Cross-modal person re-identification method based on dual attribute information
A technology of person re-identification and attribute information, applied in the field of computer vision and deep learning, can solve the problems of insufficient consideration and neglect, and achieve the effect of sufficient application and improved semantic expression.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
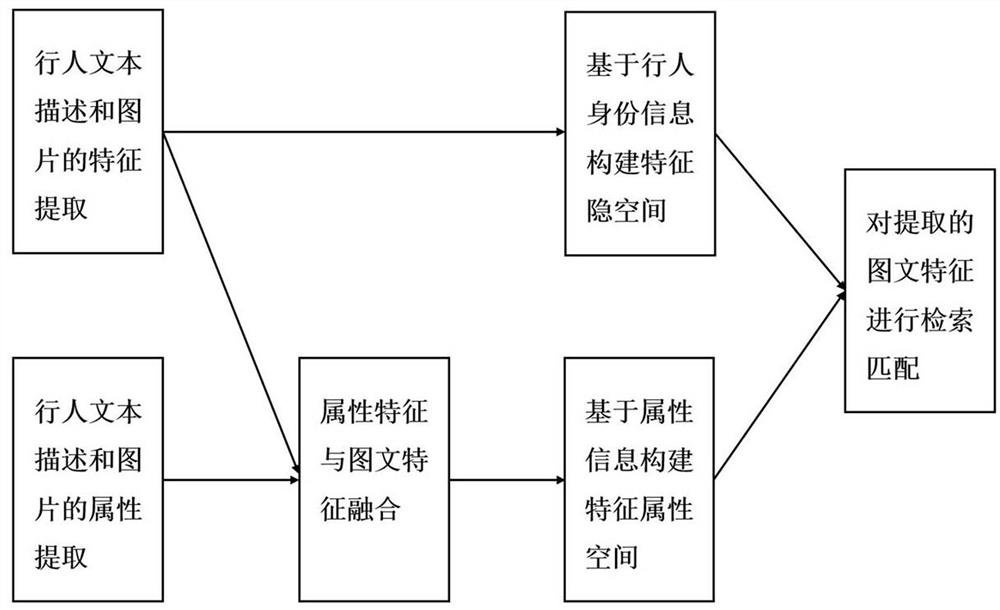
[0055] Extracting the pedestrian text description in step a) includes the following steps:
[0056] a-1.1) The present invention preprocesses the text information when extracting features from the pedestrian text, that is, establishes a word frequency table after segmenting the description sentences of the content captured by the surveillance camera.
[0057] a-1.2) Filter out low-frequency words in the word frequency table.
[0058] a-1.3) The words in the word frequency table are encoded using one-hot encoding.
[0059] a-1.4) Use bidirectional LSTM model for feature extraction of pedestrian textual descriptions. The bidirectional LSTM model can fully consider the context of each word, making the learned text features richer.
[0060] Extracting pictures in step a) includes the following steps:
[0061] a-2.1) Use the ResNet network pre-trained on the ImageNet dataset for image feature extraction;
[0062] a-2.2) Perform semantic segmentation on the extracted pictures, a...
Embodiment 2
[0064] A lot of work has been done on the attribute recognition of pedestrian pictures, and good results have been achieved. The present invention selects and uses a relatively stable pedestrian attribute recognition model, and extracts the attributes and possibility values contained in the pedestrian pictures in the data set. Step b) The extraction steps are as follows:
[0065] b-1) Use the NLTK tool library to preprocess the data of pedestrian text descriptions, and extract noun phrases in two formats: adjective plus noun, and multiple nouns superimposed;
[0066] b-2) Sort the extracted noun phrases according to word frequency, discard the low-frequency phrases, keep the top 400 noun phrases to form an attribute table, and obtain the text attribute c T ;
[0067] b-3) Use the PA-100K data set to train the pictures to obtain 26 kinds of predicted values, mark the attributes of the pictures with the predicted value greater than 0 as 1, and mark the attributes of the pictu...
