High-efficiency and high-precision network data capturing method and device
A technology of network data and crawling device, which is applied in network data indexing, network data retrieval, other database retrieval and other directions, can solve the problems of inability to achieve high-efficiency and high-precision network data capture, poor scalability, and low performance.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
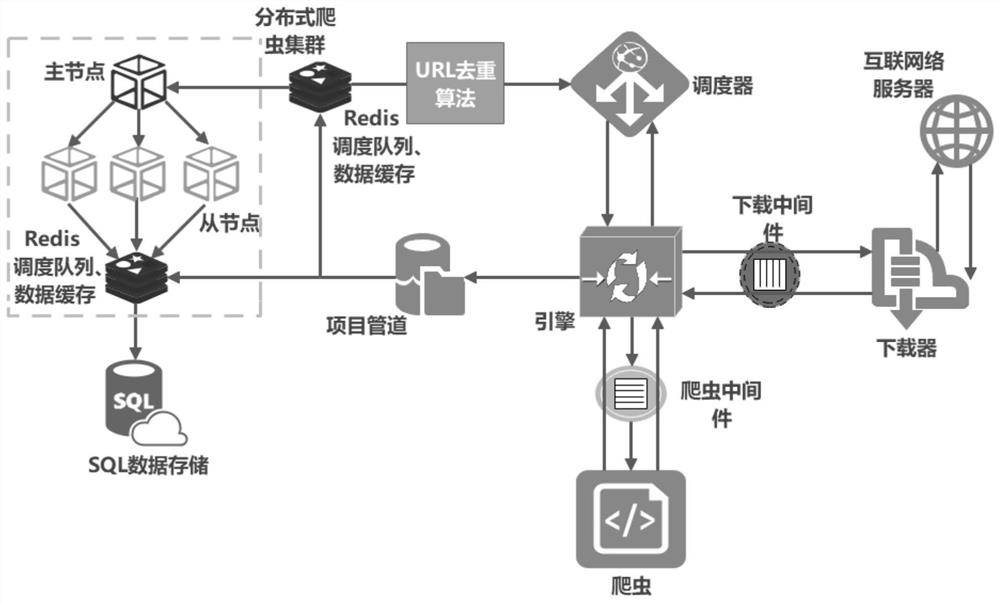
[0046] The embodiment of the present invention provides a high-efficiency and high-precision network data capture method, see figure 1 , the method includes the following steps:
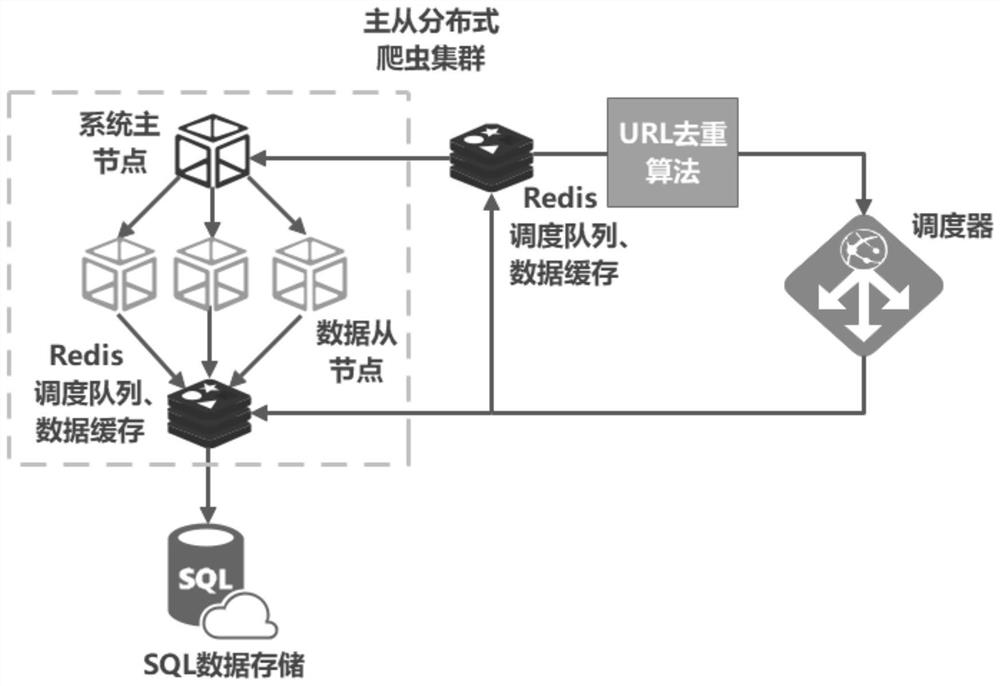
[0047] Step 101: Using the Scrapy crawler framework, based on the master-slave distributed structure of Redis cluster scheduling and data caching, by rewriting the scheduler and crawler class, the scheduler can obtain the deduplicated URL from the Redis scheduling queue, and the completion Data interaction between the scheduler and Redis; realizes that the data captured by the crawler class can pass through the project pipeline class smoothly, and after passing through the project pipeline class, the captured data can be cached in the Redis database, and the crawler class and the The indirect interaction between Redis builds a new deduplication class based on Scrapy-Redis master-slave distributed crawler;
[0048] The Scrapy crawler framework is a set of components based on the Redis database and ru...
