Chinese text categorization method based on multi-hidden-layer extreme learning machine
An extreme learning machine, text classification technology, applied in semantic analysis, computer parts, instruments, etc., to achieve fast learning speed and generalization ability, improve the effect of accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
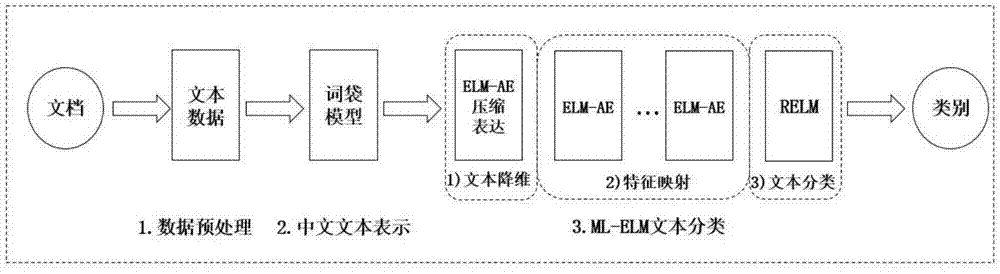
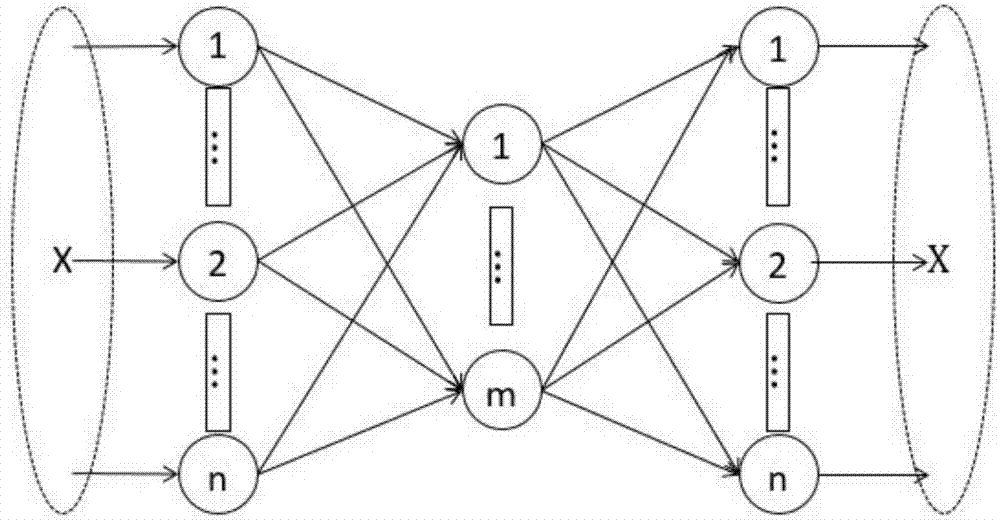
[0025] The following is through the Chinese corpus data of Fudan University and the attached Figure 1-4 To set forth the specific embodiment and detailed steps of the present invention:
[0026] Step 1: Data Preprocessing
[0027] The Fudan University Chinese corpus data set consists of two parts: training samples and test samples. Training samples: 9805, test samples: 9833, and the classification results are 20 different text categories. All text in the corpus needs to be converted to utf-8 format before processing. After converting the format, first use the full-mode word segmentation method under the jieba word segmentation tool to perform word segmentation processing on the training samples and test samples, and segment the sentences of the article into individual phrases and words. Then you need to use regular expressions to "denoise" the text data, including removing punctuation marks, numeric characters, and English characters in the text. Because there are many st...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com