Distributed data processing method and device
A distributed data and distributed processing technology, applied in the field of data processing, can solve problems such as resource waste, processing failure, and lower data processing efficiency, and achieve the effect of ensuring stability and improving efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
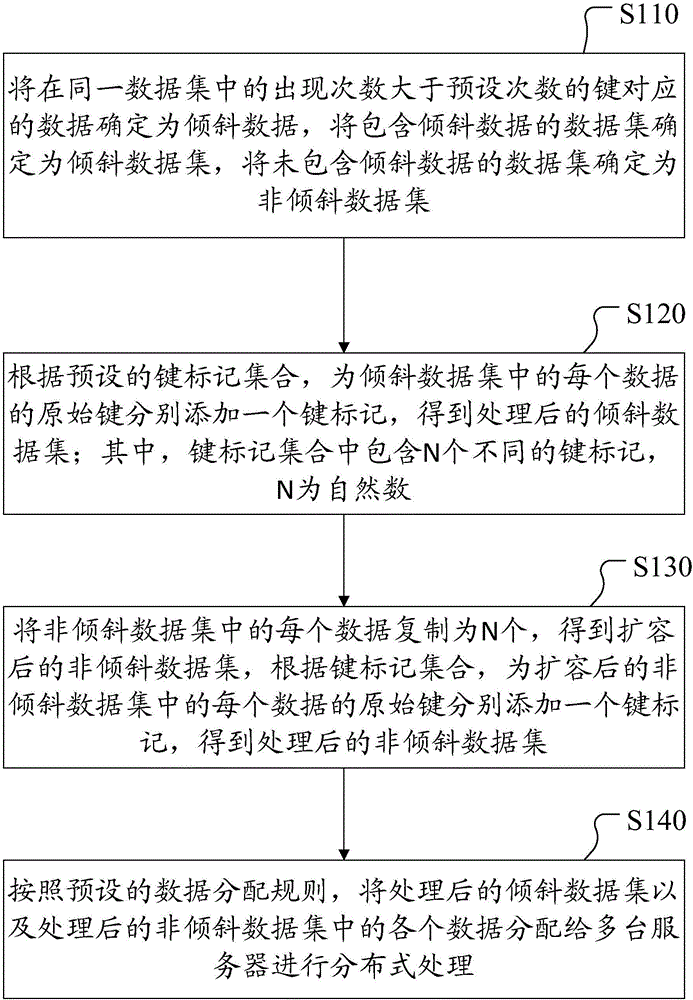
[0029] figure 1 It shows a schematic flow chart of a distributed data processing method provided by Embodiment 1 of the present invention, and the method includes:
[0030] Step S110: Determine the data corresponding to the key whose occurrence number is greater than the preset number in the same data set as slanted data, determine the data set containing slanted data as slanted data set, and determine the data set that does not contain slanted data as non-slanted data data set.
[0031] In the process of distributed data processing, the data to be processed is allocated to different servers according to the key value of the corresponding key. If there is too much data distributed on one server, the processing time of that server will be too long, while the data distributed on other servers will be less, and the processing time will be less, resulting in the operation bottleneck of the entire distributed data processing process concentrated on one On the server, thereby reducing t...