Embodiment 2
[0062] The scheme in Embodiment 1 is further introduced below in conjunction with specific calculation formulas and examples, and is described in detail below:
[0063] Step 201: In order to efficiently obtain network data information, the Scrapy framework and the Redis database are interacted with each other, and by rewriting the scheduler and the crawler class, the interaction between the scheduler, the crawler class, the project pipeline class and Redis is realized, and the construction Create a new deduplication class;
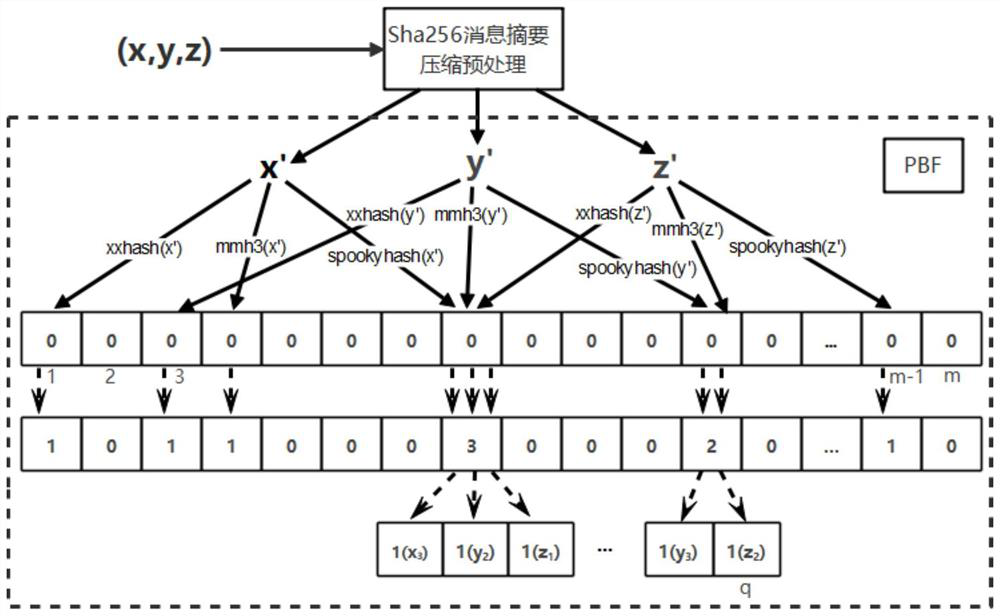
[0064] Among them, in the new deduplication class, the scheduler judges a crawler request URL by accessing the Redis database, and if it is not repeated, it will be added to the queue to be crawled in the Redis database. When the scheduler receives a request for obtaining a URL from the engine, the scheduling conditions have been met at this time, and the scheduler will perform the encapsulation operation of the engine and the resource download operation o...
Embodiment 3
[0097] A high-efficiency and high-precision network data capture device, see figure 1 , the device includes: Scrapy engine (engine), Scheduler (scheduler), Downloader (downloader), Spider (crawler), Item Pipline (pipeline), Downloader Middlewares (download middleware), Spider Middlewares (crawler middleware) and Master-slave distributed crawler cluster.
[0098] The crawler initiates a crawler request to the engine through the crawler middleware to request the first URL to be crawled. After the engine receives the crawler request, it requests the scheduler to obtain the URL. In the new deduplication class, the scheduler determines the weight of a crawler request URL by accessing the Redis database. Through an efficient URL deduplication algorithm, a large number of URLs are effectively deduplicated, and the deduplicated results are added to the scheduler queue in the Redis database. The scheduler gets the deduplicated URL from the Redis scheduling queue and returns it to the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com