A method for handwritten document retrieval based on machine learning
A technology of document retrieval and machine learning, applied in the field of deep learning, to achieve the effect of eliminating human error
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
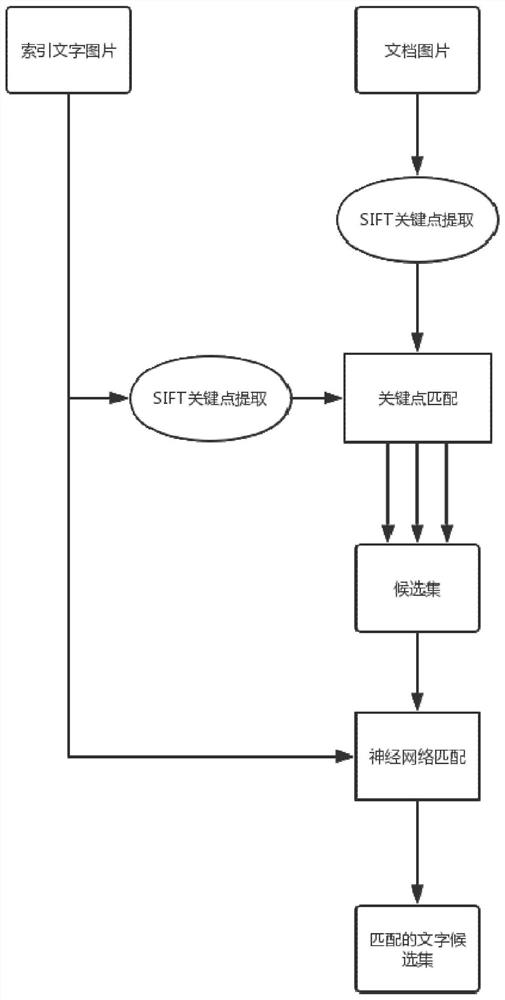
[0027] combine figure 1 , the retrieval method of the present invention has two inputs, one input is a document picture, the other input is an index text picture, and the output is the position of the document where the text is located, and the retrieved text can be marked in the document through post-marking. Searching for a match is a two-step process:
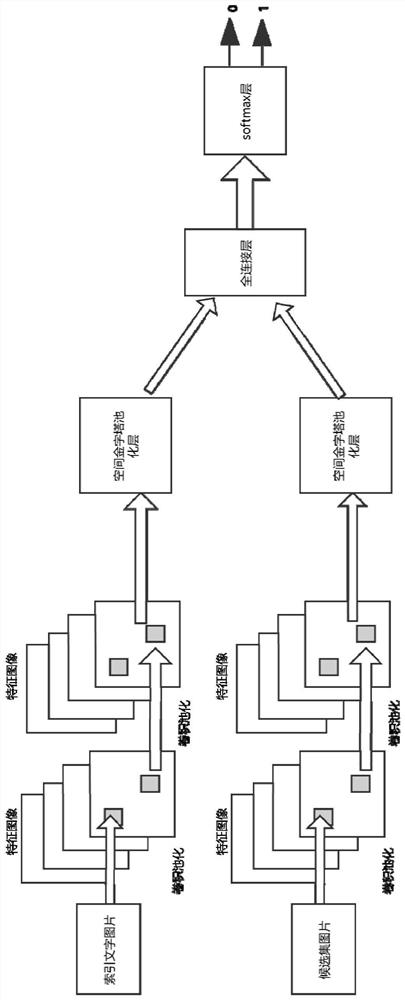
[0028] In the first step, SIFT feature extraction is performed on the two input images. For the indexed text image, we extract key points from the entire image, and use descriptors to represent the features of the indexed text image. SIFT is used to detect and describe local features in pictures. It looks for extreme points in the spatial scale, and extracts its position, scale, and rotation invariance; pictures use Gaussian filters at different scales. Perform convolution, and then use continuous Gaussian blurring image differences to find key points, which are based on the maximum and minimum values of the Difference o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com