


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Query method and system for large-scale time sequence RDF graph data
A query method and graph data technology, applied in the query field of knowledge graphs, can solve problems that cannot be satisfied at the same time, and achieve the effect of improving efficiency and strong compatibility
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
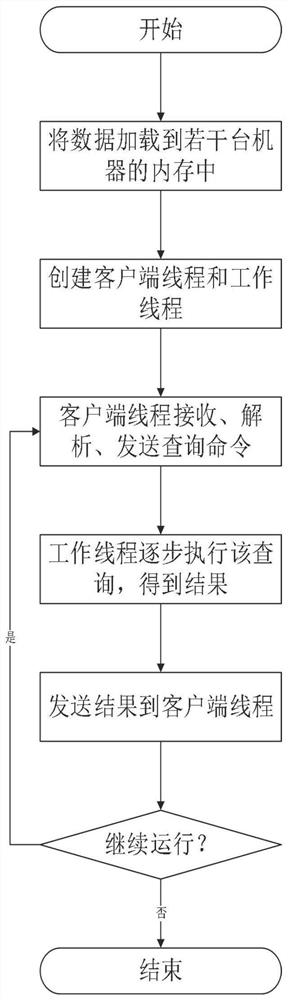
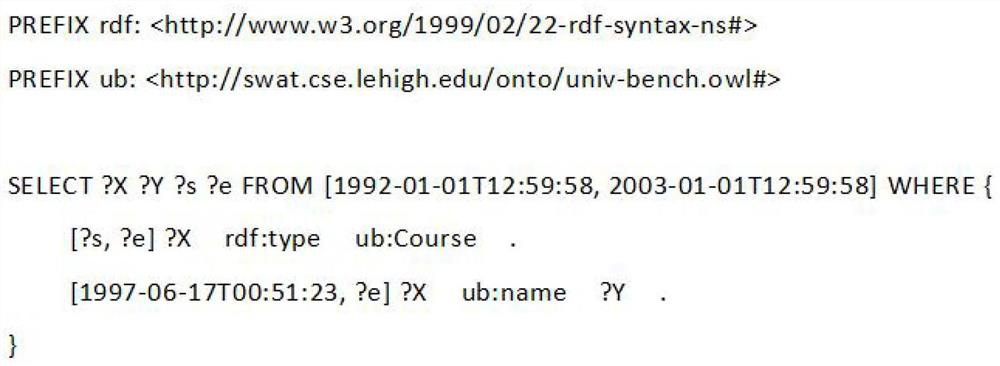
[0051] According to a query method for large-scale time-series RDF graph data provided by the present invention, such as Figure 1-2 shown, including:
[0052] Step S1: Uniformly load and store the time-series RDF graph data in quintuple format into the memory of multiple machines by means of key-value storage;
[0053] Step S2: After completing the storage of graph data, create several client threads and several worker threads on each machine;
[0054] Step S3: The client thread receives the user's query request, parses the user's query request, uses its built-in query language parser to convert it into a form that the worker thread can understand, and sends the parsed query request to the corresponding machine's work thread;
[0055] Step S4: The worker thread executes the query task based on the parsed query request to obtain the final query result;
[0056] Step S5: The working thread returns the query result to the client thread.
[0057] Specifically, the time-series...
Embodiment 2
[0090] Embodiment 2 is a preferred example of embodiment 1
[0091] The invention provides a query method for large-scale time-series RDF graph data, and completes the query of large-scale time-series RDF graphs. Let's take 8 machines as an example, combined with figure 1 Describe the following steps in detail:
[0092] In step 1, the system starts and starts to load time-series RDF graph data files in quintuple format from a specific directory in the file system (configured by the user in the configuration file). The first three elements of the five-tuple are the IDs obtained by converting the subject, predicate, and object respectively, representing an edge of the graph; the last two elements are two starting times that represent the validity period of the edge and deadline timestamps; and two text files that store the mapping between strings and IDs. In the end, the system distributes and evenly stores the data in the memory of 8 machines;
[0093] In step 2, the system...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com