Web crawler identification method and web crawler identification device
A technology of web crawler and identification method, applied in the field of identification method and device of web crawler, capable of solving the problems of high false negative rate and false positive rate, large limitations, etc. Good results
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
no. 1 example
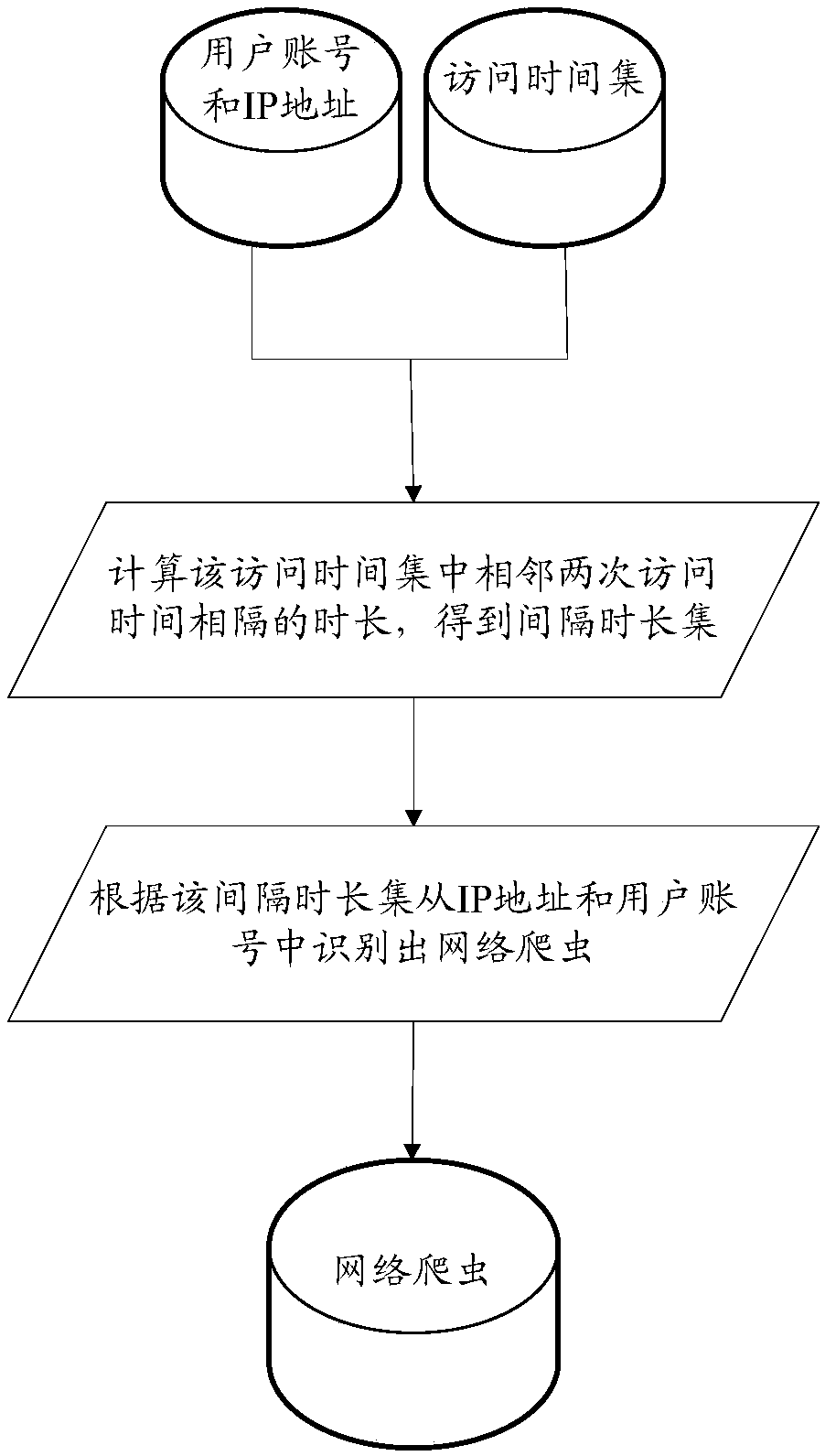
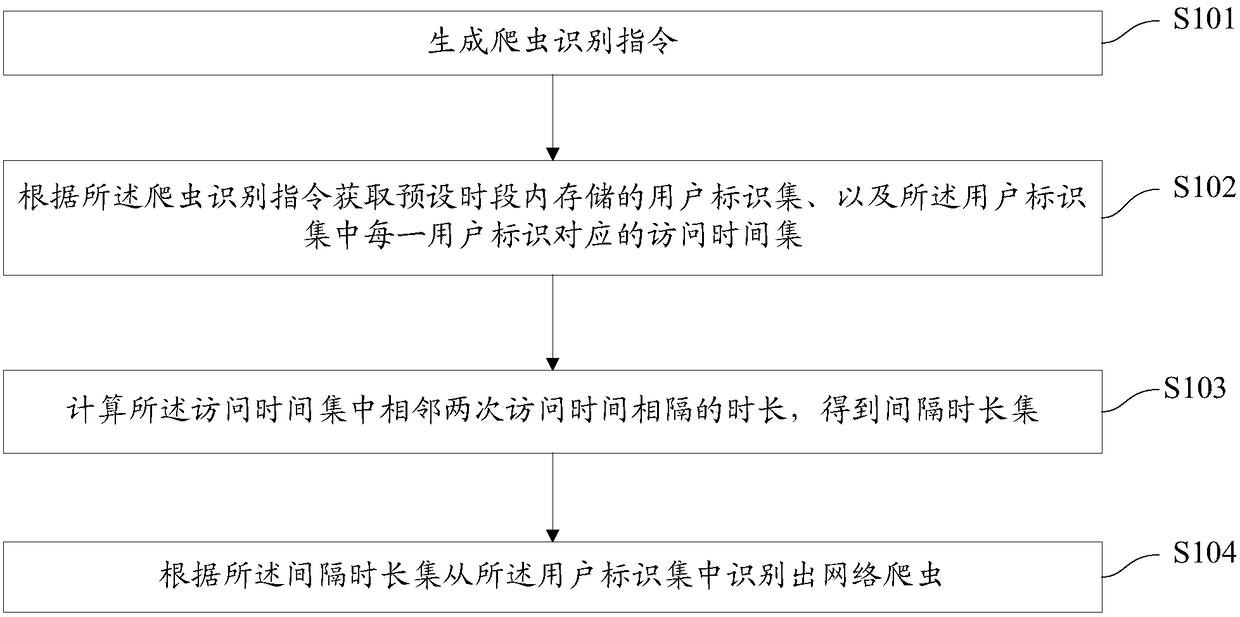
[0034] This embodiment will be described from the perspective of the identification device of the web crawler, please refer to Figure 1b , Figure 1b The identification method of the web crawler provided by the embodiment of the present invention is specifically described, which may include:
[0035] S101. Generate a crawler identification instruction.
[0036] In this embodiment, the trigger condition for generating the crawler identification instruction can be determined according to actual needs, and it can be a specified time or a specified amount of data, wherein, the specified time and the specified amount of data can be set by the user, or can be It is the factory default setting when the server leaves the factory. Specifically, when the trigger condition is a specified time, the server may be triggered to generate a crawler identification instruction when the specified time is reached. When the trigger condition is the specified amount of data, it is necessary to c...
no. 2 example
[0103] According to the method described in Embodiment 1, an example will be given below for further detailed description.
[0104] In this embodiment, it will be described in detail by taking the identification device of the web crawler integrated in the server, the first terminal and the second terminal as an example.
