Method for recognizing speaker based on conversion of neutral and affection sound-groove model
A speaker recognition and model conversion technology, applied in speech recognition, speech analysis, instruments, etc., can solve problems affecting system recognition performance and achieve the effect of improving recognition rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

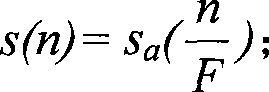
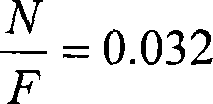
Examples
Embodiment Construction
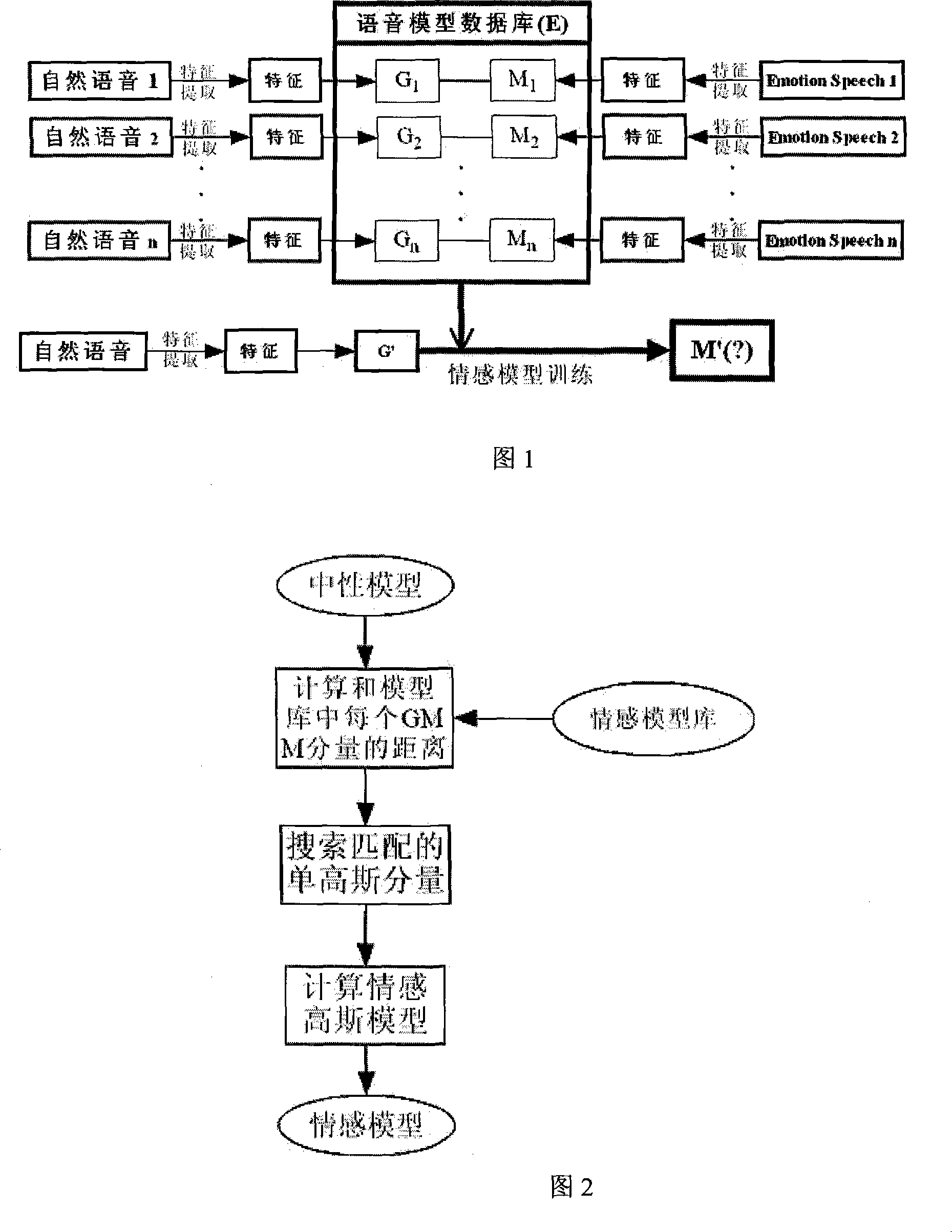
[0011] The present invention will be further introduced below in conjunction with accompanying drawing and embodiment: the method of the present invention is divided into three steps altogether.
[0012] The first step feature extraction
[0013] I. Audio preprocessing
[0014] Audio preprocessing is divided into three parts: sampling quantization, zero drift removal, pre-emphasis and windowing.
[0015] A), sampling quantization
[0016] Filter the audio signal with a sharp cut-off filter so that its Nyquist frequency FN is 4KHZ;
[0017] Set the audio sampling rate F=2FN; the audio signal sa(t) is sampled periodically to obtain the amplitude sequence of the digital audio signal s ( n ) = sa ( n F ) ;
[0018] Quantize and code s(n) with pulse code modulation (PCM) to obtain the quantized representation...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com