Data clustering method and system, computer equipment and storage medium
A data clustering and computer program technology, applied in the field of data clustering, can solve problems such as increasing the number of K-split algorithm splits, decreasing clustering speed and efficiency, and difficult to determine the K value.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

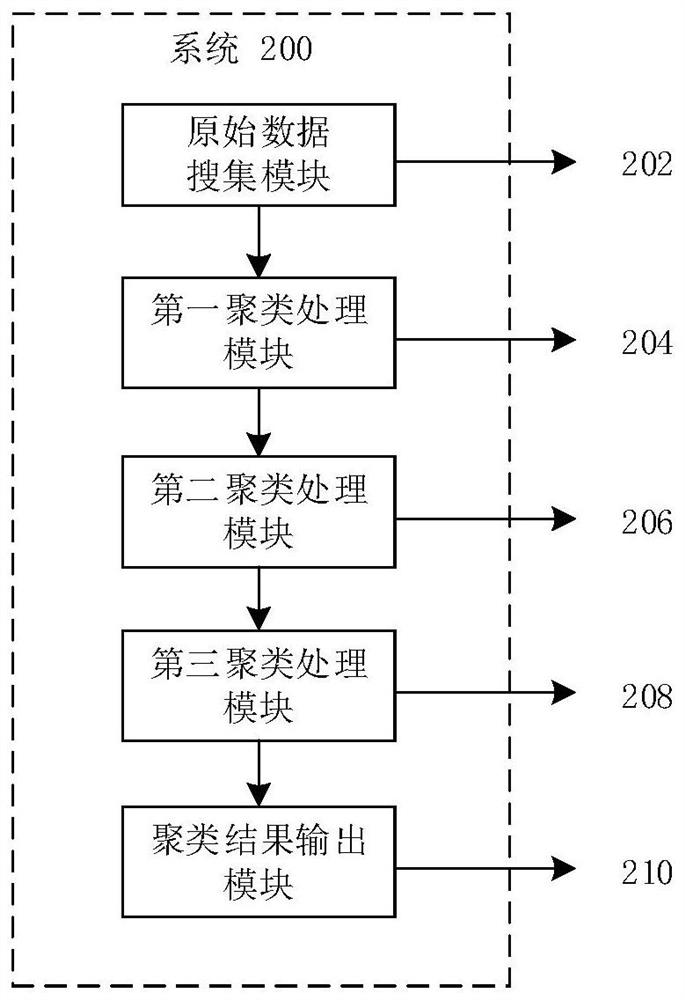
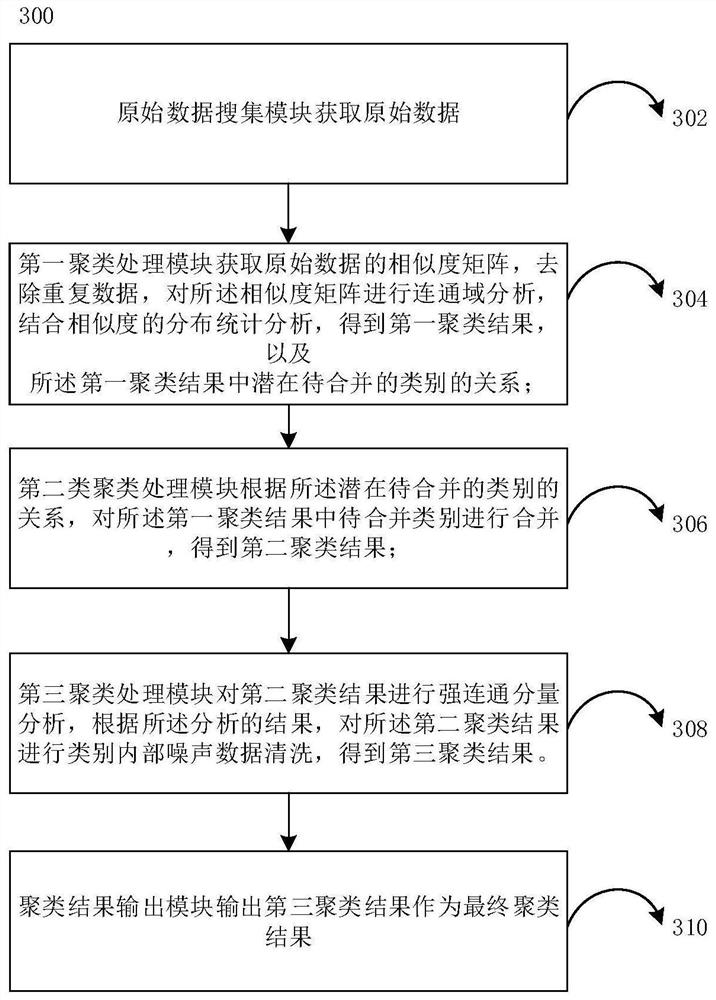
Examples
Embodiment Construction
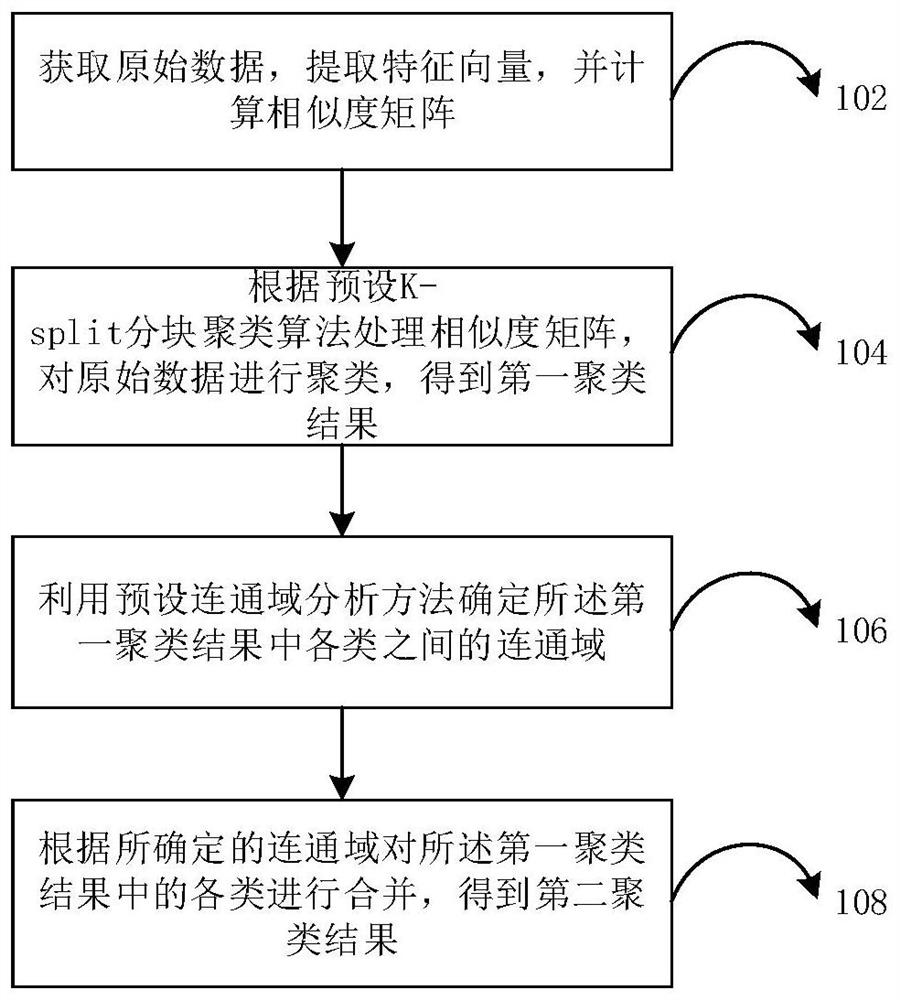
[0046] In the field of artificial intelligence, training or adjusting a model requires collecting and processing a large amount of data, but in some specific scenarios, there is no public and complete data set that can be used to train or adjust a model, such as a face recognition system at an intersection, there is A Groups of people will pass through this intersection regularly to form a fixed face data set. At the same time, a new group of people B will pass by the intersection. The face data of group B is new data for the face recognition system at this intersection. Without being recognized by the system, this new group of people will appear every day. Therefore, the system often can only collect and process by itself and obtain corresponding data sets, but this process will consume a lot of time and resources, which greatly limits the actual scenarios of deep learning applications.
[0047] Aiming at this problem, a feasible existing technology such as figure 1 shown. ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com