Video flow based three-dimensional dynamic human face expression model construction method
A facial expression, three-dimensional dynamic technology, which is applied in the intersection of computer vision and computer graphics, can solve the problems that corner detection and matching are not robust enough, the constraints are too strict, and it is difficult to accurately reflect the local features of the face.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
[0091] Examples of modeling angry expressions:
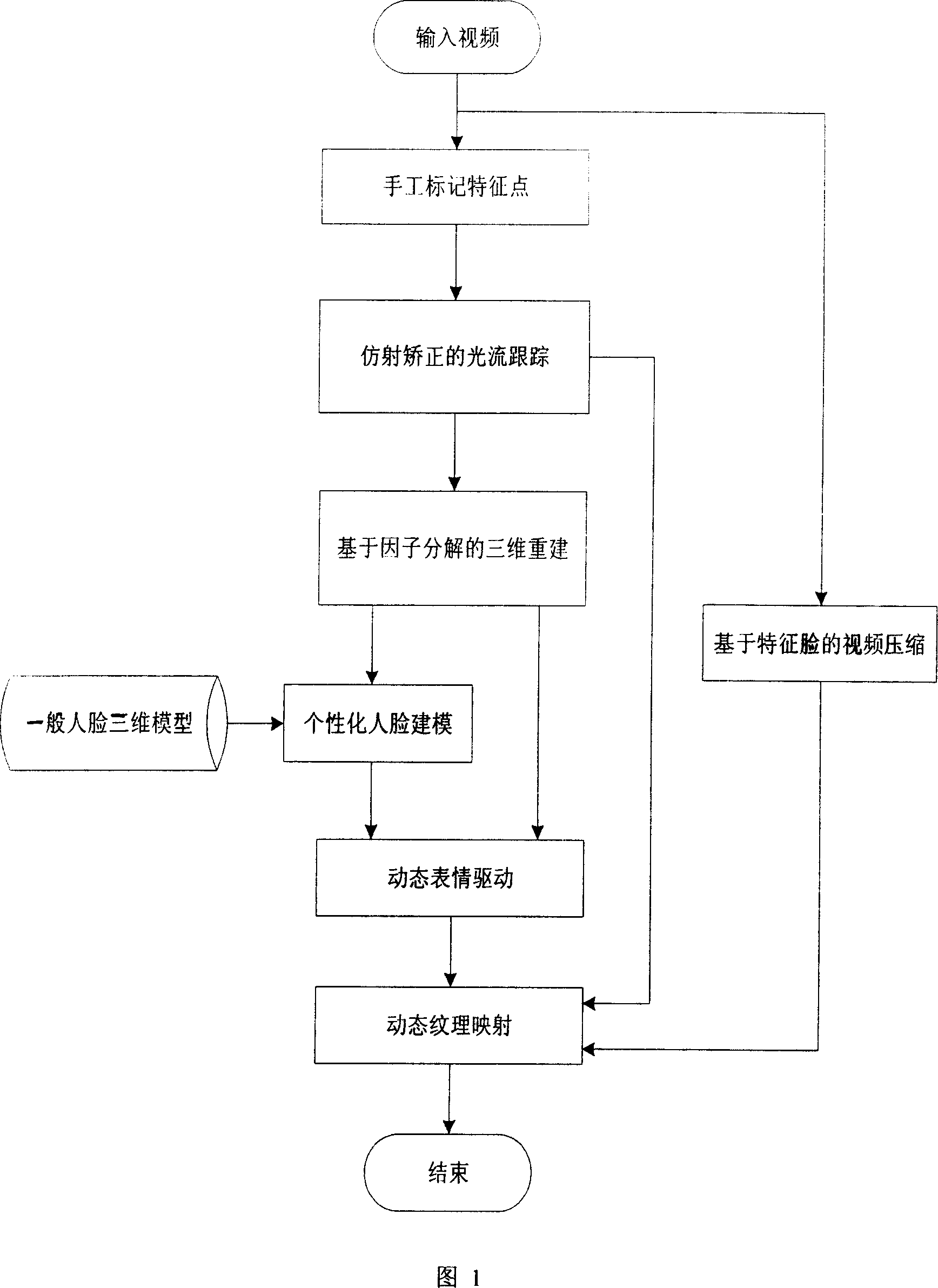
[0092] Step 1: The input video has 100 frames, and 40 pre-defined feature points are marked on the first frame of the uncalibrated monocular video, as shown in Figure 2;
[0093] Step 2: Use the optical flow method of affine correction to robustly track the feature points, use the 8 feature points of the corners of the mouth on both sides, the inner and outer corners of the eyes, and the temples on both sides to calculate the affine transformation between two frames, and use This affine transformation is used to optimize the optical flow tracking results of the remaining 32 feature points;
[0094] Step 3: Using factorization-based algorithms to restore the three-dimensional coordinates of feature points and deform general faces to obtain personalized face models and expression effects;
[0095] Step 4: Use the average value of the coordinates of the three-dimensional feature points in the first three frames as the three-dimens...
Embodiment 2
[0101] Example of modeling a surprised expression:
[0102] Step 1: The input video has 80 frames, and 40 pre-defined feature points are marked on the first frame of the uncalibrated monocular video;
[0103] Step 2: Use the optical flow method of affine distance correction to track the feature points robustly, and use the 8 feature points of the corners of the mouth on both sides, the inner and outer corners of the eyes, and the temples on both sides to calculate the affine transformation between the two frames. Use this affine transformation to optimize the optical flow tracking results of the remaining 32 feature points;
[0104] Step 3: Using factorization-based algorithms to restore the three-dimensional coordinates of feature points and deform general faces to obtain personalized face models and expression effects;
[0105] Step 4: Use the average value of the coordinates of the three-dimensional feature points in the first three frames as the three-dimensional feature ...
Embodiment 3
[0111] Examples of modeling fear expressions:
[0112] Step 1: The input video has 100 frames, and 40 pre-defined feature points are marked on the first frame of the uncalibrated monocular video;
[0113] Step 2: Use the optical flow method of affine correction to robustly track the feature points, use the 8 feature points of the corners of the mouth on both sides, the inner and outer corners of the eyes, and the temples on both sides to calculate the affine transformation between two frames, and use This affine transformation is used to optimize the optical flow tracking results of the remaining 32 feature points;
[0114] Step 3: Using factorization-based algorithms to restore the three-dimensional coordinates of feature points and deform general faces to obtain personalized face models and expression effects;
[0115] Step 4: Use the average value of the coordinates of the three-dimensional feature points in the first three frames as the three-dimensional feature points de...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com