Method and system for extracting process information in steel material patent text based on improved TextRank algorithm
A technology of process information and text, applied in the field of steel material knowledge map, can solve the problems of many professional terms, ignoring the position of text structure and semantic information, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
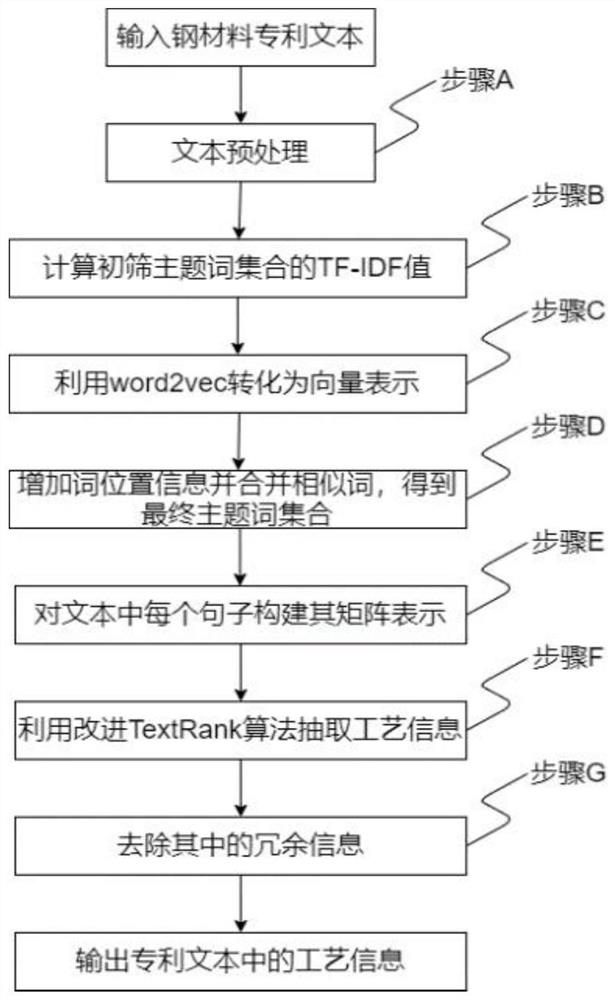
[0069] In this example, see figure 1 , a method for extracting process information in steel material patent texts based on the improved TextRank algorithm, including the following steps:
[0070] Step A: Preprocessing the text of steel material process patent documents, mainly including word segmentation, removing stop words and part-of-speech tagging, to obtain the initially screened subject heading set w={w 1 ,w 2 ,...w n};
[0071] Step B: Calculate the TF*IDF value of each word in the subject word set; first calculate the word frequency TF value, and count the number of times the related words in the w set appear in the text; then calculate the inverse document frequency IDF value; where TF represents the subject word The frequency value of each word in the collection, where IDF represents the inverse text frequency value, which is obtained by dividing the total number of texts by the number of texts containing the word, and then taking the logarithm to the base 10 of t...
Embodiment 2
[0080] This embodiment is basically the same as Embodiment 1, especially in that:
[0081] In this example, see figure 1 ,
[0082] In an optional embodiment of the present invention, after the above-mentioned step A obtains the input text, the preprocessing step is specifically:
[0083] Step A1: The word segmentation uses jieba, a Chinese word segmentation tool with good effect, to segment the characters contained in the text;
[0084] Step A2: Summarize the stop vocabulary list according to the characteristics of the process text in the field of steel materials, and use the built stop vocabulary list to remove useless words in the process text. These words are mainly prepositions, particles, and conjunctions;
[0085] Step A3: Use the jieba toolkit to perform part-of-speech tagging on the craft text, remove all non-nouns in the text, and obtain the craft text subject heading set w={w 1 ,w 2 ,...w n};
[0086] Step B is specifically as follows: first calculate the word...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com