End-to-end speech synthesis network based on embedded system
An embedded system and speech synthesis technology, applied in speech synthesis, speech analysis, instruments, etc., can solve the problem that the reasoning speed is not real-time, and achieve the effect of increasing the reasoning speed and reducing the calculation amount of parameters and models
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

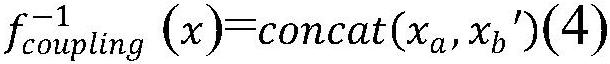
Examples
Embodiment Construction
[0017] The specific implementation manners of the present invention will be further described below in conjunction with the accompanying drawings and technical solutions.
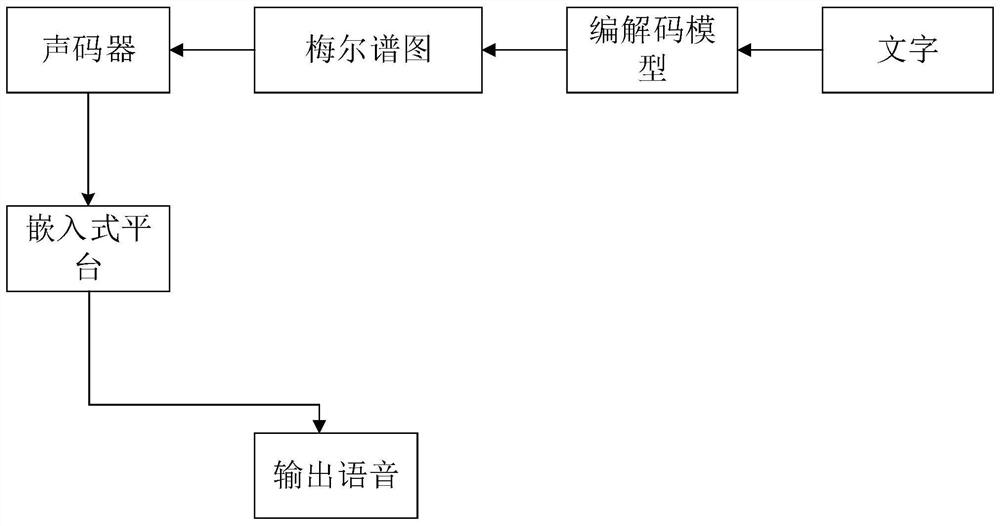
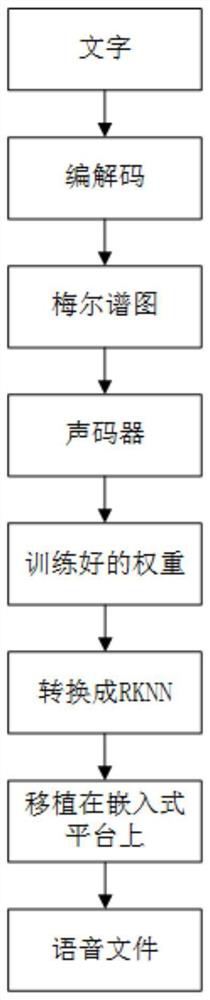
[0018] combine figure 1 , to synthesize speech, mainly including the following steps:
[0019] Step 1: Convert the text into a mel-spectrogram through the codec structure.
[0020] Step 2: Input a continuous sequence, first go through K 1-D convolutions in fastspeech, these convolution kernels can effectively model the current and context information. Convolutional inputs are stacked together, max-pooled along the time axis to increase invariance to current information, and then input to several fixed-bandwidth 1-D convolutions that add outputs to the starting input sequence. All convolutions use Batch Normalization. Enter a multi-layer highway network to extract higher-level features. Finally, a bidirectional GRU is added at the top to extract the contextual features of the sequence. The spectrogram i...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com