Vector processor oriented large matrix multiplied vectorization realizing method
A vector processor and matrix technology, applied in the field of vector processors and data processing, can solve problems such as difficulty in obtaining performance, and achieve the effects of easy implementation, improved efficiency, and simple steps
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
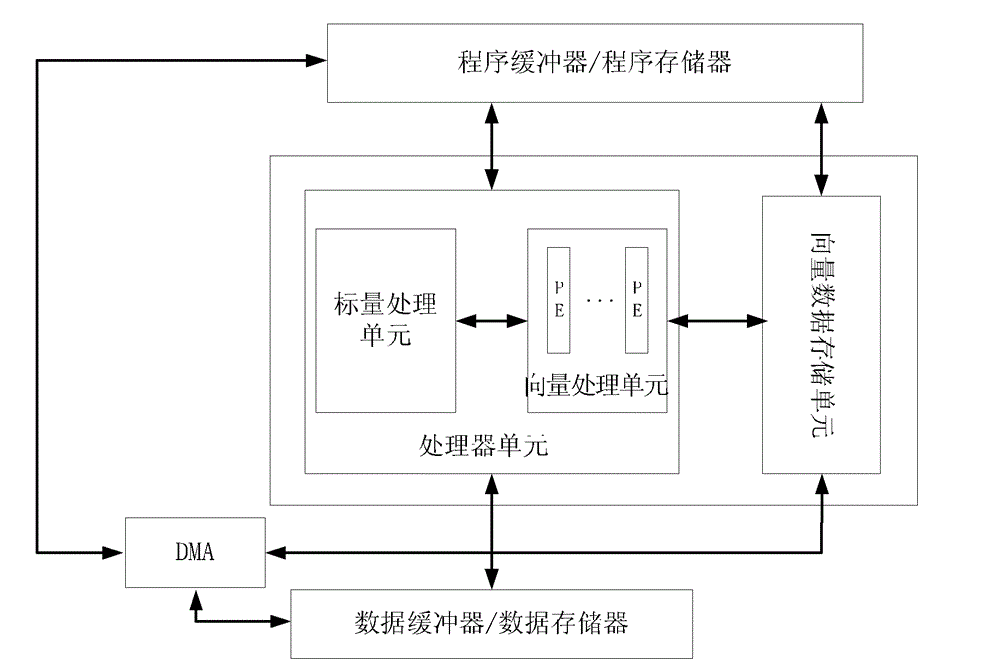
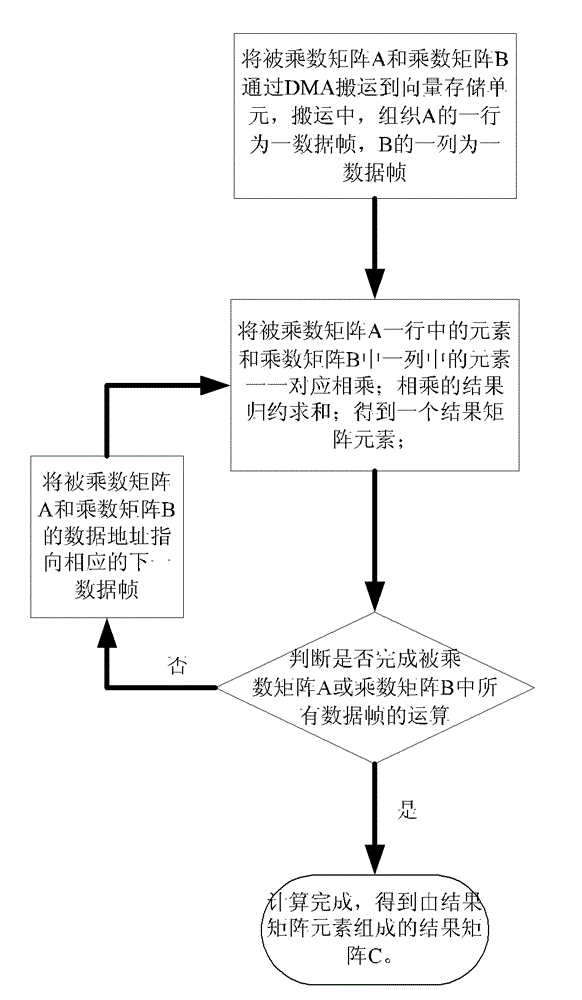
[0027] Such as image 3 Shown, the vectorized realization method of the vector processor-oriented large matrix multiplication of the present invention comprises the following steps:
[0028] 1. Input the multiplicand matrix A and the multiplier matrix B; through the DMA controller, the multiplicand matrix A and the multiplier matrix B are transferred to the vector storage unit respectively. During the transfer process, such as Figure 4 As shown, the multiplier matrix B is reordered, that is, the 1st to nth rows in the multiplier matrix B are sequentially sorted into the 1st to nth columns.
[0029] Through the configuration of the DMA controller, each row of the multiplicand matrix A can be organized into a data frame, each column of the multiplier matrix B can be organized into a data frame, and the entire multiplier matrix B can be divided into p data frames. When the number of elements in the data frame is not equal to the multiple of the number K of parallel processing u...
Embodiment 2
[0034] Such as Figure 7 Shown, adopt the vectorization realization method of the vector processor-oriented large matrix multiplication of the present invention, the calculation scale is that the matrix of 16 * 16 is multiplied by the matrix of 16 * 16 (the vector processing unit number K is 8), Include the following steps:
[0035] 1. If Figure 6 As shown, input the multiplicand matrix A (16×16) and the multiplier matrix B (16×16); the multiplicand matrix A and the multiplier matrix B are transferred to the vector storage unit through DMA, and the multiplier matrix is realized in this process The reordering of B (the reordering method is the same as in embodiment 1), the storage mode of the multiplicand matrix A and the multiplier matrix B in the vector unit is as follows Figure 5 (1) and Figure 5 (2) shown.
[0036]2. Load the elements of one row of the multiplicand matrix A and the elements of one column of the multiplier matrix B into the vector processing unit. S...
Embodiment 3
[0041] Such as Figure 10 As shown, the vectorized implementation method of vector processor-oriented multiplication of large matrices of the present invention, the calculation scale is 26 * 22 matrix multiplied by the scale of 22 * 27 matrix (the vector processing unit number K is 8), including The following steps:
[0042] 1. If Figure 9 As shown, the multiplicand matrix A and the multiplier matrix B are transferred to the vector storage unit by DMA, and the reordering of the multiplier matrix B is realized in this process (the reordering method is the same as that in Embodiment 1), and the multiplicand matrix A and multiplier matrix B are complemented with 0, and the storage method of multiplicand matrix A and multiplier matrix B in the vector unit is as follows Figure 8 (1) and Figure 8 (2).
[0043] 2. Load the elements of one row of the multiplicand matrix A and the elements of one column of the multiplier matrix B into the vector processing unit. Here, the rows...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com