


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
A Large-Scale Data Anomaly Identification Method Based on Bidirectional Sampling Combination
A technology of anomaly identification and sample data set, applied in the field of anomaly identification, it can solve the problems of large sample size, time complexity, dimensional disaster, etc., to overcome the dimensional disaster problem, reduce the impact of noise, and speed up the time of parallel computing.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

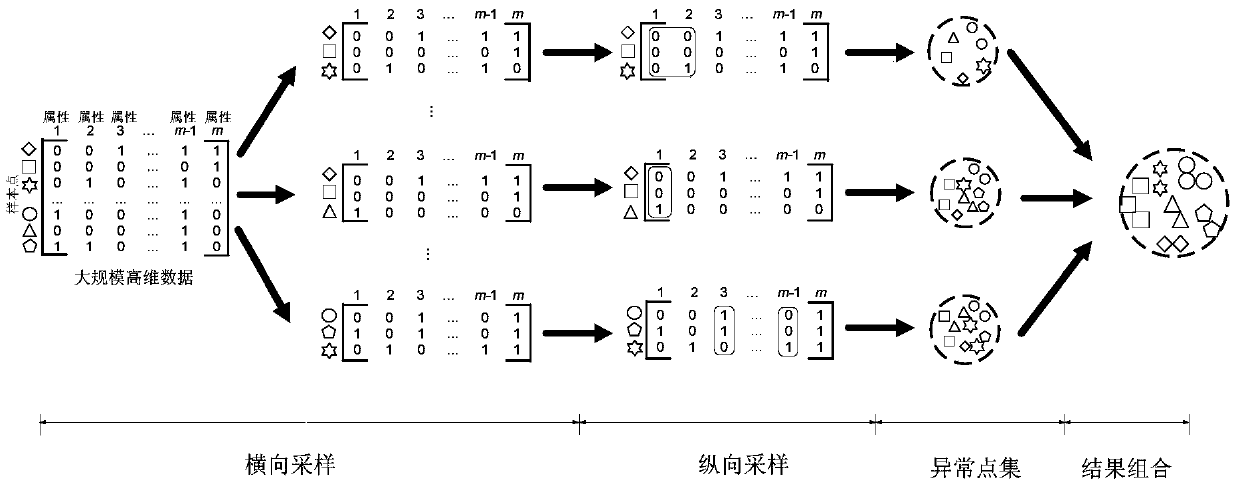

Examples
Embodiment 1
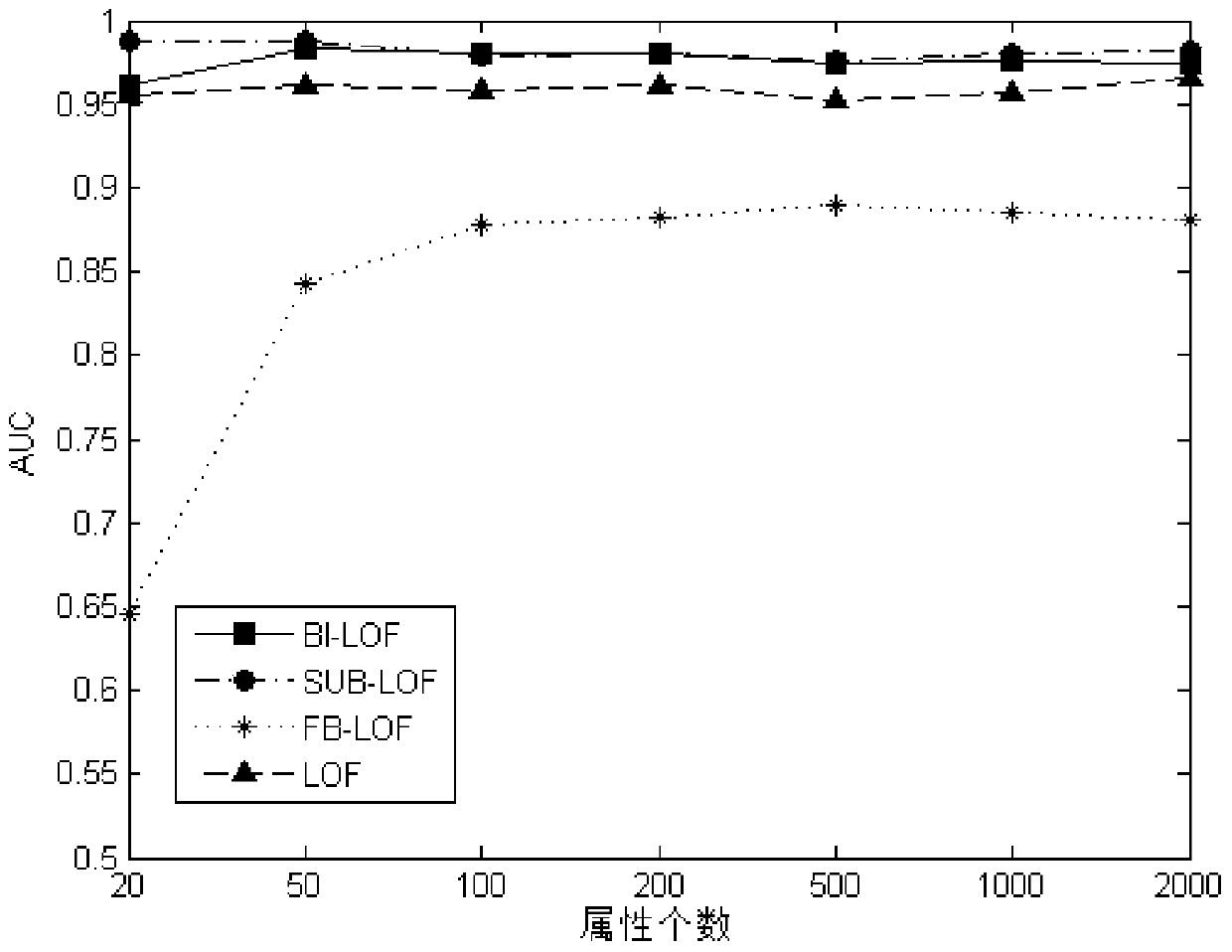
[0077] Take the simulated data set generated by multivariate Gaussian distribution simulation as an example below to illustrate the effect of the method of the present invention:
[0078] First, the simulation data set is generated by multivariate Gaussian distribution simulation. The number of sample points n of each sample data set is 1000, 2000, 5000, 10000, 50000, 100000 respectively, and the dimension m of the sample is 20, 100, 200, 500, 1000 respectively. , 2000, a total of 42 simulation data sets. Each sample data set D consists of c clusters, and the number of clusters c ranges from 5 to 10. Assume that in the simulation data set, the sample points D of each cluster c All obey the m-element Gaussian distribution, namely And the parameters in the Gaussian distribution are randomly generated by the uniform distribution, namely Then, each sample point D c Mahalanobis distance to its cluster center point At the same time, it also obeys the chi-square distribution ...
Embodiment 2
[0084] Take the real data set as an example below to illustrate the effect of the method of the present invention:
[0085] The real data sets are all selected from the UCI database, and Table 1 gives a description of the characteristics of all the data sets involved in the experiment. In order to simulate the abnormal situation in the data set, we randomly select s ∈ [10, 100] points from the smallest class of each data set to mark as the abnormal points of the data set, and the remaining points are marked as normal points. Since the method of the present invention is not suitable for the analysis of discrete attributes, it is necessary to eliminate the discrete attributes in some real data sets. Same as Example 1, this example uses the area under the ROC curve (AUC) to evaluate the effect of different methods of the present invention.
[0086] Table 1
[0087] dataset name
Sample points
number of attributes
number of classes
minimal class
large...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com