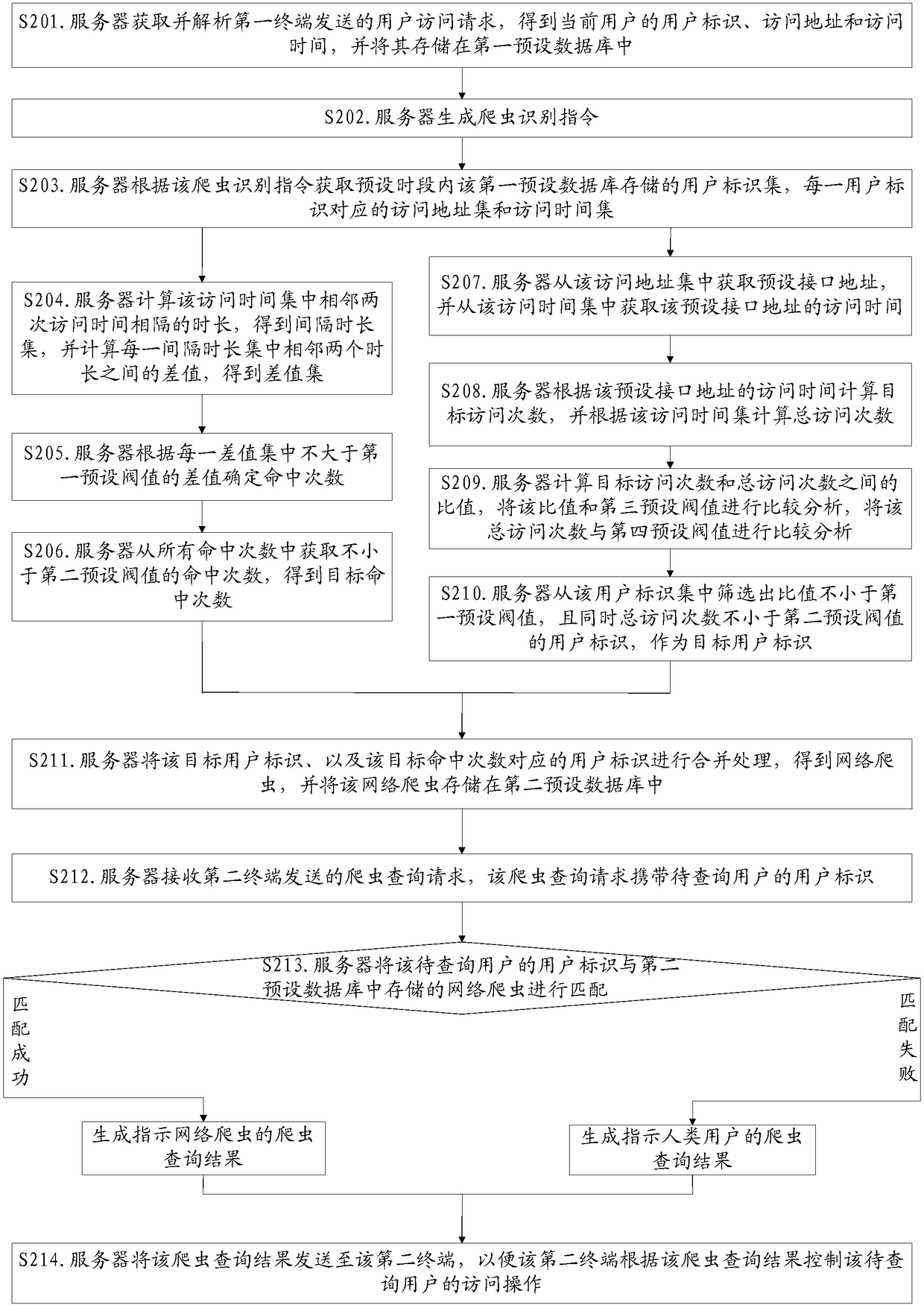
[0105] Such as Figure 2a and Figure 2b As shown, a web crawler identification method, the specific process can be as follows:
[0106] S201. The server acquires and parses the user access request sent by the first terminal, obtains the user ID, access address and access time of the current user, and stores them in a first preset database.
[0107] For example, there are roughly two acquisition paths for the user's access request, one is obtained through the traffic bypass copy operation from the switch through the optical splitting device, and the other is obtained from the web server through the data sending queue to report real-time traffic data. The u...
no. 3 example
[0142] According to the methods described in Embodiment 1 and Embodiment 2, this embodiment will be further described from the perspective of a web crawler identification device, and the web crawler identification device may be integrated in a server.
[0143] see Figure 3a , Figure 3a The web crawler identification device provided by the third embodiment of the present invention is specifically described, which may include: a generation module 10, an acquisition module 20, a calculation module 30 and an identification module 40, wherein:
[0144] (1) Generate module 10
[0145] The generating module 10 is configured to generate a crawler identification instruction.
[0146] In this embodiment, the trigger condition for generating the crawler identification instruction can be determined according to actual needs, and it can be a specified time or a specified amount of data, wherein, the specified time and the specified amount of data can be set by the user, or can be It i...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com