Single channel mixed speech time domain separation method based on Convolutional Neural Network
A convolutional neural network and mixed voice technology, applied in voice analysis, instruments, etc., can solve problems such as difficult phase recovery, separation quality to be improved, and mutual interference
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0048] The present invention will be further described below in conjunction with the drawings.
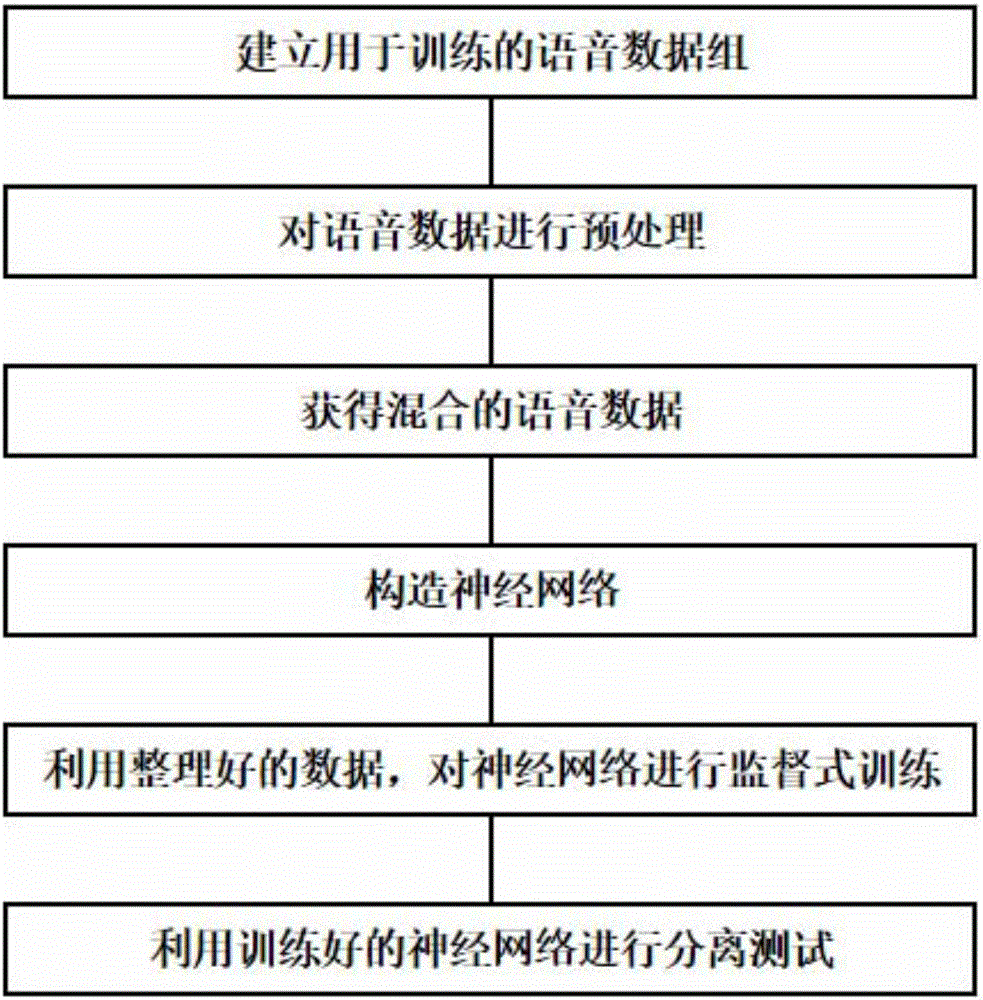
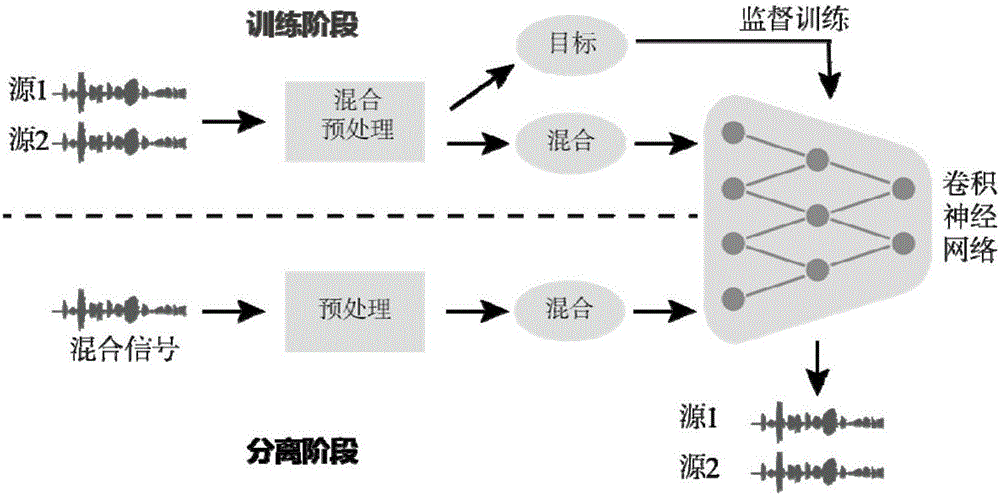
[0049] Such as figure 1 As shown, the time-domain separation method for single-channel mixed speech based on convolutional neural network includes the following steps:
[0050] Step 1. Establish a voice data set for training. Randomly select a large amount of voice data from a standard database, such as TSP voice database, and divide it into two groups. 80% of the voice data is used as training data and the remaining 20% is used as test data. ;
[0051] Step 2. Preprocess the voice data. First, use formula (1) to normalize the original voice data to the range [-1,1].
[0052]
[0053] Where s i Represents the i-th source signal, max(·) represents the maximum value, abs(s i ) Means pair s i Each element in takes the absolute value, y i Represents the normalized i-th source signal, and then uses formula (2) to process the time domain speech signal into frames. The frame length is N=1024, a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com