A method for predicting protein complexes based on sample data
A technology for protein complexes and sample data, applied in the field of predicting protein complexes based on sample data, to improve the accuracy, improve the defects of overfitting or underfitting, and reduce noise.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

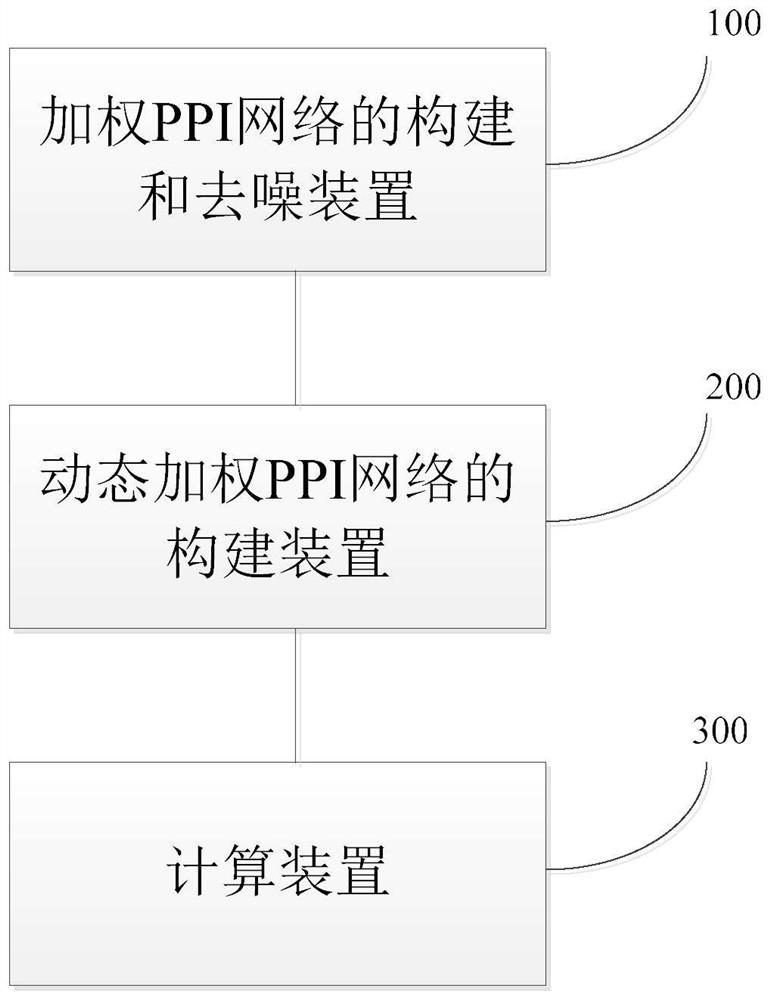
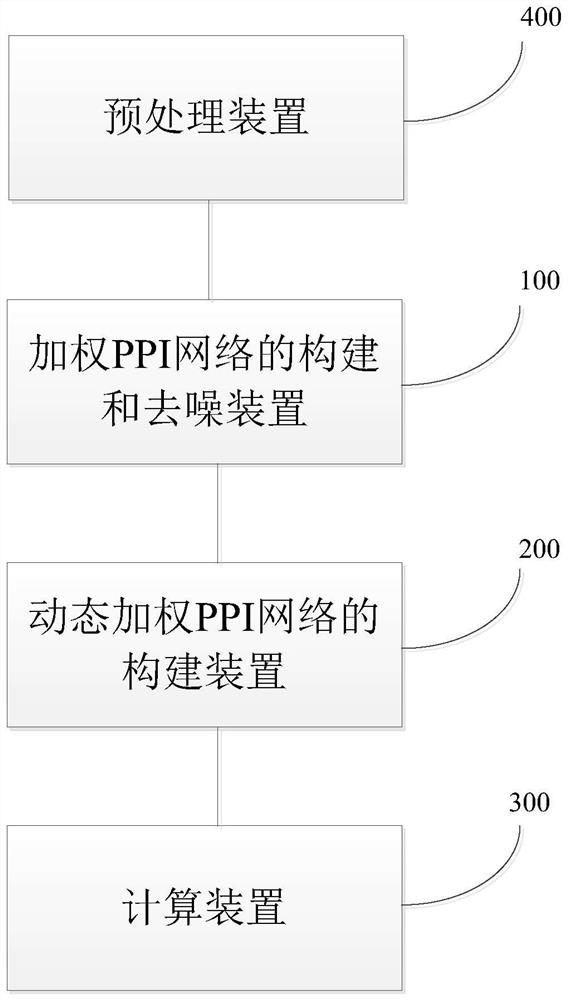
Examples
Embodiment 1
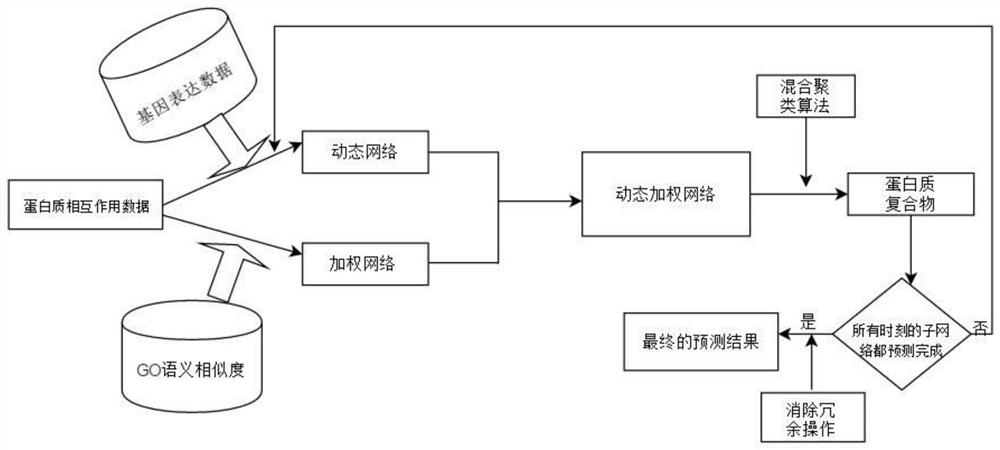
[0188] System Process Reference image 3 .
[0189] The protein interaction data is public data, and the PPI data set used by the inventor is the yeast protein interaction network, because the yeast data is relatively complete among all organisms. The DIP data set is used as the protein interaction data set, and GSE3431 is used as the gene expression data; the yeast genome database is used to calculate the GO semantic similarity; the CYC2008 database is used as the reference set.
[0190] S1: Construction of weighted network.
[0191] The PPI network is constructed based on the DIP data. In the DIP data set, there is a connection between the two proteins that interact. If there is no interaction between the two proteins, there is no connection between the two proteins. refer to Figure 6 , the nodes represent proteins, and the edges represent the interactions between proteins, Figure 6 (a) and (b) represent the unweighted PPI network and the weighted PPI network respectiv...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com