Video content description method by means of space and time attention models
An attention model and video content technology, applied in neural learning methods, biological neural network models, character and pattern recognition, etc., can solve problems such as losing and ignoring key information
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
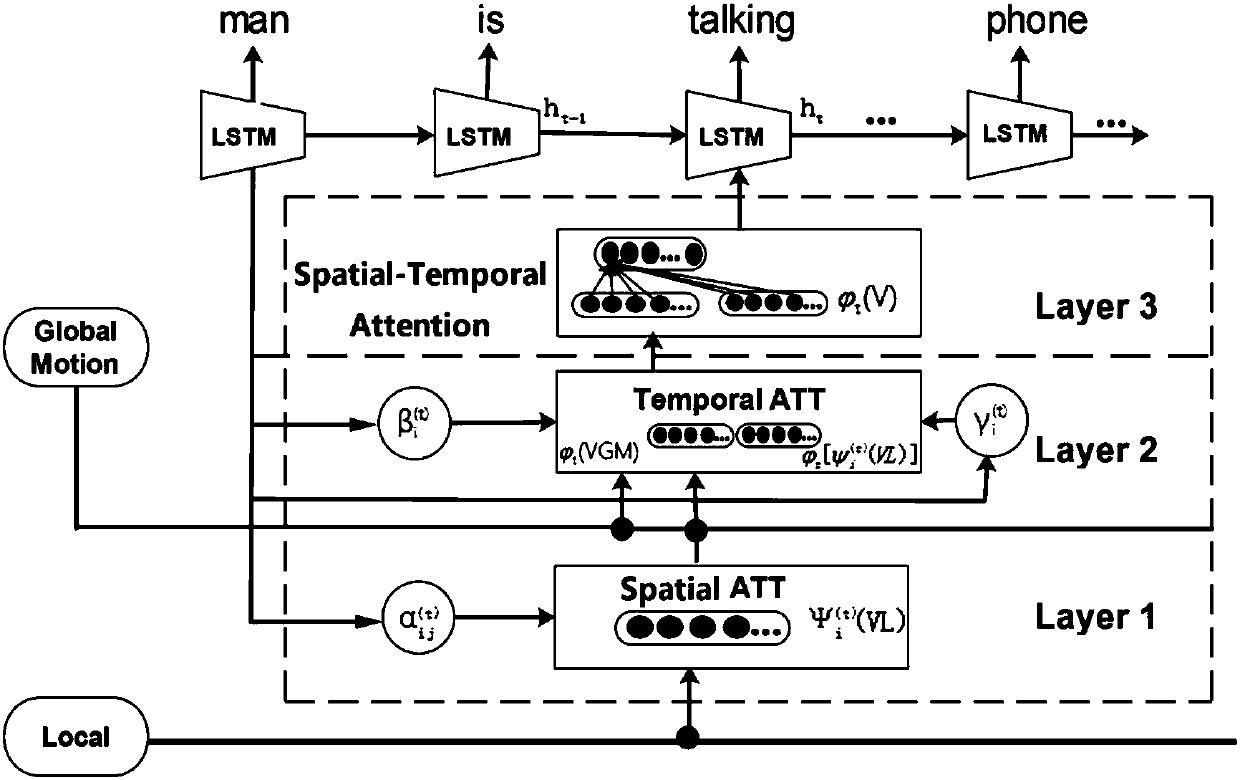
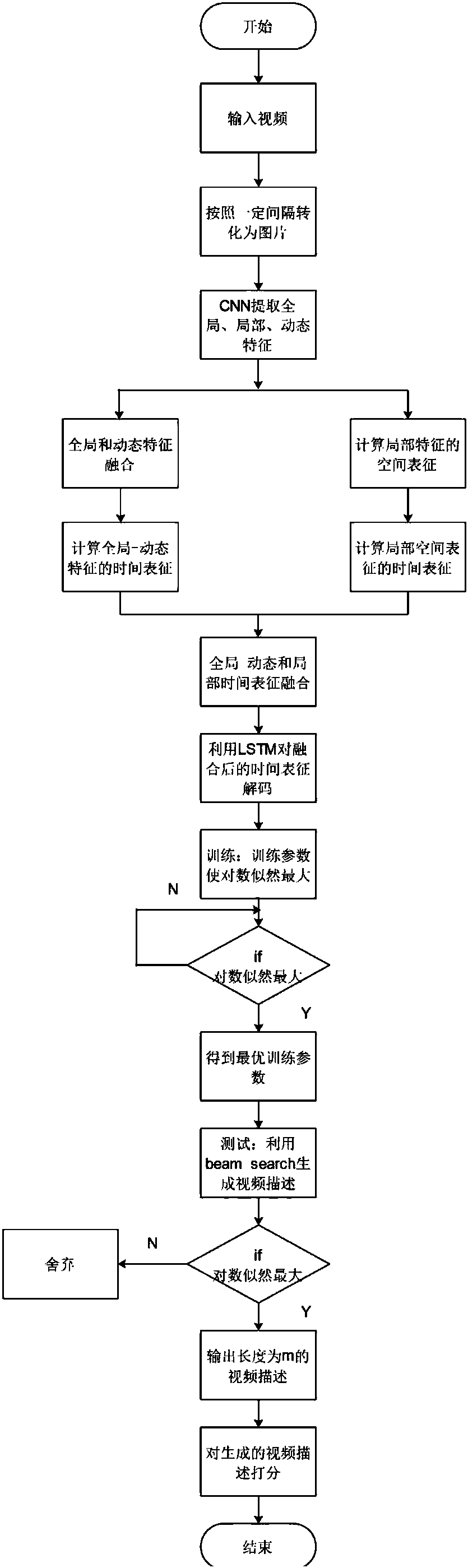
[0096] Combine below figure 2 , giving video content description specific examples of training and testing implementation, the detailed calculation process is as follows:
[0097] (1) There are a total of 430 frames in a certain section of video. First, the video format is preprocessed, and the video to be described is converted into a set of pictures with intervals of 43 frames according to 10% of the frame rate;
[0098] (2) Use the pre-trained convolutional neural network GoogLeNet, Faster R-CNN and C3D to extract the global features, local features and dynamic features of the entire video in 43 pictures, and use the cascade method according to the formula (1 ) the methods listed in ) combine the global features and dynamics;
[0099] (3) According to the methods listed in formulas (2)-(5), calculate the spatial representation of the local features on each frame of the picture
[0100] (4) According to the methods listed in formulas (8)-(13), respectively c...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com