Embodiment 3
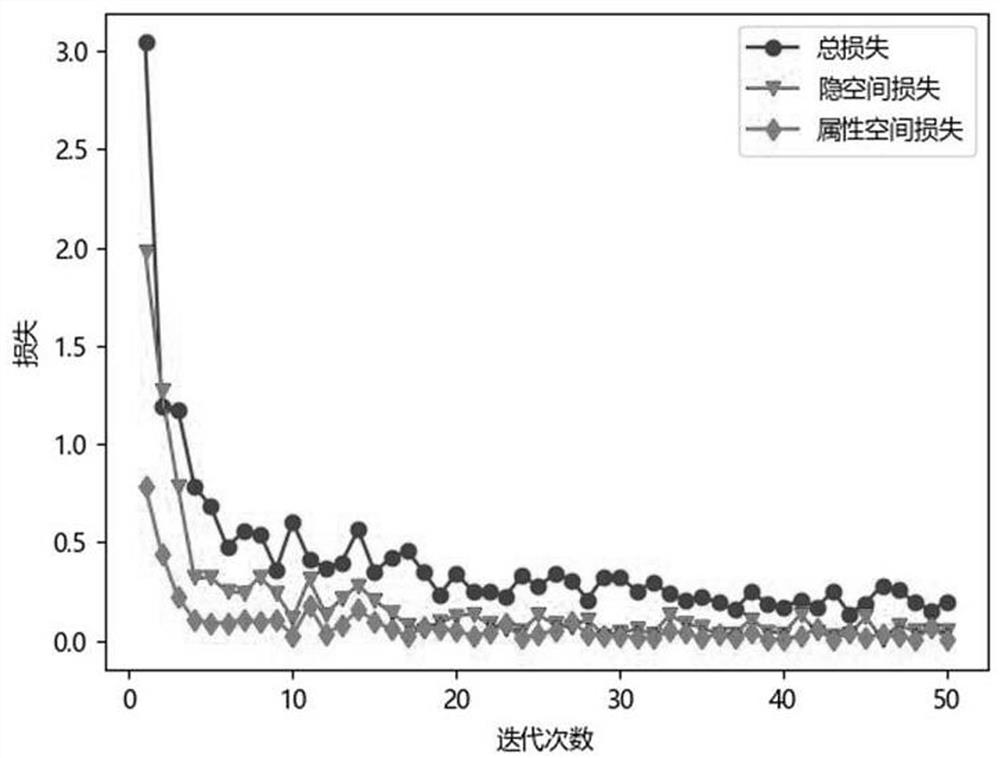
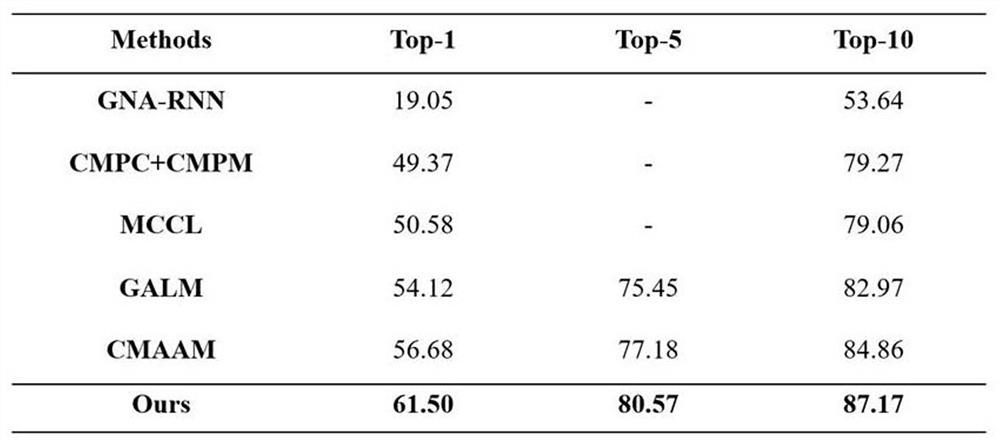
[0069] The present invention uses the shared subspace method commonly used in the field of cross-modal pedestrian re-identification to establish the association between the feature vectors of the two modalities. The setting of the latent space is to make the image features and text features of pedestrians have pedestrian id There is a basic semantic relationship between separability and graphic features. The present invention considers that in cross-modal pedestrian image-text retrieval, the same pedestrian id corresponds to multiple pictures and multiple corresponding text descriptions, so the design goal of the loss function is to shorten the pictures and text descriptions belonging to the same pedestrian id distance between pictures and texts that do not belong to the same pedestrian id. Specifically, let the data in one of the modalities serve as anchors, take the data belonging to the same class as the anchor in the other modality as positive samples, and take the data be...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com