


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
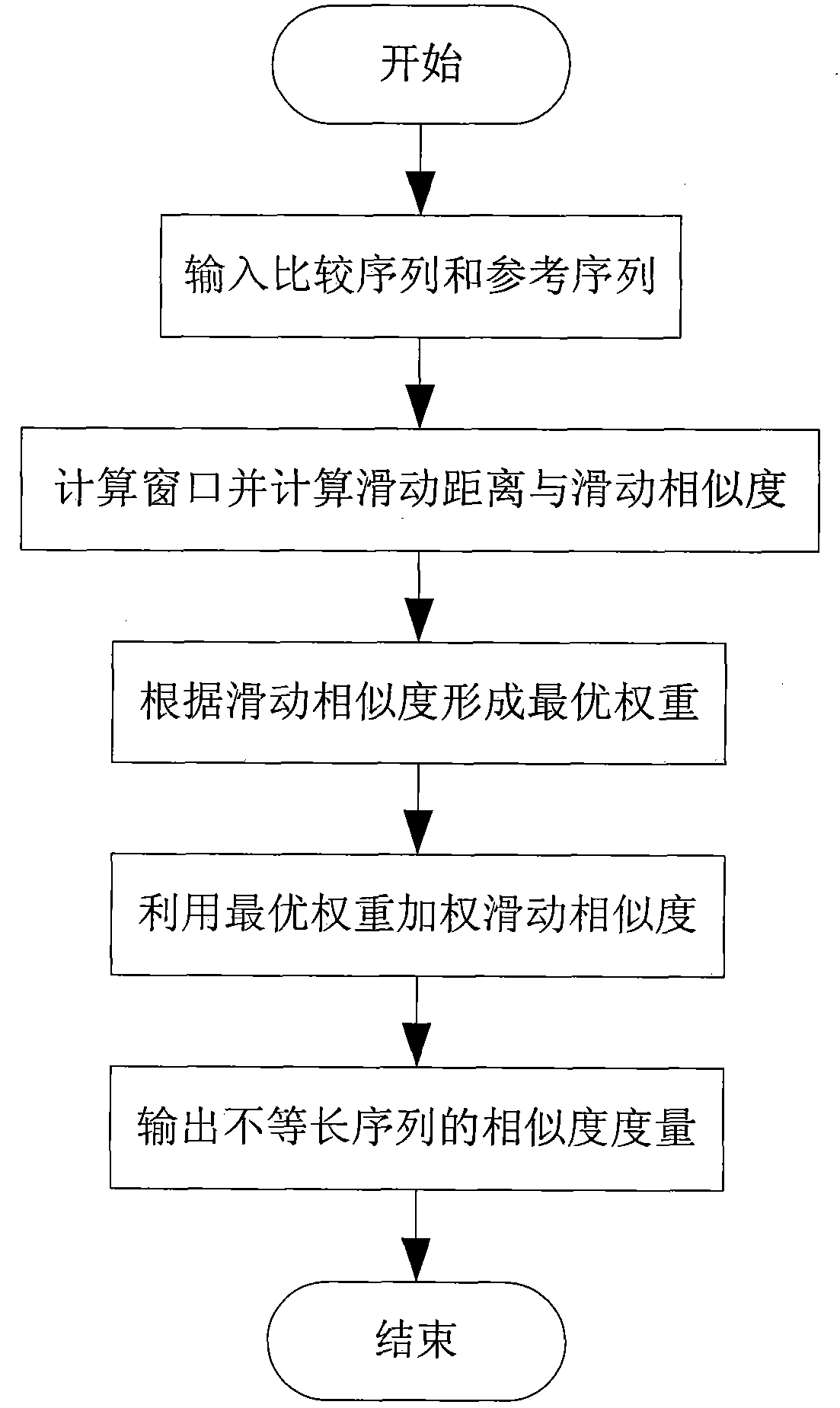
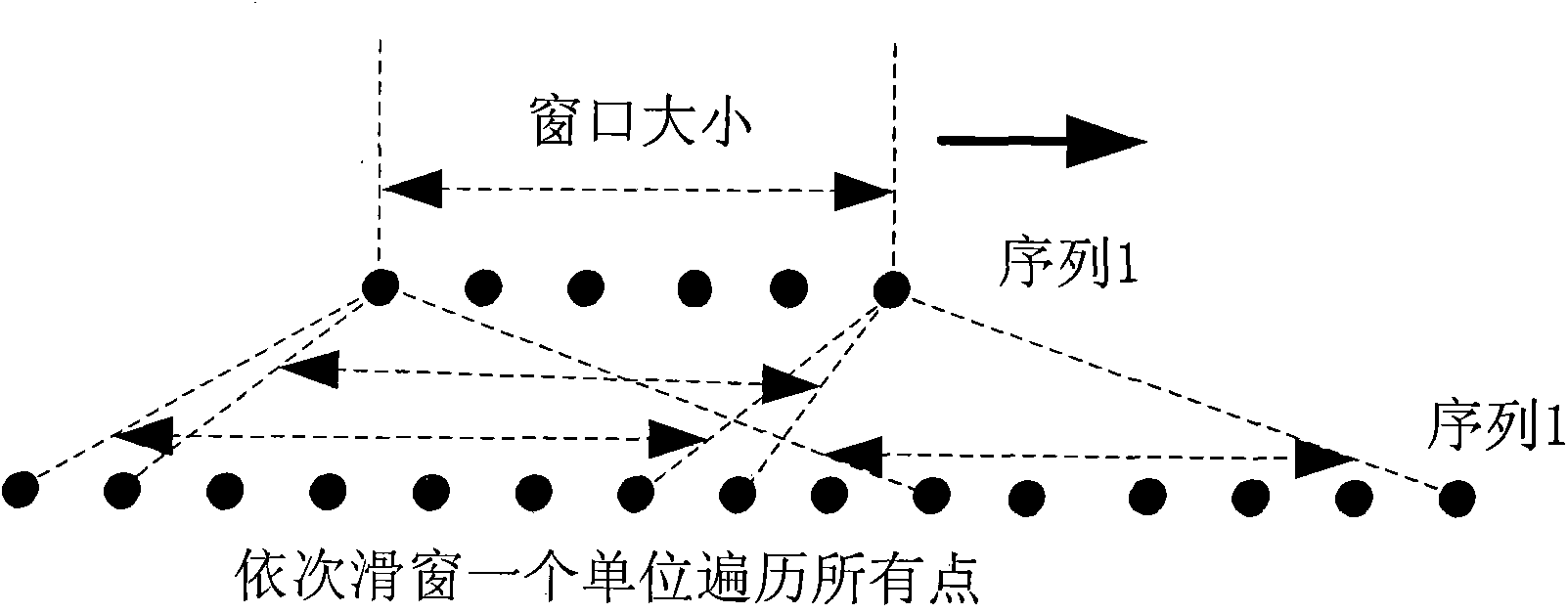
Similarity measuring algorithm for sequences in different lengths
A similarity, long sequence technology, applied in the field of data fusion algorithms, can solve problems such as transformation errors, affecting the similarity measurement between sequences, and reducing the authenticity of data associations
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

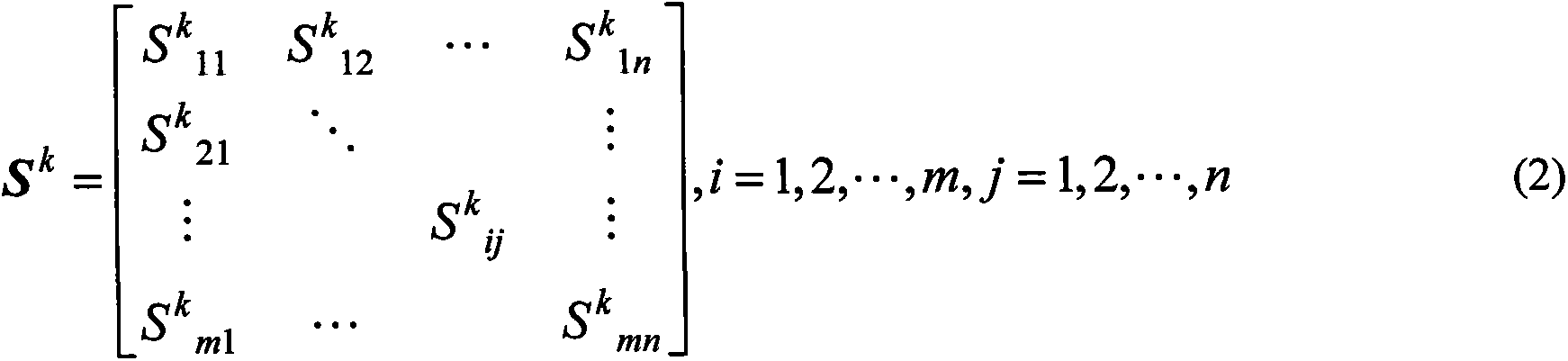
Examples
Embodiment
[0061] Assuming that two types of sensors sensor1 and sensor2 are set as ESM and ELINT, the target is measured, and three types of target identity information are measured, radar carrier frequency RF, pulse repetition frequency PRF and pulse width PW, which are obtained after front-end data processing and correlation Two target sequence matrices S to be identified 1 and S 2 , which are composed of three bar sequences, representing RF, PRF and PW three types of parameters. There are four types of target identity attributes in the target database, and the sequence matrix Q 1 , Q 2 , Q 3 and Q 4 Indicates that the data parameters in the matrix and the target sequence matrix S to be identified are 1 and S 2 Correspondingly, the lengths between them are unequal. Adopt the method proposed by the present invention to calculate two target sequence matrices S to be identified 1 and S 2 and four types of target identity attribute sequence matrix Q 1 , Q 2 , Q 3 and Q 4 simi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com