Unsupervised feature selecting method based on conditional mutual information and K-means
A feature selection method and conditional mutual information technology, applied in computer parts, character and pattern recognition, instruments, etc., can solve the problems of reduced classification accuracy, data imbalance, inapplicability, etc., to reduce redundancy and eliminate randomness. Sexuality, the effect of increasing relevance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0038] Below in conjunction with accompanying drawing, the implementation of technical scheme is described in further detail:
[0039] The unsupervised feature selection method based on conditional mutual information and K-means of the present invention will be further described in detail in conjunction with the flow chart and the implementation case.
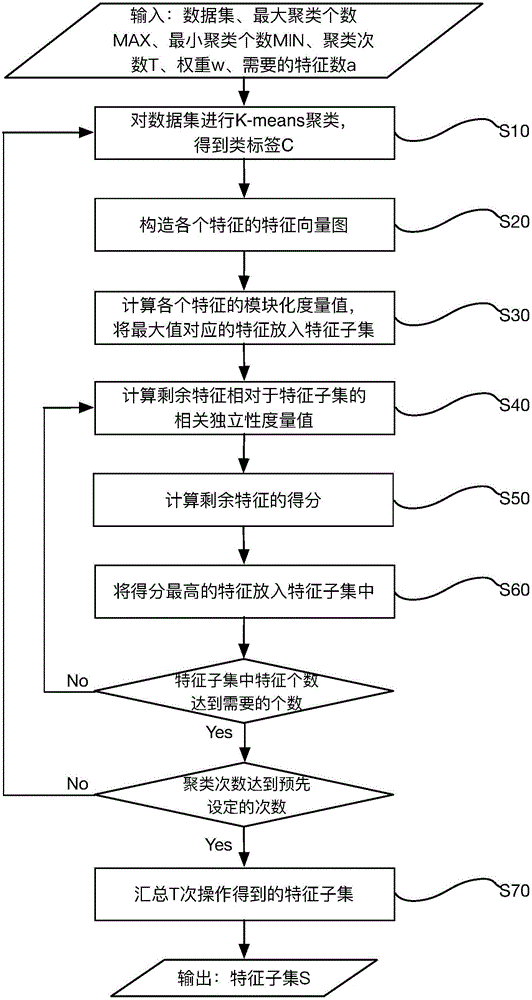
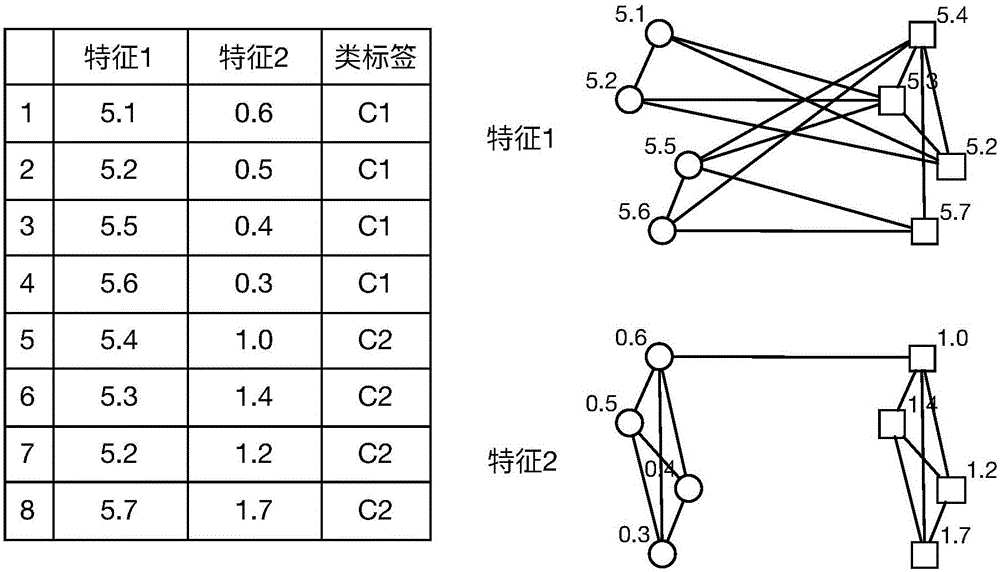
[0040] In this implementation case, the conditional mutual information and K-means algorithm are used to select the features of the unlabeled data set. Such as figure 1 As shown, this method includes the following steps:
[0041] Step 10, performing multiple K-means clustering with different K values and different cluster centers on the unlabeled data set, and obtaining each clustering result;
[0042] In step 101, the maximum number of clusters MAX and the minimum number of clusters MIN of the K-means algorithm are predetermined in the input stage, and before each clustering, a number is randomly selected in the range of [...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com