Distributed computation system and method for large-scale data set cross comparison
A technology of distributed computing and large-scale data, applied in the field of distributed computing, can solve problems such as difficulties in parallel program development, and achieve the effect of facilitating implementation and reducing the difficulty of use.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
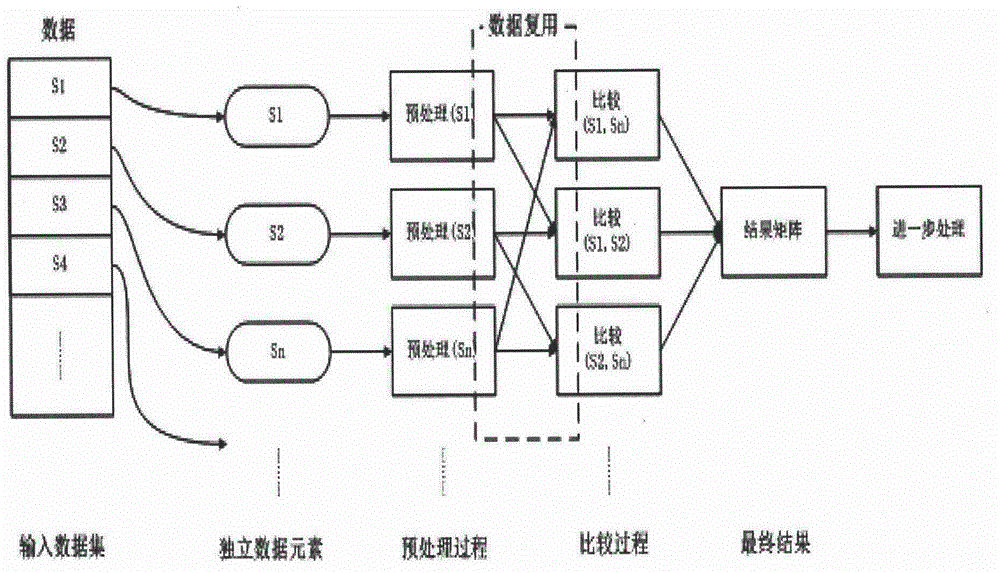
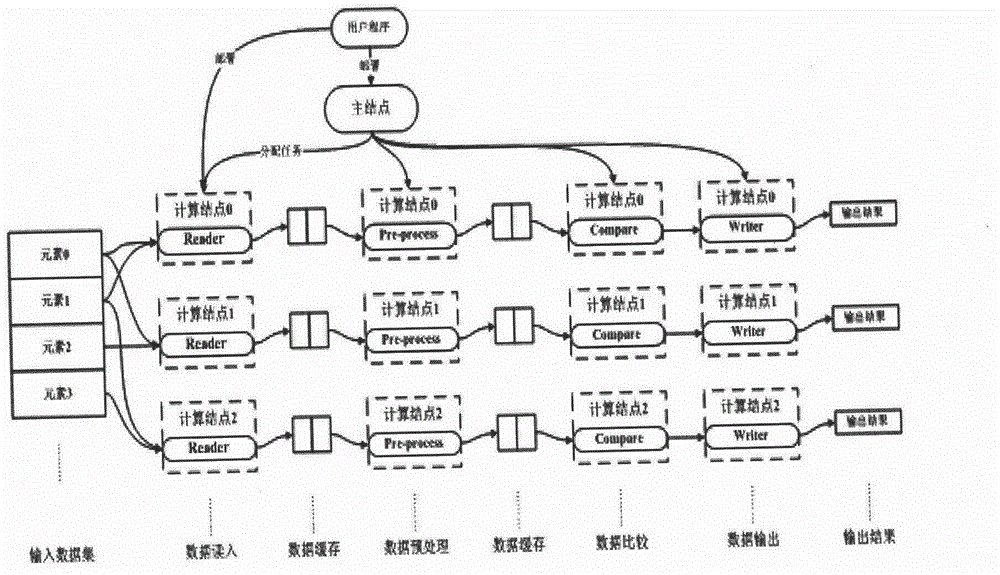
[0062] Such as Figure 3-5 shown.
[0063] A distributed computing system for cross-comparison of large-scale data sets, including a cross-comparison programming model, a master node, a programming interface and a back-end distributed processing framework based on heterogeneous distributed clusters. The distributed computing system aims to apply the distributed computing environment to efficiently process computing problems satisfying the cross-comparison mode of data sets. The invention helps users abstract and simplify the calculation process to be processed by providing an intuitive cross-comparison programming model for users, and realizes unified support for various cross-comparison calculation problems; provides users with a concise programming interface and helps users develop serial cross-computing Comparing programs, users do not need to master parallel programming knowledge; the system hides the implementation details of parallel computing, and users do not need to ...
Embodiment 2
[0077] A method for processing data utilizing a distributed computing system as described in Embodiment 1, comprising steps as follows:
[0078] (1) Users analyze specific calculation problems;
[0079] (2) the user uses the programming interface provided by the distributed computing system of the present invention to realize four independent computing modules respectively: the specific processing methods of the data reading module, the data preprocessing module, the data comparison module and the data output module, Including steps (a)-(d):
[0080] (a) Data read-in stage: at this stage, the sub-data sets required for sub-task execution are read in from the distributed file system, and each input file in the data set is in the distributed computing system of the present invention Store in the form of index A and initial content;
[0081] (b) Data preprocessing stage: at this stage, the data read in in step (1) is preprocessed according to the user-defined processing method,...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com