Embodiment 2
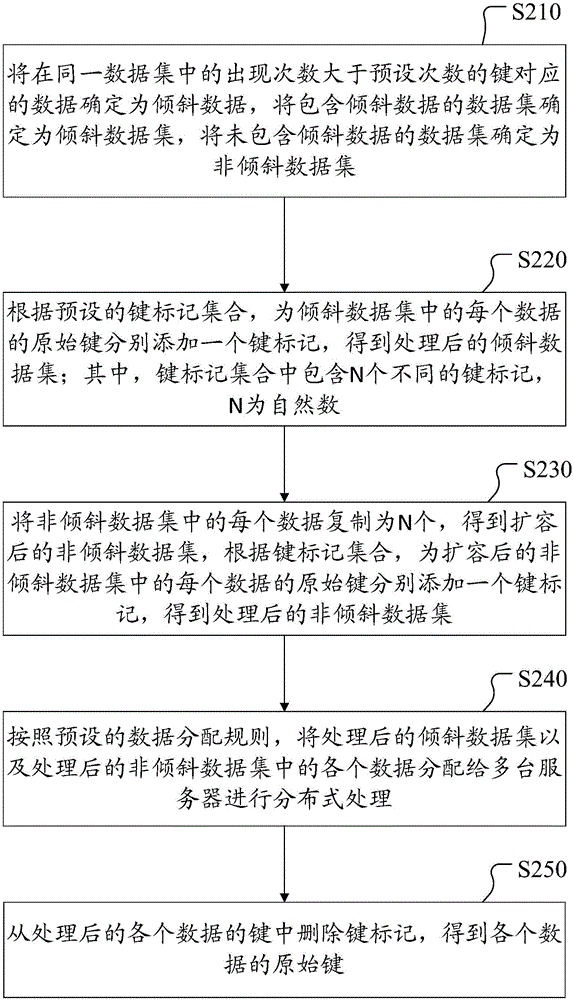
[0042] figure 2 It shows a schematic flow chart of a distributed data processing method provided by Embodiment 2 of the present invention, and the method includes:
[0043] Step S210: Determine the data corresponding to the key whose occurrence number is greater than the preset number in the same data set as slanted data, determine the data set containing slanted data as slanted data set, and determine the data set that does not contain slanted data as non-slanted data data set.
[0044] In the process of distributed data processing, the data to be processed is allocated to different servers according to the key value of the corresponding key. If there is too much data distributed on one server, the processing time of that server will be too long, while the data distributed on other servers will be less, and the processing time will be less, resulting in the operation bottleneck of the entire distributed data processing process concentrated on one On the server, thereby reducing ...
Embodiment 3
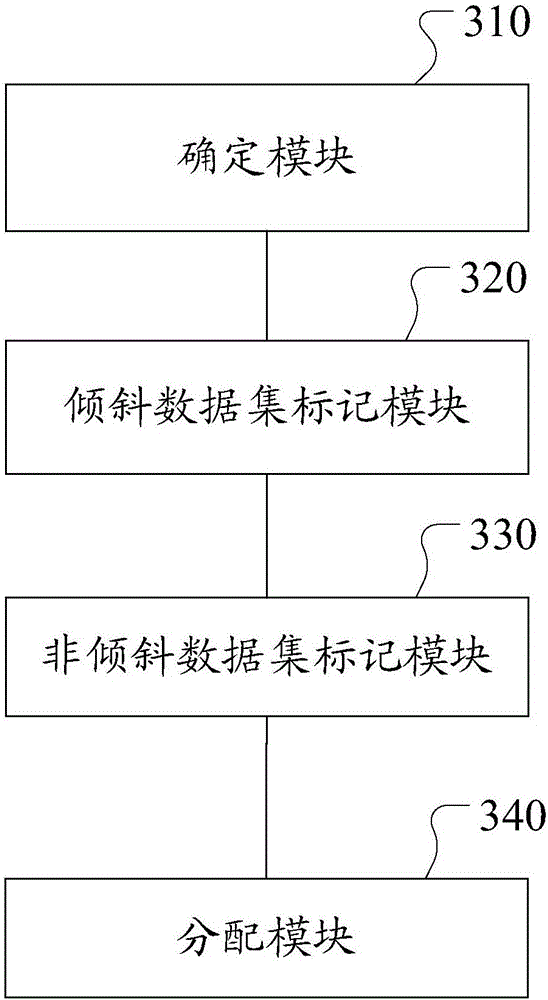
[0071] image 3 It shows a schematic structural diagram of a distributed data processing device provided in the third embodiment of the present invention. The device includes: a determination module 310, an oblique data set marking module 320, a non-inclined data set marking module 330, and an allocation module 340.
[0072] Determining module 310: Determining data corresponding to keys with more than a preset number of occurrences in the same data set as oblique data, determining data sets containing oblique data as oblique data sets, and determining data sets not containing oblique data as non-oblique data. Tilt the data set.
[0073] In the process of distributed data processing, the data to be processed is allocated to different servers according to the key value of the corresponding key. If there is too much data distributed on one server, the processing time of that server will be too long, while the data distributed on other servers will be less, and the processing time will...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com