Speaker segmentation model optimization method, speaker segmentation method and speaker segmentation device
A technology of segmentation model and optimization method, applied in neural learning method, design optimization/simulation, biological neural network model, etc. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
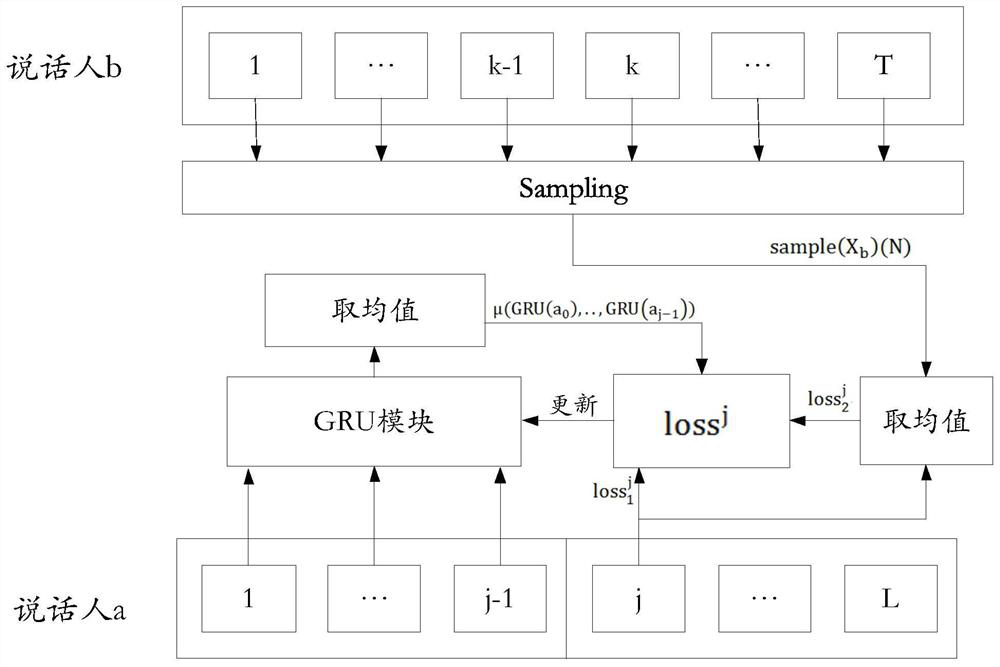
[0088] This embodiment provides an optimization method for a speaker segmentation model, which is applied to a UIS-RNN system and used for optimizing a GRU (Gated Recurrent Unit, gated recurrent unit) model in the UIS-RNN system.
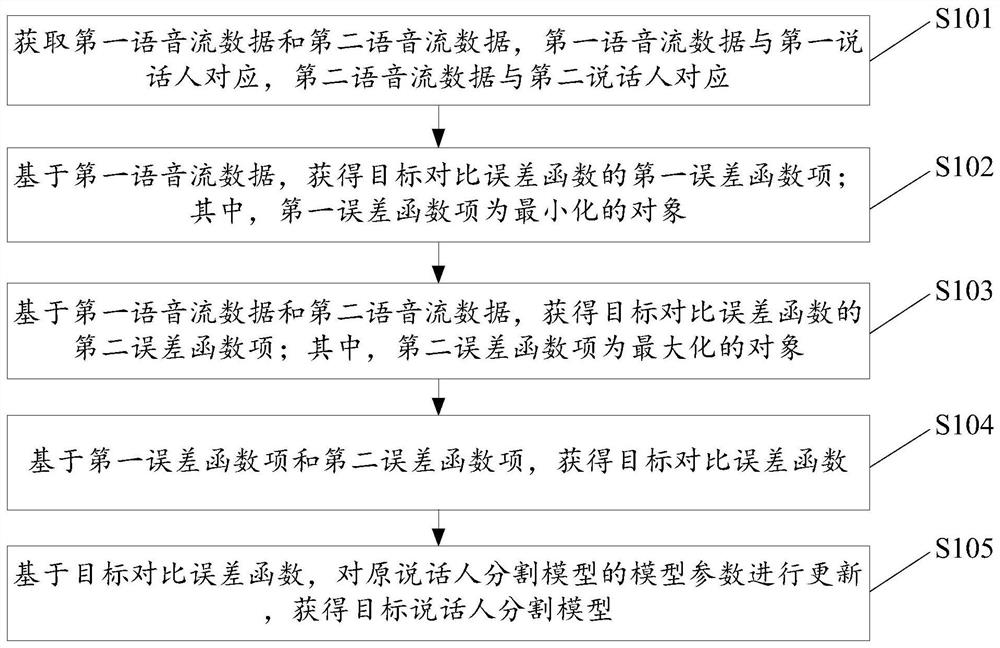
[0089] like figure 1 As shown, the optimization method of the speaker segmentation model (taking one update of GRU parameters as an example) includes:
[0090] Step S101: Acquire first voice stream data and second voice stream data, where the first voice stream data corresponds to the first speaker, and the second voice stream data corresponds to the second speaker.
[0091] In a specific implementation process, the voice stream data of at least two different speakers can be collected in real time.
[0092] For example, if the first speaker is speaker a and the second speaker is speaker b, the first voice stream data of speaker a and the second voice stream data of speaker b can be collected in real time.
[0093] Step S102: Based on the first voi...
Embodiment 2
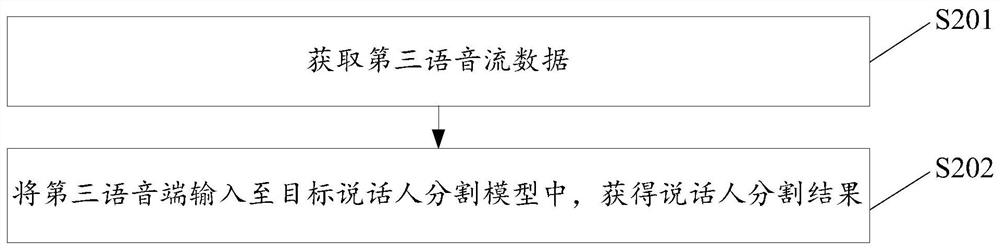
[0146] Based on the same inventive concept, this embodiment provides a speaker segmentation method, such as image 3 shown, including:
[0147]Step S201: acquiring third voice stream data;
[0148] Step S202: Input the third voice terminal into the target speaker segmentation model to obtain a speaker segmentation result. Wherein, the target speaker segmentation model is obtained based on any implementation in the first embodiment.
[0149] In the specific implementation process, the third voice stream data may be the voice stream data collected in real time. After the third voice stream data is input into the target speaker segmentation model, the target speaker segmentation model can identify the third voice stream data. The identities of different speakers in the device are divided, and the third speech data is segmented based on the identities of the different speakers to obtain speech segment data corresponding to each speaker.
[0150] The technical solutions in the a...
Embodiment 3
[0153] Based on the same inventive concept, this embodiment provides an optimization device for a speaker segmentation model, such as Figure 4 shown, including:
[0154] a first acquiring unit 301, configured to acquire first voice stream data and second voice stream data, where the first voice stream data corresponds to the first speaker, and the second voice stream data corresponds to the second speaker;
[0155] a first obtaining unit 302, configured to obtain a first error function item of a target contrast error function based on the first voice stream data; wherein, the first error function item is an object to be minimized;
[0156] A second obtaining unit 303, configured to obtain a second error function term of the target contrast error function based on the first voice stream data and the second voice stream data; wherein the second error function term is the largest object;
[0157] a third obtaining unit 304, configured to obtain the target contrast error functi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com