve the best results in both sentence-level and token-level natural language tasks. It is proved that pre-trained representations can alleviate the design requirements of special model structures for different tasks. BERT achieves the best results on 11 natural language processing tasks. And in BERT's extens...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com