Text sentiment analysis method based on five stroke type code character level language model
A language model and Wubi font technology, applied in natural language data processing, electrical digital data processing, special data processing applications, etc., can solve problems such as unsatisfactory experimental results, achieve excellent Chinese emotion classification effects, and save labor costs. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

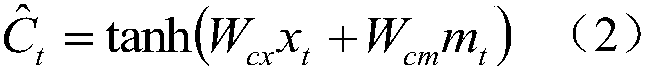

Examples
Embodiment 1
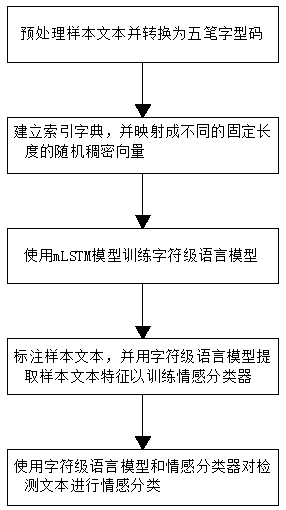
[0064] A text sentiment analysis method based on the character-level language model of Wubi font code, such as figure 1 As shown, it mainly includes the following steps:
[0065] Step E1: Preprocessing the sample text, converting the Chinese characters in the sample text into Wubi font codes;
[0066] Step E2: Build an index dictionary for the characters in the preprocessed sample text in step E1, and map them into random dense vectors of different fixed lengths; the sample text is finally converted into a sequence of character vectors for training character-level language models ;
[0067] Step E3: use the mLSTM model to train a character-level language model; use the character vector at the previous moment in the character vector sequence generated in step E2 to predict the character vector at the next moment in the sequence;
[0068] Step E4: mark the emotional category of the sample text, and use the character-level language model in step E3 to extract the features of th...
Embodiment 2
[0072] This embodiment is further optimized on the basis of Embodiment 1, an intermediate state variable m is introduced into the mLSTM model t , the m t The calculation formula is as follows:
[0073] m t =(W mx x t )⊙(W mh x t-1 ) (1)
[0074] In the mLSTM model The calculation formula is as follows:
[0075]
[0076] i t =σ(W ix x t +W im m t ) (3)
[0077] o t =σ(W ox x t +W om m t ) (4)
[0078] f t =σ(W fx x t +W fm m t ) (5)
[0079]
[0080] h t =o t ⊙tanh(C t ) (7)
[0081] The mLSTM model can handle more complex state transitions between consecutive characters, forming a flexible input-dependent processing mechanism.
[0082] The present invention converts Chinese characters in Chinese text into Wubi glyph codes, and the character-level language model retains more original information; the present invention uses the mLSTM model to train the character-level language model, which can handle more complex state transitions between con...
Embodiment 3
[0085] The present embodiment is further optimized on the basis of embodiment 2. In the step E4, the emotion is divided into two kinds of emotion categories, positive emotion and negative emotion, and the sample text is selected and marked with the emotion category; the sample text is input into the characters in the step E3 Level language model, classification algorithm uses logistic regression, the formula of described logistic regression is as follows:
[0086] y=Logit(tanh(C T )) (8)
[0087] Among them, assuming that there are T moments, the memory neuron C of the last moment T T is a summary of the sample text, and tan(C T ) as features for sentiment classification to train a binary classifier.
[0088] The present invention converts Chinese characters in Chinese text into Wubi glyph codes, and the character-level language model retains more original information; the present invention uses the mLSTM model to train the character-level language model, which can handle m...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com